Java知识点
1、JVM
1.1、Java跨平台原理
- Java源文件编译成
.class字节码文件 .class文件被JVM的解释器译成不同操作系统的机器码- 不同系统的解释器不同,但基于解释器实现的虚拟机是相同的
- 机器码调用相应操作系统的本地方法库执行相应的方法
1.2、JVM组成
- 类加载器子系统(加载
.class到JVM中) - 运行时数据区
- 执行引擎
- 本地接口库(通过调用本地方法库与操作系统交互)
1.3、多线程的概念
- JVM中的线程与操作系统中的线程是相互对应的
- 在JVM线程初始化工作完成后会调用操作系统的接口创建一个与之对应的原生线程
- 二原生线程初始化完毕之后会调用线程的
run()方法
1.4、JVM后台线程
- 虚拟机线程(JVM Thread):在JVM到达安全点(safe Point)时出现
- 周期性任务线程:通过定时器调度线程来实现
- GC线程:支持JVM不同的垃圾回收活动
- 编译器线程:在运行时将字节码动态编译成本地平台机器码,是JVM跨平台的具体实现
- 信号分发线程:接收发送到JVM的信号并调用JVM方法
1.5、JVM的内存区域
线程私有区域(与线程共存)
- 程序计数器
- 虚拟机栈
- 本地方法区
线程共享区域(与虚拟机共存)
- 方法区
- 堆
直接内存(也叫堆外内存)
1.6、程序计数器
- 用于存储当前运行的线程所执行的字节码的行号指示器
- 线程私有,无内存溢出问题
1.7、虚拟机栈
为执行java方法服务
- 线程私有,用来记录方法的执行过程
- 在方法被执行时虚拟机会为器创建一个与之对应的栈帧,方法的执行和返回对应栈帧在虚拟机栈中的入栈和出栈
1.8、本地方法区
为本地Native方法服务
- 线程私有,用来记录方法的执行过程
- 与虚拟机栈的作用类似
1.9、堆(运行时数据区)
堆包括:新生代(1/3)、老年代(2/3)、永久代(非常少)
- 线程共享
- 存储JVM运行过程中创建的对象和产生的数据
- 时垃圾收集器进行垃圾回收的主要的内存区域
1.10、方法区(永久代)
方法区包括:常量、静态常量、类信息(版本、字段、方法、接口描述)、即时编译后的代码(机器码)、运行时常量池(常量、代码内容)
- 线程共享
- 用于存储常量、静态常量、类信息、即时编译后的机器码、运行时常量池等数据
- 永久代的内存回收主要针对常量池的回收和类的卸载,因此可回收的对象很少
1.11、垃圾回收
新生代
包括Eden区、Survivor区 和 SurvivorFrom区
实现过程:MinorGC(频繁触发)
- Java新创建的对象存放在Eden区(如果输入大对象[2KB~128KB]则存入老年代)
- 在Eden区的内存空间不足时出发MinorGC堆新生代进行垃圾回收
- 将Eden区和SurvivorFrom区中的幸存者存放到SurvivorTo区,进行年龄判断
- 清空Eden区 和 SurvivorFrom区,并将SurvivorTo区和SurvivorFrom区进行互换,作为这一次的MinorGC的被扫描者
采用算法:复制算法
老年代
主要存放长生命周期的对象和大对象
特点:稳定,MajorGC 不会被频繁出发,耗时较长
触发:在Java新创建的为大对象 或者 MinorGC 过后出现老年代空间不足或无法分配足够大的连续内存空间给新创建的大对象时,触发MajorGC进行垃圾回收
算法:标记清除算法(耗时长,容易产生内存碎片)
永久代
作用:存放class 和 Meta(元数据)的信息,GC不会对其进行清理,故永久代的内存会随着加载的 class 文件的增加而增加
代替:在Java 8 中,永久代被 元数据区 代替,作用与 永久代 类似,但 元数据区 并没有使用虚拟机的内存,而是直接使用操作系统的本地内存,故元空间的大小不受JVM内存的限制。
1.12、垃圾的确定
- 引用计数法:当技术为0时说明可回收
- 可达性分析:两次不可达则回收
- 栈中引用
- 方法区中的静态引用
- JNI 中的引用
1.13、垃圾回收算法
- 标记清除算法:效率低,碎片多
- 复制算法(MinorGC)
- 标记整理算法
- 分代收集算法(根据不同类型将内存划分,分为新生代,老年代,永久代)
1.14、4种引用类型
- 强引用:不会被回收
- 软引用:空间不足时回收
- 弱引用:一定会回收
- 虚引用:用于跟踪回收状态
1.15、分区收集算法
- 将整个堆空间划分为连续的大小不同的小区域
- 在每个小区域内单独进行内存使用和垃圾回收
1.16、什么是JVM?什么是JDK?什么是JRE?
JVM
JVM是Java Virtual Machine(Java虚拟机)的缩写,它是整个Java实现跨平台的最核心的部分。
所有的java程序会首先被编译为.class的类文件,这种类文件可以在虚拟机上执行,也就是说class并不直接与机器的操作系统相对应,而是经过虚拟机间接与操作系统交互,由虚拟机将程序解释给本地系统执行。
JVM是Java平台的基础,和实际的机器一样,它也有自己的指令集,并且在运行时操作不同的内存区域。 JVM通过抽象操作系统和CPU结构,提供了一种与平台无关的代码执行方法,即与特殊的实现方法、主机硬件、主机操作系统无关。JVM的主要工作是解释自己的指令集(即字节码)到CPU的指令集或对应的系统调用,保护用户免被恶意程序骚扰。 JVM对上层的Java源文件是不关心的,它关注的只是由源文件生成的类文件(.class文件)。
JRE
JRE是java runtime environment(java运行环境)的缩写。光有JVM还不能让class文件执行,因为在解释class的时候JVM需要调用解释所需要的类库lib。
在JDK的安装目录里你可以找到jre目录,里面有两个文件夹bin和lib:
在这里可以认为bin里的就是jvm
lib中则是jvm工作所需要的类库,而jvm和lib和起来就称为jre。
所以,在你写完java程序编译成.class之后,你可以把这个.class文件和jre一起打包发给朋友,这样你的朋友就可以运行你写程序了(jre里有运行.class的java.exe)。JRE是Sun公司发布的一个更大的系统,它里面就有一个JVM。JRE就与具体的CPU结构和操作系统有关,是运行Java程序必不可少的(除非用其他一些编译环境编译成.exe可执行文件……),JRE的地位就象一台PC机一样,我们写好的Win32应用程序需要操作系统帮我们运行,同样的,我们编写的Java程序也必须要JRE才能运行。
JDK
JDK是java development kit(java开发工具包)的缩写。每个学java的人都会先在机器上装一个JDK。在目录下面有六个文件夹、一个src类库源码压缩包、和其他几个声明文件。其中,真正在运行java时起作用的是以下四个文件夹:bin、include、lib、jre。现在我们可以看出这样一个关系,JDK包含JRE,而JRE包含JVM。
- bin: 最主要的是编译器(javac.exe)
- include: java和JVM交互用的头文件
- lib:类库
- jre: java运行环境
(注意:这里的bin、lib文件夹和jre里的bin、lib是不同的)
总的来说JDK是用于java程序的开发,而jre则是只能运行class而没有编译的功能。eclipse、idea等其他IDE有自己的编译器而不是用JDK bin目录中自带的,所以在安装时你会发现他们只要求你选jre路径就ok了。
JDK、JRE、JVM三者关系概括如下:
- JDK是JAVA程序开发时用的开发工具包,其内部也有JRE运行环境JRE。
- JRE是JAVA程序运行时需要的运行环境,就是说如果你光是运行JAVA程序而不是去搞开发的话,只安装JRE就能运行已经存在的JAVA程序了。
- JDK、JRE内部都包含JAVA虚拟机JVM,JAVA虚拟机内部包含许多应用程序的类的解释器和类加载器等等。
2、Java并发编程
2.1、创建Java线程的方法
方法
- 继承Thread类
- 实现Runnable接口
- 通过ExecutorService 和 Cllable
实现有返回值的线程 - 基于线程池
继承Thread
// 创建对象
public class NewThread extends Thread {
public void run() {
system.out.println("hello");
}
}
// 使用
public static void main(String[] args) {
NewThread thread = new NewThread();
thread.start();
} 实现Runnable接口
// 创建对象,实现接口
public class newRunnable implements Runnable {
public void run() {
system.out.println("Hello");
}
}
// 使用:1、创建Runnable实现类,2、创建线程Thread
public static void main(String[] args) {
newRunnable runnable = new newRunnable();
Thread thread = new Thread(runnable);
thread.start();
} // 使用匿名方法创建线程
new Thread(new Runnable() {
@Override
public void run() {
system.out.println("匿名方法创建线程");
}
} ).start();实现Callable
接口
public class Callable_Future implements Callable<Integer> {
//重写Callable接口中的call()方法,需要指定返回类型
@Override
public Integer call() throws Exception {
int i = 0;
for(; i<100; i++) {
System.out.println(Thread.currentThread().getName()+" "+i);
}
return i;
}
} 基于线程池创建线程,通过 threadPool.execute(new Runnable())
// 1、创建线程池
ExecutorService threadPool = Executors.newFixedThreadPool(10);
// 2、创建线程
for(int i = 0; i < 10; i++) {
threadPool.execute(new Runnable() {
@Override
public void run() {
system.out.println(Thread.currentThread().getName());
}
} )
} 2.2、线程池的核心
- 线程池管理器:用于创建并管理线程池
- 工作线程:线程池中执行具体任务的线程
- 任务接口:用于定义工作线程的调度和执行策略
- 任务队列:存放待处理的任务
2.3、五种常用的线程池
- newCacheThreadPool:可缓存的线程池
- newFixedThreadPool:固定大小的线程池
- newScheduleThreadPool:可做任务调度的线程池
- newSingleThreadExecutor:单个线程的线程池(保证同时只有一个线程)
- newWorkStealingPool:足够大小的线程池
2.4、定时调度的线程池
// 创建定时线程池
ScheduleExecutorService sheduleThreadPool = new Executors.newScheduleThreadPool(3);
// 创建一个延迟3秒执行的线程
sheduleThreadPool.schedule(new Runnable() {
@Override
public void run() {
system.out.println("delay 3 seconds execute");
}
} , 3, TimeUnit.SECONDS);
// 创建一个延迟1秒且3秒执行一次的线程
sheduleThreadPool.schedule(new Runnable() {
@Override
public void run() {
system.out.println("delay 1 seconds execute");
}
} , 1, 3, TimeUnit.SECONDS);2.6、线程生命周期
五种状态
- 新建(New)
- 就绪(Runnable)
- 运行(Running)
- 阻塞(Bloked)
- 死亡(Dead)
状态转换
2.6、终止线程的方法
四种方法
- 运行结束
- 使用退出标志位
- 使用Interrupt(终止阻塞)
- 使用stop(不安全)
使用退出标志
public class threadSafe extends Thread {
public volatile boolean exit = false;
public void run() {
while(!exit) {
system.out.println("run");
}
}
} 以上使用volatile修饰标志位,因为volatile 变量存放于内存中,每次读取都会返回最新写入的值。
使用Interrupt
注意:
- 使用interrupt 终止的是阻塞,而不是中断一个正在运行的线程,只是用于该表内部维护的中断标志位而已当
- 当线程处于阻塞状态时,通过interrupt() 可以是线程抛出 InterruptException 异常,可以通过该捕获异常,并且安全终止线程
- 可以中断sleep() 和 ReentranLock().lockInterruptibly()
2.7、Java中的锁
- 乐观锁:读不加锁,写时加版本号进行判断,CAS(比较和交换)
- 悲观锁:读写都加锁,AQS(抽象的队列同步器)
2.8、线程的同步
2.9、线程的通信
3、数据结构
3.1、栈(单边操作)
public class Stack<E> {
private Object[] data = null;
private int maxsize = 0;
private int top = -1;
……
} - push():入栈 data[++top]
- pop():出栈 data[top–]
- peek():返回栈顶元素
3.2、队列(单向操作,左进右出)
public class Queue<E> {
private Object[] data = null;
private int maxsize;
private int front; // 队列头
private int rear; // 队列尾
……
} - add():入队 data[rear++] = e;
- poll():出队 data[front++] = null
3.3、链表
public class ListNode {
private Object data;
private Node next;
public ListNode(Object data) {
this.data = data;
}
} 链表操作:
向链表头部添加元素
public void addHead(ListNode head, Object data) {
ListNode node = new ListNode(data);
// 判断原链表是否为空
if(head == null) {
head = node;
} else {
node.next = head;
head = node;
}
} 删除链表的节点
public boolean delete(ListNode head, Object value) {
// 判断链表是否为空
if(head == null) return false;
// 判断是否为头部
if(head.data == value) {
head = head.next;
return true;
}
// 遍历链表
ListNode cur = head, pre;
while(cur.next != null) {
pre = cur;
cur = cur.next;
if(cur.data == value) {
pre.next = cur.next;
return true;
}
}
return false;
} 单项链表的查询
public ListNode find(ListNode head, Object value) {
// 定义变量
ListNode cur = head;
// 开始遍历
while(cur != null) {
if(cur.data = value) {
return cur;
} else {
cur = cur.next;
}
}
return null;
} 反转链表
public ListNode reverseList(ListNode head) {
// 定义三个指针
ListNode pre = null, cur = head, next;
// 开始循环
while(cur != null) {
// 暂存下一个节点
next = cur.next;
// 修改指向
cur.next = pre;
pre = cur;
cur = next;
}
return pre;
} 从尾到头打印链表,返回数组
public inr[] reversePrint(ListNode head) {
// 使用栈进行存放
Stack<ListNode> stack = new Stack<>();
// 将链表存放到栈中
ListNode cur = head;
while(cur != null) {
stack.push(cur);
cur = cur.next;
}
// 将栈的内容输出到数组中
int size = stack.size();
int[] res = new int[size];
for(int i = 0; i < size; i++) {
res[i] = stack.pop().data;
}
return res;
} 链表中倒数第 K 个节点
public ListNode getKthFromEnd(ListNode head, int k) {
// 使用两个指针,相距 k 个节点
ListNode front = head, rear = head;
for(int i = 0; i < k; i++) {
front = front.next;
}
// 同时移动两个指针
while(front != null) {
front = front.next;
rear = rear.next;
}
return rear;
} 两个链表的第一个公共节点
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
// 让两个指针分别遍历两个链表,总会相与的
ListNode A = headA, B = headB;
while(A != B) {
A = A != null ? A.next : headB;
B = B != null ? B.next : headA;
}
return A;
} 3.4、二叉排序树
- 左子树不空时,左子树上所有节点的值均小于它的根节点的值
- 右子树不空时,右子树上所有节点的值均大于它的根节点的值
public class TreeNode {
private int value;
private Node left;
private Node right;
……
} 二叉树操作:
二叉树的插入
public void insertBST(treeNode root, int value) {
if(root == null) root = new TreeNode(value);
// 遍历二叉树
TreeNode cur = root;
while(cur != null) {
// 判断向左还是向右
if(value < cur.value) {
cur = cur.left;
} else if(value > cur.value){
cur = cur.right;
} else {
// 如果该值已经存在则直接返回
return ;
}
}
// 执行插入
cur = new TreeNode(value);
} 二叉树的删除
public boolean deleteBST(treeNode root, int value) {
if(root == null) return false;
if(root.value == value) {
// 删除根节点
return delete(root);
} else if(value < root.value) {
return deleteBST(root.left, value);
} else {
return deleteBST(root.right, value);
}
}
public boolean delete(TreeNode root) {
// 删除节点,如果左或右节点都为空的情况下,直接等于右或左节点
if(root.left == null) {
root = roor.right;
} else if(root.right == null) {
root = root.left;
} else{
// 左右节点都不为空,取左节点最大值
TreeNode cur = root.left;
while(cur.right != null) {
// 向右边寻找
cur = cur.right;
}
// 设置删除节点的值
root.setValue(cur.value);
// 删除下方节点
cur = null;
}
return true;
} 二叉排序树的查找
public boolean searchBST(TreeNode root, int value) {
// 遍历二叉树
TreeNode cur = root;
while(cur != null) {
if(cur.value == value) {
return true;
} else if(cur.value > value) {
cur = cur.left;
} else {
cur = cur.right;
}
}
return false;
} 3.5、枚举
4、算法
4.1、二分查找算法
- 要求待查找的序列有序
- 取中间值:
- 小于中间值:左边继续二分
- 大于中间值:右边继续二分

public int binarySearch(int[] array, int val) {
// 取数组的长度
int low = 0, hight = array.length - 1, mid;
while(low <= hight) {
// 取中间值
int mid = (hight - low) / 2 + low;
// 进行比较
if(array[mid] == val) {
return mid;
} else if(array[mid] > val) {
// 左边进行二分
hight = mid - 1;
} else {
// 右边继续二分
low = mid + 1;
}
}
return -1;
} 4.2、冒泡排序
public int[] bubbleSort(int[] arr) {
// 进行两层循环,arr.length - 1 可以防止数组越界
for(int i = 0; i < arr.length - 1; i++) {
// 定义标志位
int flag = false;
for(int j = 0; j < arr.lengrh - 1 - i; j++) {
if(arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
flag = true;
}
}
if(!flag) {
// 说明已经有序了,可以直接退出
break;
}
}
} 4.3、插入排序
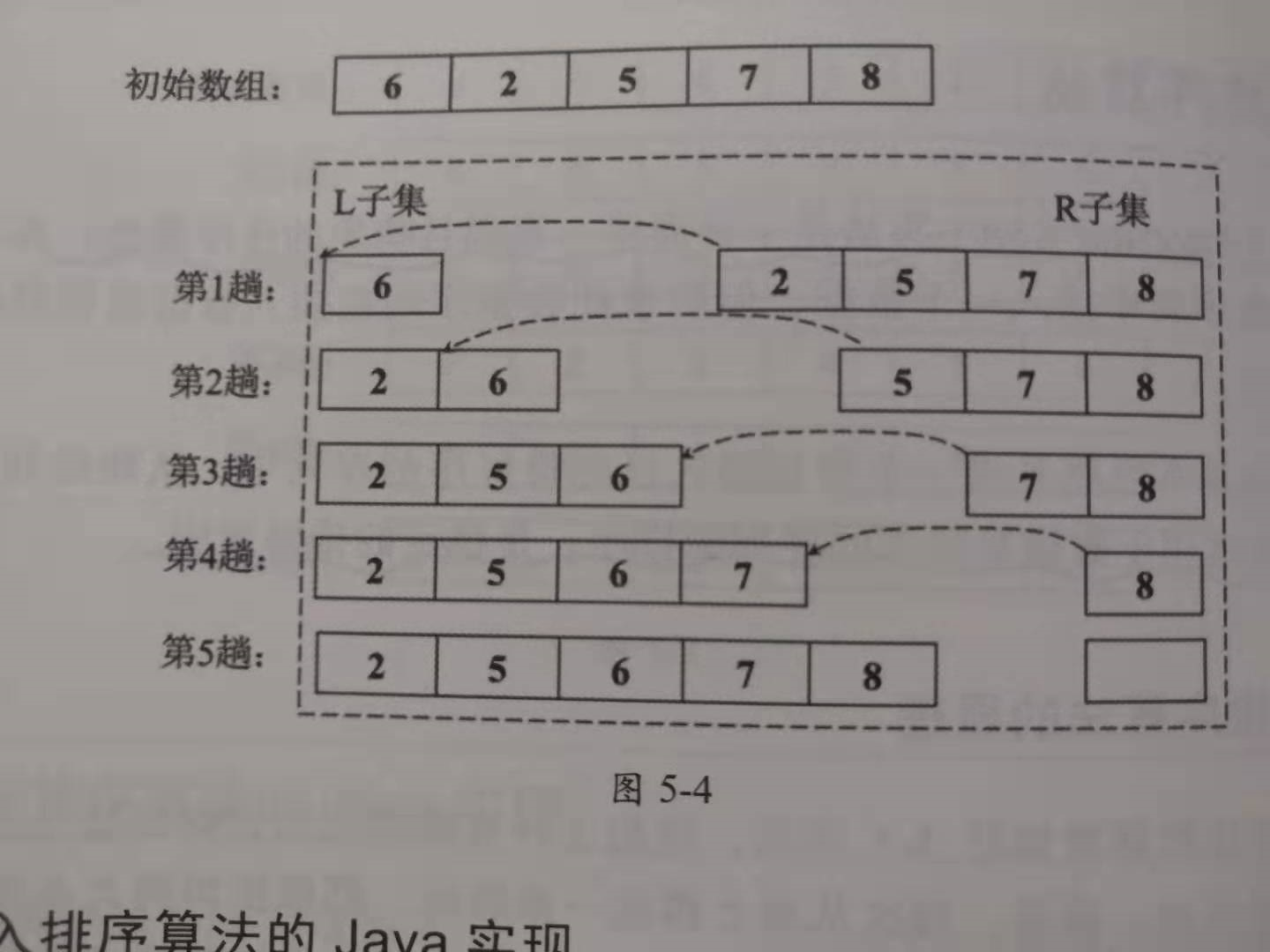
public int[] insertSort(int arr[]) {
// 取值,比较,摆放
for(int i = 1; i < arr.length; i++) {
// 插入的值
int insertValue = arr[i];
// 取上一个值的下标
int index = i - 1;
// 进行判断
while(index >= 0 && insertValue < arr[index]) {
arr[index + 1] = arr[index];
// 继续往前比较
index --;
}
arr[index + 1] = insertValue;
}
return arr;
} 4.4、选择排序
把第一个值当成最小值,然后进行比较换位
public int[] sort(int arr[]) {
int temp, minIndex;
for(int i = 0; i < arr.length; i++) {
// 取第一个值为最小值
minIndex = i;
for(int j = i + 1; j < arr.length; j++) {
// 如果存在比i小的值则换下标
if(arr[j] < arr[minIndex]) {
minIndex = j;
}
}
// 进行判断、换位
if(minIndex != i) {
temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
}
return arr;
} 4.5、快速排序
取数组左右下标、准值

public int[] quickSort(int[] arr, int low, int hight) {
// 定义左右指针,准值
int start = low, end = hight, key = arr[low];
// 进行迭代比较
while(end > start) {
// 右边的左移,并换位
while(end > start && arr[end] >= key) {
end--;
}
if(arr[end] <= key) {
int temp = arr[end];
arr[end] = key;
key = temp;
}
// 左边的右移,并换位
while(end > start && arr[start] <= key) {
strat++;
}
if(arr[start] >= key) {
int temp = arr[start];
arr[start] = key;
key = temp;
}
// 本次迭代完成,对左右继续进行迭代
if(start > low) {
quickSort(arr, low, start - 1);
}
if(end < hight) {
quickSort(arr, end + 1, hight);
}
}
return arr;
} 4.6、归并排序
5、JDBC编程
概念
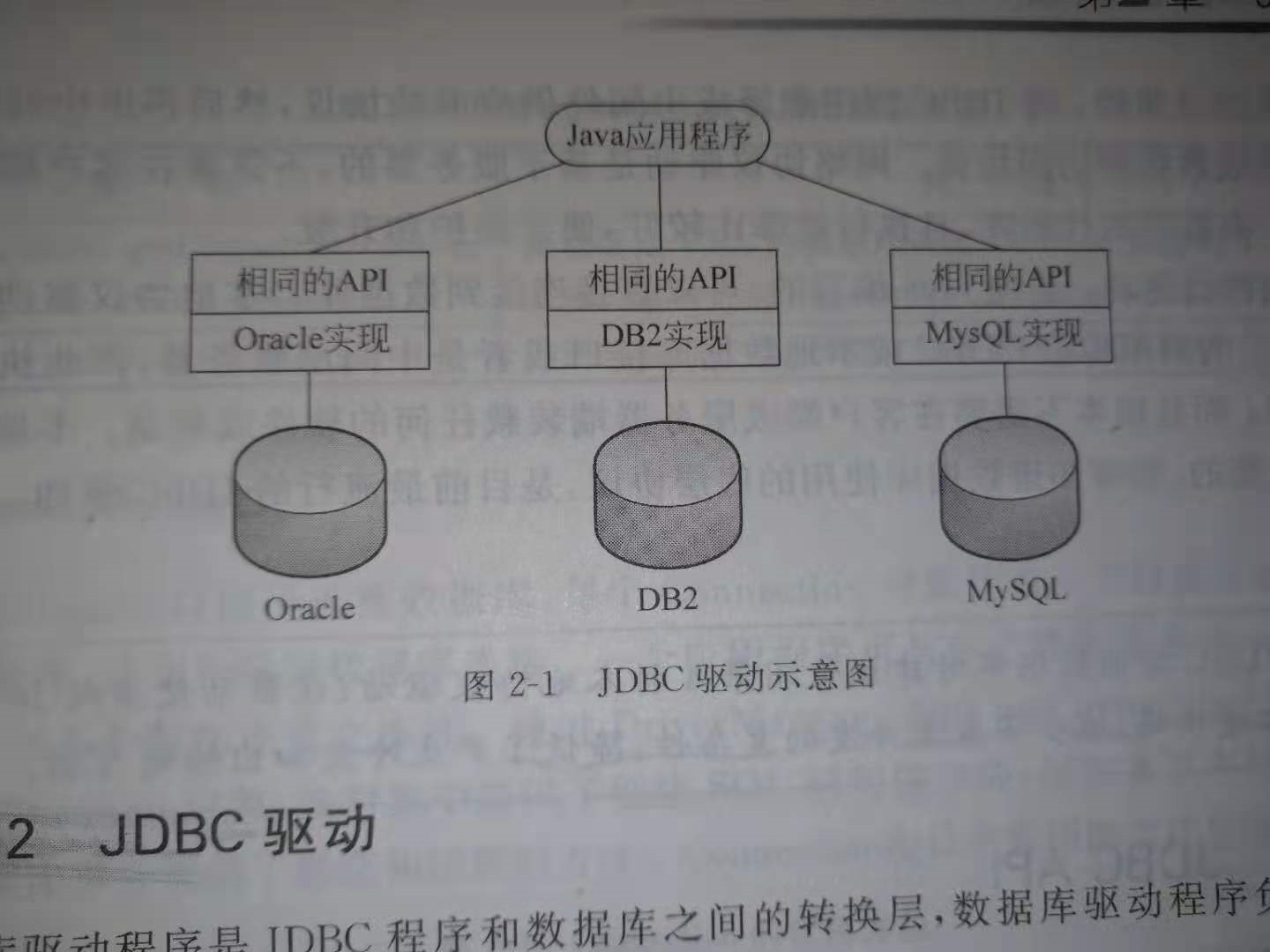
JDBC(Java DataBase Connectivity,Java 数据库连接)是一种执行SQL语句的Java API,程序可以通过JDBC API连接到关系数据库,并使用SQL结构化查询语言来完成对数据库的增、删、改、查等操作。与其他数据库编程语言相与,JDBC为数据开发者提供了标准的API,使用JDBC开发的数据库应用程序可以访问不同的数据库,并在不同的平台上运行。
JDBC访问数据库时主要完成以下三个基本工作:
- 建立于数据库的连接
- 执行SQL语句
- 获取执行结果
5.1、数据库访问
使用JDBC访问数据库的步骤如下:
- 加载数据库驱动
- 建立数据连接
- 创建 Statement 对象
- 执行SQL语句
- 访问结果集
加载数据库驱动
// 加载驱动
Class.forName("数据库驱动类名");
// 例如Oracle
Class.forName("oracle.jdbc.driver.OracleDriver");
// 加载MySql驱动
class.forName("com.mysql.jdbc.Driver");建立数据连接
// 语法
DriverManager.getConnection(String url, String user, String pass);
// 连接Oracle
Connection conn = DriverManager.getConnection(
"jdbc:oracle:thin:@loclahost:1521:orcl", // url连接字符串
"root", // 用户名
"123456" // 密码
); 创建Statement对象
// 创建Statement 对象
Statement smt = conn.createStatement();执行SQL语句
// executeQuery():只执行查询语句
// executeUpdate() 和 executeLargeUpdate() :用于执行DML 和 DDL 语句
// execute():执行所有SQL语句,但不推荐这样使用
ResultSet rs = smt.executeQuery("select * from user") 访问结果集
// 语法
rs.getString('列索引(数字)');
rs.getString('列名')关闭连接
- 关闭结果集,rs.close()
- 关闭Statement对象,stmt.close()
- 关闭连接,conn.close()
完整流程
public static void main(String[] args) {
try{
// 1、加载驱动
Class.forName("oracle.jdbc.driver.OracleDriver");
// 2、建立数据库连接
Connection conn = DriverManager.getConnection(
"jdbc:oracle:thin:@loclahost:1521:orcl", // url连接字符串
"root", // 用户名
"123456" // 密码
);
// 3、创建 Statement 对象
Statement stmt = conn.createStatement();
// 4、获取查询结果集
ResultSet rs = stmt.executeQuery("select * from user");
// 5、访问结果集中的数据
while(rs.next()) {
System.out.println(res.getString(1) + " " + rs.getString("username"));
}
} catch(Exception e) {
e.printStackTrace();
} finally {
// 释放资源
rs.close();
stmt.close();
conn.close();
}
} 6、SQL语句
1、概念
SQL
SQL(Structured Query Language)被称为 结构化查询语言,事目前主流的关系型数据库上执行数据操作、数据检索以及数据库维护所需要的标准语言。
主要分成如下5大类:
- 数据查询语句,如SELECT
- DML语句(数据操作语言),如INSERT/UPDATE/DELETE/MERGE
- DDL语句(数据定义语言),如CREATE/ALTER/DROP/TRUNCATE
- DCL语句(数据控制语言),如GRANT/REVOKE
表格命名
- 数据库表名一般使用
T_开头 或者_T结尾 - 字段使用
_进行拼接
数据类型
- 字符串类型
- CHAR:固定长度,查询的速度快
- VARCHAR2:可变长度,查询速度略慢
- 数值类型
- INTEGER或INT,表示整数
- FLOAT,表示浮点数
- DOUBLE,表示双精度浮点型
- 日期类型
- DATE,表示日期类型
- DATETIME
2、提取关系
一对一
比如:校长 和 学校 之间的关系
可以通过使用外键的方式将两个表格联系起来。
一对多
比如:班级 和 学生 的关系,一个班级有多个学生,而学生只属于一个班级
在“多”的表格中,添加上“一”的主键作为外键,即在 学生 中添加上班级号作为 外键
多对多
比如:学生 和 课程 之间的关系
创建一个关系表,将两个表格的主键均当成外键联系起来
3、数据库的查询
1、简单查询
select name,age from user;2、字符串连接
使用||进行列拼接
在名字前增加“姓名:”字段
select '姓名:' || name as '姓名' from user;拼接两个字段
select name || age from user;
3、去除重复值 distinct
select distinct age from user;4、添加查询条件
使用 where 进行添加条件
- 关系运算符
><>=<=!=或<>
- 逻辑运算符
- and、or、not
- 其他
- between…and
- in
- like:%表示该位置可以有多个,_表示只有一个字符
- is not null
select user from user where age='20';排序
使用order by 进行排序输出结果,放在最后,可以使用多字段排序
- asc:升序(默认)
- desc:降序
排序规则
- 数值按照大小排序
- 日期按照时间先后排序
- 字符串按照字符的 ASCII 码进行排序
select * from user order by age desc,name; -- 先按照年龄排序,年龄相同按照姓名排序4、连接查询
1、笛卡尔积
在查询的时候,直接查询两个表格,这样可以将两个表格进行组合查询
select * from user,score where user.id=score.uid;2、内连接
如果一方表的连接列值在另一方表内找不到,则丢弃整条记录
select 列名
from 表1
inner join 表2 on 查询条件 -- inner可以省略不写
where 其他条件;3、外连接
如果一方表的连接列值在另一方表内找不到,则让找不到的一方的列值显示为空值
左外连接
左方表的连接列值在右方表内找不到,则将右方表中找不到的内容用null表示
-- 方式一
select 列名
from 表1
left outer join 表2 on 查询条件
where 其他条件;
-- 方式二,使用笛卡尔
select 列名
from 表1,表2
where 表1.id = 表2.uid(+);右外连接
右方表的连接列值在左方表内找不到,则将左表中找不到的内容用null表示
select 列名
from 表1
right outer join 表2 on 查询条件
where 其他条件;完全外连接
既考虑左外连接又考虑右外连接,找不到的内容就用null表示
select 列名
from 表1
full outer join 表2 on 查询条件
where 其他条件;5、聚合函数
常用的函数
- count:计算总个数
- avg:平均值
- sum:总和
- max:最大值
- min:最小值
1、count总和
select count(*) as 总人数
from user;
select count(distinct age) as 不同年龄的数量
from user;其他的函数用法类似
2、聚合函数的拼接
注意:聚合函数不可以出现在where中
使用子查询
select *
from user
where age = (select min(age) from user)使用group by进行分组
select name,count(name)
from user
group by name3、使用having字句对聚合结果进行限制
select name,avg(age)
from user
group by name
having avg(age)>=186、子查询
其实就是嵌套查询,在查询语句中增加其他查询结果作为条件
select name
from user
where age = (
select age
from user
where name = '晓江'
);查询选课人数
select course_id,course_name,(
select count(stu_id)
from students
where students.cid = courses.id) as 选课人数
from couses7、数据处理
1、round取整数
使用round对结果中的每一行进行四舍五入取整,对每一行都得到一个结果
select name,round(score)
from user;2、字符串处理函数
只修改显示的结果,不影响数据库内容
字母大小写
- lower:全小写
- upper:全大写
- initcap:首字母大写
字符串处理
- substr(x, y, z):截取字符串,x 为字符,y 为起点,z 为长度
- length(x):获取字符长度
- instr(x, y):查询 y 在字符串 x 中的下标,从1算起
- trim():去除两端空格,还有 ltrim() 和 rtrim()
- replace(x, y, z):将字符串 x 中的 y 替换为 z
8、DML语句
1、insert语句
普通插入
insert user(name, age)
value('晓江', 22);插入并提交
insert user(name, age)
value('晓江', 22)
commit;多条插入
将查询的结果进行插入
insert user(name, age)
select name, age
from students
where age>18;2、delete语句
普通删除
delete from user where age<18;清空表格
delete from user;
-- 或者使用truncate
truncate userdelte 和 truncate 的区别
- truncate 只能清空所有内容
- truncate 不支持回滚
- truncate 释放表的存储空间,而delete不释放空间
3、update语句
修改一条数据
update user
set age = 23
where name = '晓江';修改所有数据
update user
set age = age + 1;9、表的创建和约束
7、Java工具类
1、概述
在基础库部分,Sun公司提供了极其丰富的功能类,为了便于区分,根据类的功能大致把这些类放在了不同的包内,例如java.lang包、java.util包、java.io包、java.sql包、java.text包等等。这里主要讲解java.lang包及java.text包中的部分类,对于其他的三个包,将会在后续单独讲解。
对于初学者来说,最为常用的工具类有封装类、String、StringBuffer、Random、Date、Calendar、SimpleDateFormat及Math静态类等等;
2、Integer整数类
Integer是int基本类型的包装类
属性
| 属性名称 | 描述 |
|---|---|
| static int MAX_VALUE | 返回最大的整型数 |
| static int MIN_VALUE | 返回最小的整型数 |
| static Class TYPE | 返回当前类型 |
System.out.println("Integer.MAX_VALUE:" + Integer.MAX_VALUE);
// 输出结果为:Integer.MAX_VALUE:2147483647构造方法
| 构造器 | 描述 |
|---|---|
| Integer(int value) | 通过一个int的类型构造对象 |
| Integer(String s) | 通过一个String的类型构造对象 |
//生成了一个值为1234的Integer对象
Integer i = new Integer(1234);
Integer i = new Integer("1234");3、Character字符类
Character 类在对象中包装一个基本类型 char 的值
属性
| 属性名称 | 属性描述 |
|---|---|
| static char MIN_VALUE | 此字段的常量值是 char 类型的最小值,即 ‘\u0000’ |
| static char MAX_VALUE | 此字段的常量值是 char 类型的最大值,即 ‘\uFFFF’ |
| static Class TYPE | 表示基本类型 char 的 Class 实例 |
构造方法
Character(char value):以char参数构造一个Character对象
方法
package com.lesson4;
/**
* Character包装类的用法
*/
public class CharacterDemo {
public static void main(String[] args) {
Character ch1 = new Character('a');
Character ch2 = new Character('A');
// ch1的char值
System.out.println("char value of ch1 : " + ch1.charValue());
// 对比ch1和ch2的大小
System.out.println("ch1 compare to ch2 : " + ch1.compareTo(ch2));
// 表示范围的最小值
System.out.println("min value(int) : " + (int) Character.MIN_VALUE);
// 表示范围的最大值
System.out.println("max value(int) : " + (int) Character.MAX_VALUE);
// 判断一个字符是否是数字形式
System.out.println("is digit '1' : " + Character.isDigit('1'));
// 判断一个字符是否是大写形式
System.out.println("is upper case 'a' : " + Character.isUpperCase('a'));
// 判断一个字符是否是空格
System.out.println("is space char ' ' : " + Character.isSpaceChar(' '));
// 判断一个字符是否是字母
System.out.println("is letter '1' :" + Character.isLetter('1'));
// 判断一个字符是否是字母或数字
System.out.println("is letter or digit '好' :"
+ Character.isLetterOrDigit('好'));
// 把字母转化为大写形式
System.out.println("to upper case 'a' :" + Character.toUpperCase('a'));
}
} 4、String字符串类
构造方法
| 构造器 | 描述 |
|---|---|
| String() | 构造一个空字符串对象 |
| String(byte[] bytes) | 通过byte数组构造字符串对象 |
| String(char[] chars) | 通过字符数组构造字符串对象 |
| String(String original) | 构造一个original的副本,即拷贝一个original |
| String(StringBuffer buffer) | 通过StringBuffer数组构造字符串对象 |
byte[] b = { 'a','b','c','d','e','f','g','h','i','j'} ;
char[] c = { '0','1','2','3','4','5','6','7','8','9'} ;
String sb = new String(b);
String sb_sub = new String(b,3,2);
String sc = new String(c);
String sc_sub = new String(c,3,2);
String sb_copy = new String(sb);
System.out.println("sb: " + sb );
System.out.println("sb_sub: " + sb_sub );
System.out.println("sc: " + sc );
System.out.println("sc_sub: " + sc_sub );
System.out.println("sb_copy: " + sb_copy );
/*
输出结果为:
sb: abcdefghij
sb_sub: de
sc: 0123456789
sc_sub: 34
sb_copy: abcdefghij
*/方法
提取字符:s.charAt(5)
String s = new String("abcdefghijklmnopqrstuvwxyz"); System.out.println("s.charAt(5): " + s.charAt(5) ); // 运行结果为:s.charAt(5): f字符串比较:s1.compareTo(s2)
String s1 = new String("abcdefghijklmn"); String s2 = new String("abcdefghij"); String s3 = new String("abcdefghijalmn"); System.out.println("s1.compareTo(s2): " + s1.compareTo(s2) ); System.out.println("s1.compareTo(s3): " + s1.compareTo(s3) ); /* 本例对两个字符串进行对比,运行结果为: s1.compareTo(s2): 4 s1.compareTo(s3): 10 */判断一个字符串是否是另外一个字符串的结尾:s1.endsWith(s2) 和开头 s.startsWith(ss)
String s1 = new String("abcdefghij"); String s2 = new String("ghij"); System.out.println("s1.endsWith(s2): " + s1.endsWith(s2) ); // 运行结果为:s1.endsWith(s2): true查找字符位置
String s = new String("write once, run anywhere!"); String ss = new String("run"); System.out.println("s.indexOf('r'): " + s.indexOf('r') ); System.out.println("s.indexOf('r',2): " + s.indexOf('r',2) ); System.out.println("s.indexOf(ss): " + s.indexOf(ss) ); /* 运行结果为: s.indexOf('r'): 1 s.indexOf('r',2): 12 s.indexOf(ss): 12 */转为大小写:s.toUpperCase() 和 s.toLowerCase()
字符串的不变性
public static void main(String[] args) {
String s1 = new String("hello ");
// 将abc连接在s1的后面
s1.concat("abc");
System.out.println("s1 = " + s1);
// 使用replace方法把字符串s2中的字符o替换为u
String s2 = new String("good morning!");
s2.replace('o', 'u');
System.out.println("s2 = " + s2);
} 可以看到字符串s1、s2虽然尝试进行了修改,但是,它们并没有发生任何变化,这是为什么呢?其实,一个字符串对象一但创建,那么这个字符串对象内容存放地址里面的内容就不能改变,对于s1来说,我们尝试在其后连接上abc,因不能对s1进行直接修改,所以将会创建一个新的字符串对象,而新创建的对象的引用,我们并未将其赋给s1,结果导致s1的值没有变化。对于s2来说,也是一样的道理。
修改方法:
//其余部分省略
s1 = s1.concat("abc");
s2 = s2.replace('o', 'u');由于在对String字符串进行修改的过程中,将会创建新的字符串对象,如果因为需要而反复修改字符串,将大大浪费系统资源,创建一大堆无用的对象。为了避免这种情况出现,我们需要能直接修改的字符串对象,这就是StringBuffer。
5、StringBuffer字符串缓冲类
String类的功能受到限制,而StringBuffer类可以完成字符串的动态添加、插入和替换等操作,对StringBuffer的修改,是直接的,不会创建多余的对象。
StringBuffer类中的方法都添加了synchronized关键字,所以StringBuffer是线程安全的。
构造方法
| 构造器名称 | 描述 |
|---|---|
| StringBuffer() | 构造一个没有任何字符的StringBuffer类 |
| StringBuffer(int length) | 构造一个没有任何字符的StringBuffer类,并且,其长度为length |
| StringBuffer(String str) | 以str为初始值构造一个StringBuffer类 |
方法
字符串拼接
StringBuffer 上的主要操作是 append 和 insert 方法,可重载这些方法,以接受任意类型的数据。
append 方法始终将这些字符添加到缓冲区的末端;而 insert 方法则在指定的点添加字符。
public static void main(String[] args) {
String question = new String("1+1=");
int answer = 3;
boolean result = (1 + 1 == 3);
StringBuffer sb = new StringBuffer();
sb.append(question);
sb.append(answer);
sb.append(result);
sb.insert(5, ','); // 在指定位置添加字符
System.out.println(sb);
}
// 结果为: 1+1=3,false以下示例调整了StringBuffer的容量,这将会给StringBuffer对象分配更多的空间。其实,如果容量不够,那么编译器将会自动分配更高的容量。
public static void main(String[] args) {
// 指定长度为 5
StringBuffer sb1 = new StringBuffer(5);
StringBuffer sb2 = new StringBuffer(5);
// 设置StringBuffer的容量
sb1.ensureCapacity(6);
sb2.ensureCapacity(100);
System.out.println( "sb1.Capacity: " + sb1.capacity() );
System.out.println( "sb2.Capacity: " + sb2.capacity() );
}
/*
结果为:
sb1.Capacity: 12
sb2.Capacity: 100
*/字符串反转
public static void main(String[] args) {
StringBuffer sb = new StringBuffer("0123456789");
// 使用reverse() 方法进行反转
System.out.println( "sb.reverse(): " + sb.reverse() );
} 截取字符串
public static void main(String[] args) {
StringBuffer sb = new StringBuffer("0123456789");
sb.setLength(5);
System.out.println( "sb: " + sb );
}
// 结果为:sb: 012346、StringBuider
StringBuilder类也代表可变字符串对象。实际上,StringBuilder和StringBuffer基本相似,两个类的构造器和方法也基本相同。不同的是:StringBuffer是线程安全的,而StringBuilder则没有实现线程安全功能,所以性能略高。
7、Random随机类
此类用来产生随机数,位于java.util包中,所以需要手工导包。
构造方法
| 构造器 | 描述 |
|---|---|
| Random() | 创建一个新的随机数发生器 |
| Random(long seed) | 用一个种子(长整型)创建一个随机数发生器 |
方法
Random这个类的对象使用一个48位的种子,如果这个类的两个实例是用同一个种子创建的,并且,各自对它们以同样的顺序调用方法,则它们会产生相同的数字序列。
public static void main(String[] args) {
Random r1 = new Random(50);
System.out.println("第一个种子为50的Random对象");
System.out.println("r1.nextBoolean():\t" + r1.nextBoolean());
System.out.println("r1.nextInt():\t\t" + r1.nextInt());
System.out.println("r1.nextDouble():\t" + r1.nextDouble());
System.out.println("r1.nextGaussian():\t" + r1.nextGaussian());
System.out.println("---------------------------");
Random r2 = new Random(50);
System.out.println("第二个种子为50的Random对象");
System.out.println("r2.nextBoolean():\t" + r2.nextBoolean());
System.out.println("r2.nextInt():\t\t" + r2.nextInt());
System.out.println("r2.nextDouble():\t" + r2.nextDouble());
System.out.println("r2.nextGaussian():\t" + r2.nextGaussian());
System.out.println("---------------------------");
Random r3 = new Random(100);
System.out.println("种子为100的Random对象");
System.out.println("r3.nextBoolean():\t" + r3.nextBoolean());
System.out.println("r3.nextInt():\t\t" + r3.nextInt());
System.out.println("r3.nextDouble():\t" + r3.nextDouble());
System.out.println("r3.nextGaussian():\t" + r3.nextGaussian());
}
/*
结果:
第一个种子为50的Random对象
r1.nextBoolean(): true
r1.nextInt(): -1727040520
r1.nextDouble(): 0.6141579720626675
r1.nextGaussian(): 2.377650302287946
---------------------------
第二个种子为50的Random对象
r2.nextBoolean(): true
r2.nextInt(): -1727040520
r2.nextDouble(): 0.6141579720626675
r2.nextGaussian(): 2.377650302287946
---------------------------
种子为100的Random对象
r3.nextBoolean(): true
r3.nextInt(): -1139614796
r3.nextDouble(): 0.19497605734770518
r3.nextGaussian(): 0.6762208162903859
*/8、Date时间类
构造方法
| 构造器名称 | 描述 |
|---|---|
| Date() | 创建的日期类对象的日期时间被设置成创建时刻相对应的日期时间 |
| Date(long date) | long型的参数date可以通过调用Date类中的static方法parse(Strings)来获得 |
方法
public static void main(String[] args) {
Date date1 = new Date();
Date date2 = new Date(1233997578421L);
//输出date1、date2对象所对应的毫秒数
System.out.println(date1.getTime());
System.out.println(date2.getTime());
//查看date1是否在date2后
boolean isAfter = date1.after(date2);
System.out.println("is date1 after date2:"+isAfter);
// 设置时间
date1.setTime(1133997578421L);
isAfter = date1.after(date2);
System.out.println("is date1 after date2:"+isAfter);
} 9、Calendar日历类
Calendar类是一个抽象类,所以不能直接通过new关键字创建Calendar类的实例,可以借助于该类提供的静态方法getInstance()来获得一个Calendar对象。
Calendar rightNow = Calendar.getInstance();
方法
public static void main(String[] args) {
//创建Calendar实例
Calendar ca = Calendar.getInstance();
//获得ca所包含的年份。注意写法
System.out.println("year is :"+ca.get(Calendar.YEAR));
//为年份增加2
ca.add(Calendar.YEAR, 2);
System.out.println("year is :"+ca.get(Calendar.YEAR));
//设置ca的年份
ca.set(Calendar.YEAR,2009);
System.out.println("year is :"+ca.get(Calendar.YEAR));
//今天是今年的第几天
System.out.println("day of year:"+ca.get(Calendar.DAY_OF_YEAR));
//今天是本周的第几天,注意默认情况下周日是第一天
System.out.println("day of week : "+ca.get(Calendar.DAY_OF_WEEK));
//获得对应的Date对象
Date date = ca.getTime();
System.out.println("date time : "+date.getTime());
System.out.println("calendar time : "+ca.getTimeInMillis());
} 10、SimpleDateFormat 日历格式化
SimpleDateFormat类可以对Date及字符串进行分析,并在它们之间相互转换,它允许格式化 (date -> text)、语法分析 (text -> date)和标准化。它的继承关系如下:
java.lang.Object
+—-java.text.Format
+—-java.text.DateFormat
+—-java.text.SimpleDateFormat
使用方法
public static void main(String[] args) {
Date date = new Date();
SimpleDateFormat myFmt = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒");
// SimpleDateFormat myFmt = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
myFmt.format(date);
} 11、Math算术运算类
方法
public static void main(String[] args) {
// 绝对值
System.out.println("abs of -1 : " + Math.abs(-1));
// 比这个数大的最小整数
System.out.println("ceil of 9.01 : " + Math.ceil(9.01));
// 比这个数小的最大整数
System.out.println("floor of 9.99 :" + Math.floor(9.99));
// 取较大者
System.out.println("the max is : " + Math.max(101, 276.001));
// 随机数,区间为[0.0,1.0)
System.out.println("random number : " + Math.random());
// 四舍五入
System.out.println("round value of 9.49 :" + Math.round(9.49));
// 返回正确舍入的 double 值的正平方根
System.out.println("square root of 225 : " + Math.sqrt(225));
} 8、Java集合类
1、Collection
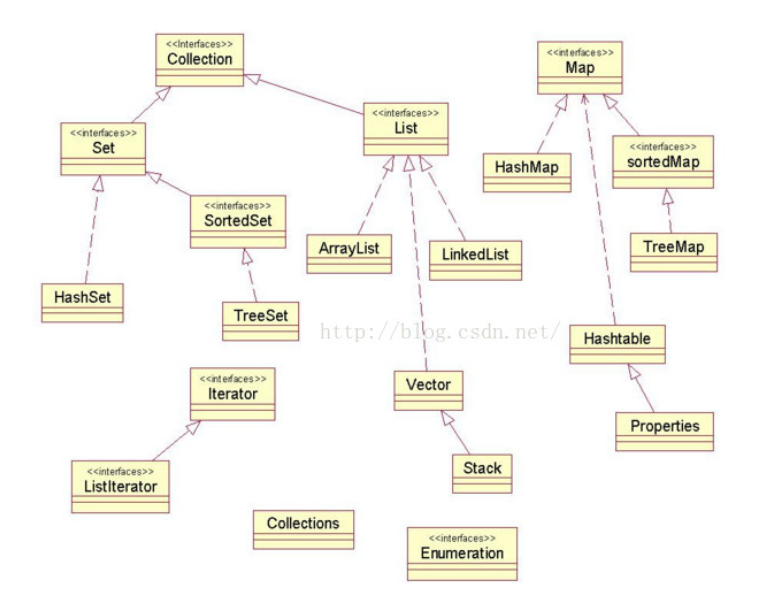
概念
来源于Java.util包,是非常实用常用的数据结构,字面意思就是容器。具体的继承实现关系如下图
主要方法
- boolean add(Object o):添加对象到集合
- boolean remove(Object o):删除指定的对象
- int size():返回当前集合中元素的数量
- boolean contains(Object o):查找集合中是否有指定的对象
- boolean isEmpty():判断集合是否为空
- Iterator iterator():返回一个迭代器
- boolean containsAll(Collection c):查找集合中是否有集合c中的元素
- boolean addAll(Collection c):将集合c中所有的元素添加给该集合
- void clear():删除集合中所有元素
- void removeAll(Collection c):从集合中删除c集合中也有的元素
- void retainAll(Collection c):从集合中删除集合c中不包含的元素
Collection主要子接口
- List
- Set
1、List抽象接口,可重复有序
主要方法:
- void add(int index,Object element):在指定位置上添加一个对象
- boolean addAll(int index,Collection c):将集合c的元素添加到指定的位置
- Object get(int index):返回List中指定位置的元素
- int indexOf(Object o):返回第一个出现元素o的位置.
- Object remove(int index):删除指定位置的元素
- Object set(int index,Object element):用元素element取代位置index上的元素,返回被取代的元素
- void sort()
List主要子接口对象
- LinkedList:没有同步方法,底层使用链表结构,增删速度快,查询稍慢
- ArrayList:非同步的(unsynchronized)
- Vector(同步): 非常类似ArrayList,但是Vector是同步的
- Stack :记住 push和pop方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置
2、Set不包含重复的元素
Set主要子接口对象
- HashSet:其底层其实也是一个数组,存在的意义是提供查询速度,插入的速度也是比较快,但是适用于少量数据的插入操作,判断两个对象是否相等的规则:1、equals比较为true;2、hashCode值相同。要求:要求存在在哈希表中的对象元素都得覆盖equals和hashCode方法。
- SortSet:保证迭代器按照元素递增顺序遍历的集合,可以按照元素的自然顺序(参见 Comparable)进行排序, 或者按照创建有序集合时提供的 Comparator进行排序。
- TreeSet:Set接口的实现类,也拥有set接口的一般特性,但是不同的是他也实现了SortSet接口,它底层采用的是红黑树算法
3、Map
Map没有继承Collection接口,Map提供key到value的映射。
方法
- boolean equals(Object o):比较对象
- boolean remove(Object o):删除一个对象
- put(Object key, Object value):添加key和value
主要子接口对象
- HashMap:哈希表的实现包括数组+链表+红黑树,在使用哈希表的集合中我们都认为他们的增删改查操作的时间复杂度都是O(1)的,不过常数项很大,因为哈希函数在进行计算的代价比较高,HashMap和Hashtable类似,不同之处在于HashMap是非同步的,并且允许null,即null value和null key
- TreeMap:是一个有序的key-value集合,它是通过红黑树实现的,键值不能是null
- HashTable:继承Map接口,实现一个key-value映射的哈希表。任何非空(non-null)的对象都可作为key或者value,线程安全
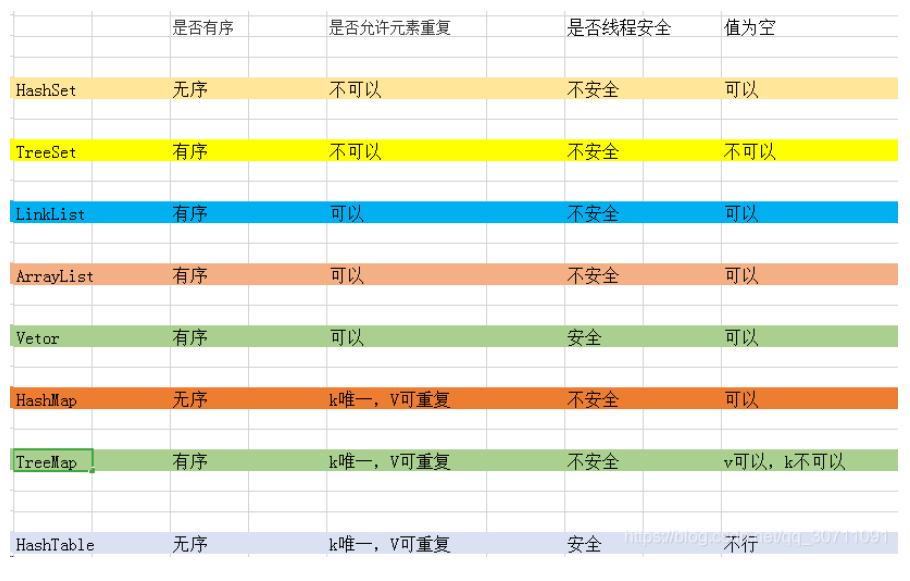
4、集合类总结
2、Collections
java.util.Collections 是一个包装类。它包含有各种有关集合操作的 静态多态方法。此类 不能实例化,就像一 个工具类,服务于Java的Collection框架。
主要方法
1、sort:排序
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class TestCollections {
public static void main(String args[]) {
//注意List是实现Collection接口的
List list = new ArrayList();
double array[] = { 11,2,323,56,231,54,-3,-5} ;
for (int i = 0; i < array.length; i++) {
list.add(new Double(array[i]));
}
//使用工具类中的静态方法进行排序
Collections.sort(list);
//输出结果,可看见得到排序的结果
for (int i = 0; i < array.length; i++) {
System.out.println(list.get(i));
}
}
} 2、 混排(Shuffling)
混排算法所做的正好与 sort 相反: 它打乱在一个 List 中可能有的任何排列的踪迹。也就是说,基于随机源的输入重排该 List, 这样的排列具有相同的可能性(假设随机源是公正的)。这个算法在实现一个碰运气的游戏中是非常有用的。例如,它可被用来混排代表一副牌的 Card 对象的一个 List 。另外,在生成测试案例时,它也是十分有用的。
Collections.Shuffling(list)
3、反转(Reverse)
使用Reverse方法可以根据元素的自然顺序 对指定列表按降序进行排序。
Collections.reverse(list)
4、替换所以的元素(Fill)
使用指定元素替换指定列表中的所有元素。
Collections.fill(li,”aaa”);
5、拷贝(Copy)
用两个参数,一个目标 List 和一个源 List, 将源的元素拷贝到目标,并覆盖它的内容。目标 List 至少与源一样长。如果它更长,则在目标 List 中的剩余元素不受影响。
Collections.copy(list,li): 前面一个参数是目标列表 ,后一个是源列表。
6、返回Collections中最小元素(min)
根据指定比较器产生的顺序,返回给定 collection 的最小元素。collection 中的所有元素都必须是通过指定比较器可相互比较的。
Collections.min(list)
7、返回Collections中最小元素(max)
根据指定比较器产生的顺序,返回给定 collection 的最大元素。collection 中的所有元素都必须是通过指定比较器可相互比较的。
Collections.max(list)
8、lastIndexOfSubList
返回指定源列表中最后一次出现指定目标列表的起始位置
int count = Collections.lastIndexOfSubList(list,li);
9、IndexOfSubList
返回指定源列表中第一次出现指定目标列表的起始位置
int count = Collections.indexOfSubList(list,li);
10、Rotate
根据指定的距离循环移动指定列表中的元素Collections.rotate(list,-1);
如果是负数,则正向移动,正数则方向移动
3、Collection 和 Collections 的区别
- java.util.Collection 是一个集合接口(集合类的一个顶级接口)。它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式,其直接继承接口有List与Set。
- Collections则是集合类的一个工具类/帮助类,其中提供了一系列静态方法,用于对集合中元素进行排序、搜索以及线程
- 本文链接:https://lxjblog.gitee.io/2021/07/11/java%E7%9F%A5%E8%AF%86%E7%82%B9/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。