1、日常问题
1、调整桌面图标间距
按 ctrl + r ,然后输入regedit, 打开注册表
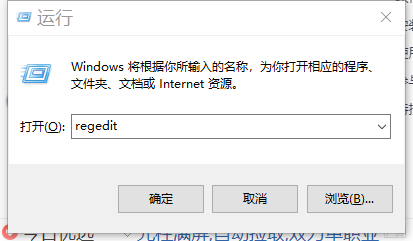
分别双击调整水平和垂直间距
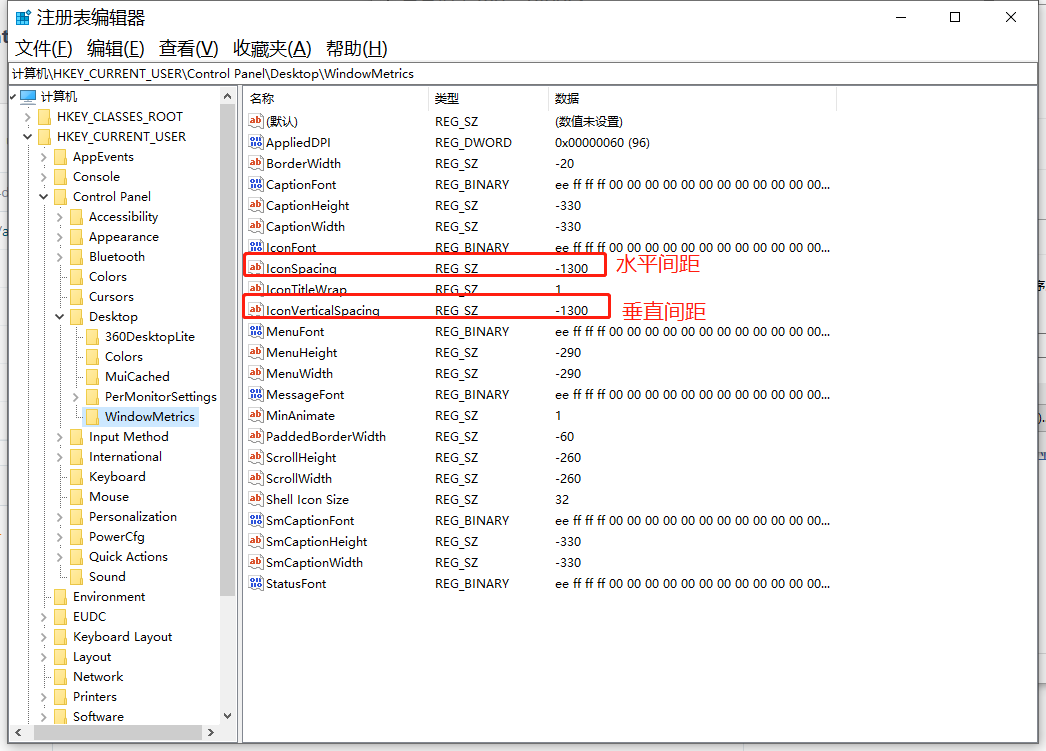
然后完成之后重启电脑,重新加载注册表才可以看到调整后的效果
2、gitee生成公钥
在git窗口输入指令
ssh-keygen然后按三下回车即可
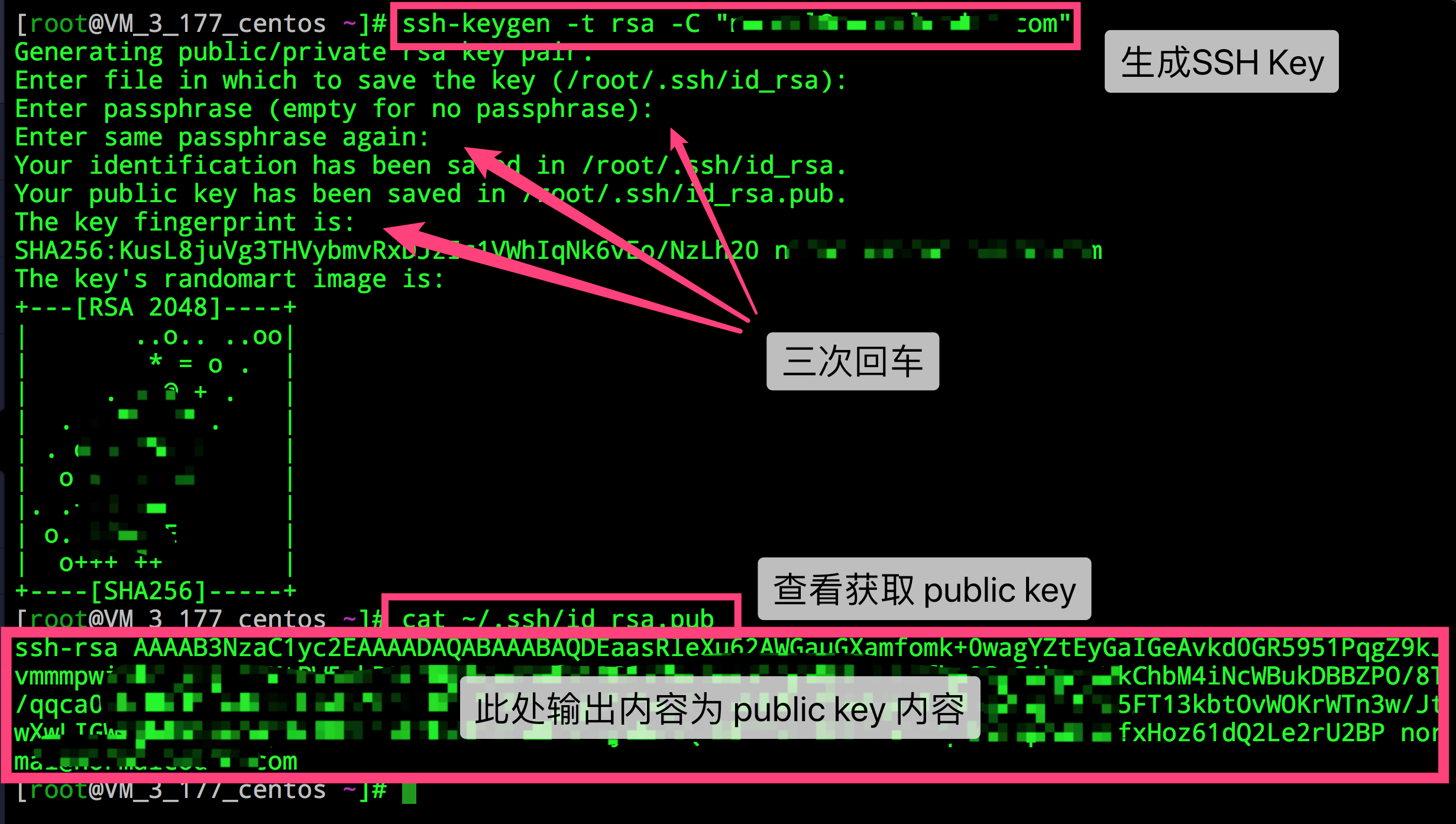
然后进入对应的文件中查看公钥
C:\Users\12562\.ssh
3、配置环境变量
Java环境
JAVA_HOME
C:\Program Files\Java\jdk1.8.0_301
Path
.;%JAVA_HOME%\bin;%JAVA_HOME%\jre\binMaven环境
M2_HOME
D:\Program Files\Maven\apache-maven-3.8.1-bin\apache-maven-3.8.1\bin
MAVEN_HOME
D:\Program Files\Maven\apache-maven-3.8.1-bin\apache-maven-3.8.1
Path
%MAVEN_HOME%\bin4、’javac’ 不是内部或外部命令,也不是可运行的程序
修改环境变量 Path
%JAVA_HOME%\bin\
%JAVA_HOME%\jre\bin\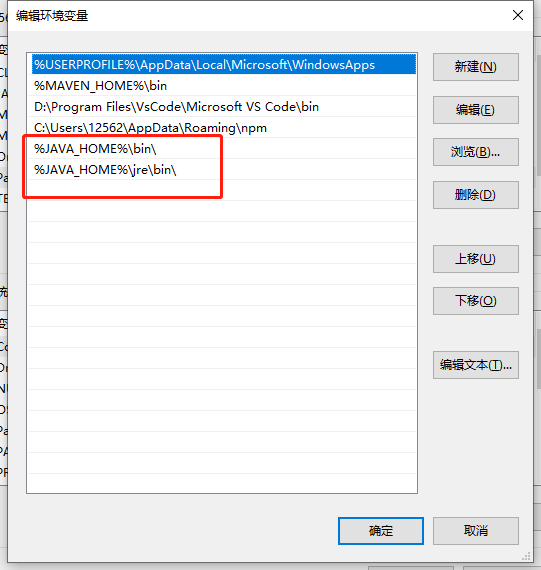
2、笔记
1、后端内容
1、注解的说明
@Repository的作用
- @Repository、@Service、@Controller 和 @Component 将类标识为Bean
- 它用于将数据访问层 (DAO 层 ) 的类标识为 Spring Bean。具体只需将该注解标注在 DAO类上即可。同时,为了让 Spring 能够扫描类路径中的类并识别出 @Repository 注解
@component的作用
作用:例如我在实现类中用到了@Autowired注解,被注解的这个类是从Spring容器中取出来的,那调用的实现类也需要被Spring容器管理,加上@Component
和@Bean的区别:
@Component注解表明一个类会作为组件类,并告知Spring要为这个类创建bean
@Bean注解告诉Spring这个方法将会返回一个对象,这个对象要注册为Spring应用上下文中的bean。通常方法体中包含了最终产生bean实例的逻辑
两者的目的是一样的,都是注册bean到Spring容器中
2、Collector和Collectors
示例
List<PositionConnect> positionConnect = produceBiz.getPositionConnect()
.stream().filter(e -> e.getLocationCode().equals(locationCode)).collect(Collectors.toList());- Collector是专门用来作为Stream的collect方法的参数的
- 而Collectors是作为生产具体Collector的工具类
- Collection的集合子类可以使用
stream().filter(flag).collect(Collectors.toList())通过设置 flag 条件进行内容过滤
参考文章:https://www.jianshu.com/p/7eaa0969b424
3、复制对象内容
示例
通过调用 BeanUtils 的 copyProperties 方法,将 warehouse 的内容复制到 vo 中,两者的属性相同,但是 vo 增加了其他方法
List<Warehouse> warehouses = warehouseBiz.getWarehouseIncludeVirtual();
List<WarehouseVo> warehouseVos = new ArrayList<>();
for (Warehouse warehouse : warehouses) {
WarehouseVo vo = new WarehouseVo();
BeanUtils.copyProperties(warehouse, vo);
warehouseVos.add(vo);
} 4、Java代码注释TODO FIXME XXX的意义
TODO: 说明:
- 如果代码中有该标识,说明在标识处有功能代码待编写,待实现的功能在说明中会简略说明,表示需要实现,但目前还未实现的功能。
FIXME: 说明:
- 如果代码中有该标识,说明标识处代码需要修正,甚至代码是错误的,不能工作,需要修复,如何修正会在说明中简略说明。代码是错误的,不能工作,需要修复
XXX: 说明:
- 如果代码中有该标识,说明标识处代码虽然实现了功能,但是实现的方法有待商榷,希望将来能改进,要改进的地方会在说明中简略说明。勉强可以工作,但是性能差等原因
使用了上方注解之后可以在IDEA中快速查看到标记的代码位置。
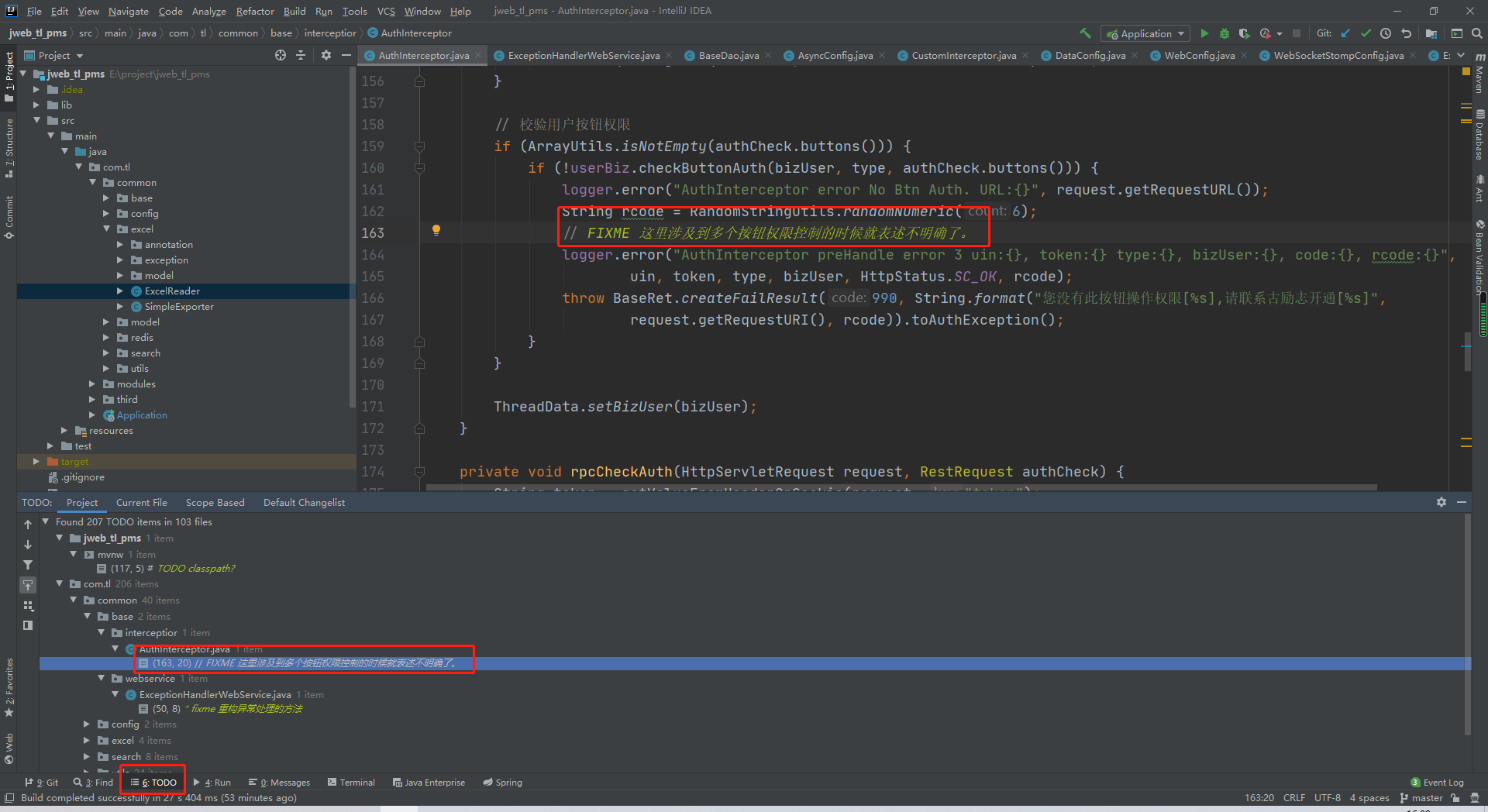
6、sql优化的几种方式
对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引
.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100应改为:
select id from t where num=100*2应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
-- name以abc开头的id select id from t where substring(name,1,3)='abc'应改为:
select id from t where name like 'abc%'并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段 sex 中的 male 、 female 几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,索引最好不要超过6个
尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销
尽可能的使用 varchar 代替 char ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些
7、update更新两个表格内容
-- 查看需要修改的条目信息
SELECT
a.locationCode,
a.locationName AS '发货单',
b.locationName AS '原库位'
FROM
`t_purchase_order_receipt` a
JOIN `t_warehouse_position` b ON a.locationName <> b.locationName
WHERE
a.locationCode = b.locationCode;
-- 执行更改
UPDATE `t_purchase_order_receipt` a,
`t_warehouse_position` b
SET a.locationName = b.locationName
WHERE
a.locationCode = b.locationCode
AND a.locationName <> b.locationName;8、自定义拦截器
用于拦截未登录或授权的用户
/**
* 1、继承 HandlerInterceptorAdapter 抽象类
* 2、重写方法:
* preHandle:该方法将在Controller处理之前进行调用
* postHandle: 它的执行时间是在处理器进行处理之后,也就是在Controller的方法调用之后执行
* afterCompletion:该方法也是需要当前对应的Interceptor的preHandle方法的返回值为true时才会执行
*/
@Component
public class Test extends HandlerInterceptorAdapter {
public Test() {
super();
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
return super.preHandle(request, response, handler);
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
super.postHandle(request, response, handler, modelAndView);
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
super.afterCompletion(request, response, handler, ex);
}
@Override
public void afterConcurrentHandlingStarted(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
super.afterConcurrentHandlingStarted(request, response, handler);
}
} 9、Java中 :: 的作用
用来调用方法
Java 8 中我们可以通过 :: 关键字来访问类的构造方法,对象方法,静态方法
public class Test {
public static void printValur(String str) {
System.out.println("print value : " + str);
}
public static void main(String[] args) {
List<String> al = Arrays.asList("a", "b", "c", "d");
al.forEach(Test::printValur);
// 下面的方法和上面等价的
Consumer<String> methodParam = Test::printValur; // 方法参数
al.forEach(x -> methodParam.accept(x));// 方法执行accept
}
} 10、匹配map的键
Optional<String> key = map.keySet().stream().filter(e -> e.contains("退货")).findAny();
String s = key.get();
Object o = map.get(s);11、Hutool 读取Excel文件
官方文档:https://hutool.cn/docs/#/poi/Excel%E5%B7%A5%E5%85%B7-ExcelUtil
// 加载Excel表格
File file = FileUtil.file("C:\\Users\\12562\\Desktop\\退货数据批量导入模板.xlsx");
FileInputStream fi1 = new FileInputStream(file);
ExcelReader template = ExcelUtil.getReader(fi1, "批量导入模板");
// 读取内容
List<Map<String, Object>> templateList = template.readAll();
// 创建Mapper映射
public static final Map<String, String> TITLE_MAPPING = new HashMap<String, String>() { {
put("品类", "category");
put("收集日期", "collectDate");
put("市场分析", "analysisSummary");
put("分析详情", "analysisDetails");
put("行情策略", "strategySummary");
put("策略详情", "strategyDetails");
put("品种", "variety");
put("年份", "year");
put("产地省份", "productProvince");
put("产地市", "productCity");
put("最低出厂价(kg/元)", "lowestDeliverPrice");
put("最高出厂价(kg/元)", "highestDeliverPrice");
put("到货地省份", "arriveProvince");
put("到货地市", "arriveCity");
put("最低到货价(kg/元)", "lowestArrivePrice");
put("最高到货价(kg/元)", "highestArrivePrice");
put("备注", "remark");
} } ;
// 将内容转为Bean
ExportVo exportVo = BeanUtil.toBean(map, ExportVo.class, CopyOptions.create().setFieldMapping(TITLE_MAPPING));
// 忽略某些字段
ExportVo exportVo = BeanUtil.toBean(map, ExportVo.class, CopyOptions.create(ExportVo.class, false, "category", "status").setFieldMapping(TITLE_MAPPING));
// 根据两个字段进行分组
Map<Pair<LocalDate, CategoryEnum>, List<ExportVo>> collect = exportVoList.stream()
.collect(Collectors.groupingBy(ele -> new Pair<>(ele.getCollectDate(), ele.getCategory())));12、Stream()流的用法
// 将内容映射为 Map 的键值对
List<Map<String, Object>> templateList;
Map<Pair<Object, Object>, Triple<Object, Object, Object>> itemDict = itemList
.stream()
.collect(Collectors.toMap(e -> new Pair<>(e.get("对照方案名称"), e.get("品名(客户)"))
, e -> new Triple<>(e.get("料号(客户)"), e.get("料号(PMS)"), e.get("品名(PMS)"))));
// 获取内容
List<BatchRefundExcelDto> refundList;
for(BatchRefundExcelDto dto : refundList) {
Triple<Object, Object, Object> triple = itemDict.get(new Pair<>(dto.getControlScheme(), dto.getItemName()));
if(triple != null) {
dto.setOutCode(String.valueOf(triple.getX()));
dto.setSkuCode(String.valueOf(triple.getY()));
dto.setSkuName(String.valueOf(triple.getZ()));
}
}
// 按相同的值进行分组
Map<String, List<BatchRefundExcelDto>> collect = refundList
.stream()
.collect(Collectors.groupingBy(BatchRefundExcelDto::getRefundId));
// 匹配一个符合要求的键的值
Optional<String> key = map.keySet().stream().filter(e -> e.contains("xxx")).findAny();
Object o = map.get(key);13、根据文件名获取输入流
// 固有句式,后面可提升
if (StringUtils.contains(fileName, " ") || StringUtils.isEmpty(fileName)) {
return BaseRet.createFailResult(10000, "文件名称不合法");
}
String url = qiniuClient.getPrivateFileUrl(fileName);
InputStream inputStream = qiniuClient.getFileInputStream(url);14、将输入流转为字节数组
因为使用Hutool工具类读取Excel后,会自动关闭输入流导致无法读取多个工作表
// 复制输入流到字节输出流
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
IOUtils.copy(inputStream, byteArrayOutputStream);
byte[] bytes = byteArrayOutputStream.toByteArray();
// 将字节数组转为输入流
ExcelReader template = ExcelUtil.getReader(new ByteArrayInputStream(bytes), "批量导入模板");
ExcelReader item = ExcelUtil.getReader(new ByteArrayInputStream(bytes), "对照表管理(品名)");
ExcelReader body = ExcelUtil.getReader(new ByteArrayInputStream(bytes), "对照表管理(主体)");15、进行Map表格映射并转为Bean
使用Hutool工具类的BeanUtil.toBean() 方法,使
原始Map根据映射Map转换为Bean,其中映射Map的键为原始Map的键,而值为Bean中的变量名
// Person 类
class Person {
private String name,
private String age
}
// 原始Map
HashMap<String, Object> map = CollUtil.newHashMap();
map.put("a_name", "Joe");
map.put("b_age", 12);
// 映射Map:设置别名,用于对应bean的字段名
HashMap<String, String> mapping = CollUtil.newHashMap();
mapping.put("a_name", "name");
mapping.put("b_age", "age");
// 进行 toBean 转换
Person person = BeanUtil.toBean(map, Person.class, CopyOptions.create().setFieldMapping(mapping));通过映射的方式,就不需要频繁使用 map.get 方法获取值并调用setXxx方法。
16、创建API文档的方式
在对应的控制层上方添加
@Api注解@Api(tags = { "pc-退货处理"} )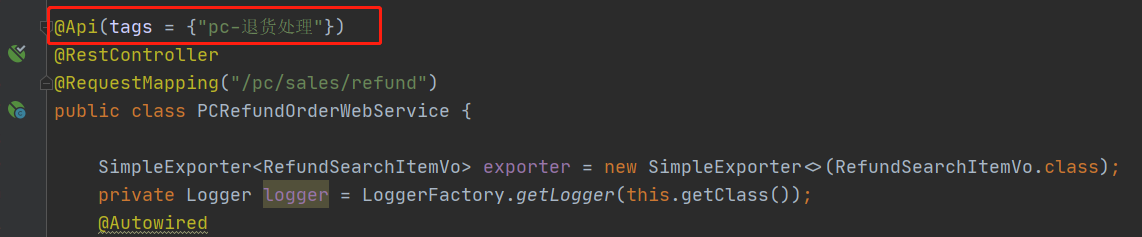
在对应的接口上方添加
@ApiOperation注解// value作为标签显示的内容,notes作为该Api的描述内容 @ApiOperation(value = "批量导入退货单", notes = "通过Excel批量导入退货单", httpMethod = "POST")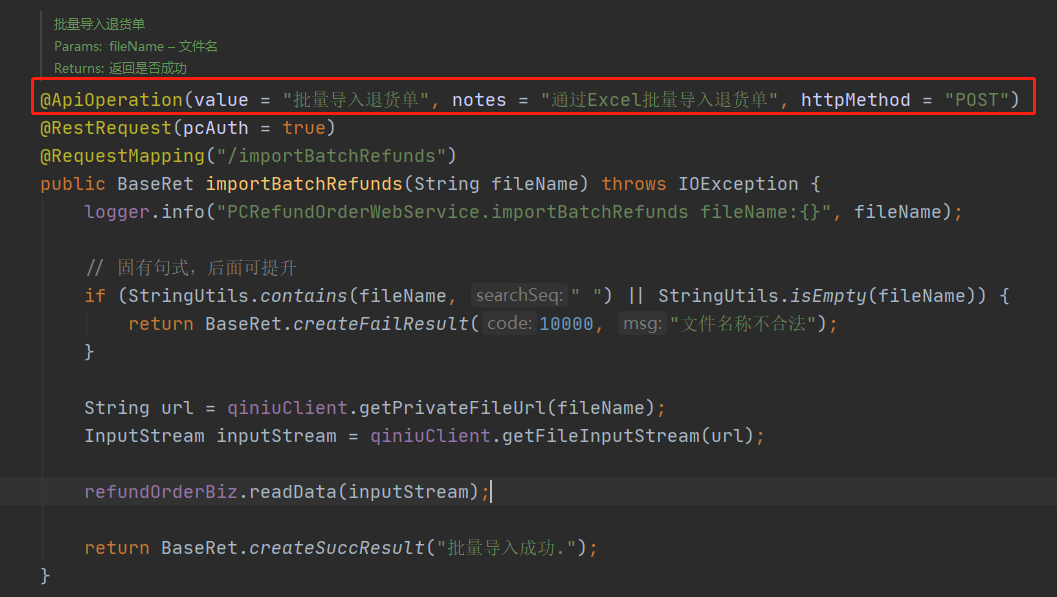
效果如下:
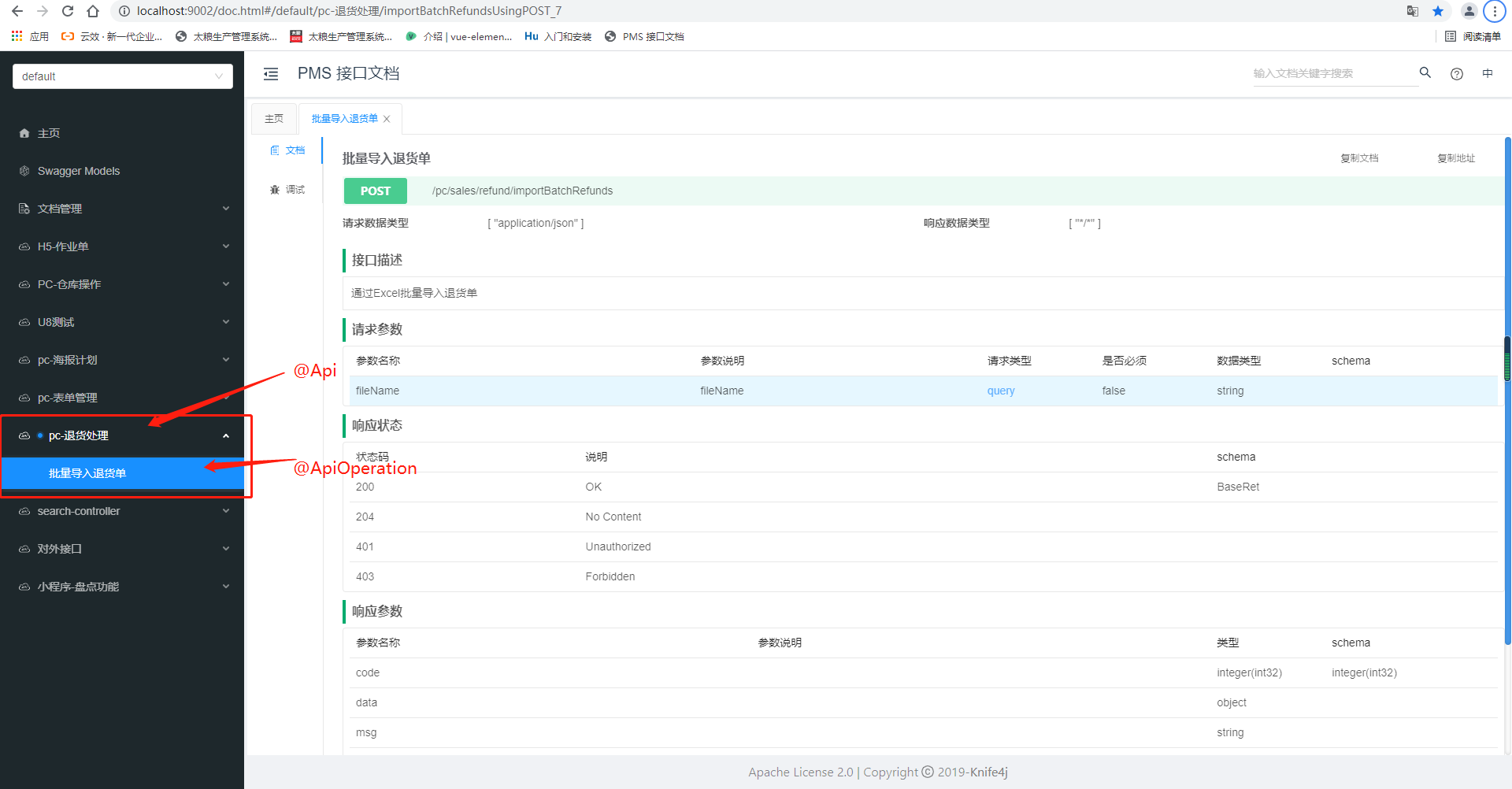
17、输出日志信息
logger.info("BarLoadRelationshipWebService.importData { } ", fileName);18、获取当天时间
ConversionFunction.Date.formatDate(LocalDate.now())19、获取当前登录的用户信息
BizUser user = ThreadData.getUser();20、增加事务回滚
在对应的方法上面添加注解
@Transactional(rollbackFor = Exception.class)21、拼接字符串
// 例子
String.format("料号【%s】不存在,请先补充或检查是否填写错误", barLoadRel.getMaterialCode())22、抛出异常
throw BaseRet.createFailResult(1111, errorList.toString()).toException();23、Wrappers的链式使用
// 例子
dingDepManageDao.delete(Wrappers.<DepManage>lambdaQuery()
.eq(DepManage::getRoleId, role.getId())
.orderByDesc(DepManage::getRoleId));24、修改日期格式
在po类上增加注解
@JsonFormat(pattern = "yyyy-MM-dd")
@ApiModelProperty(value = "票据日期")
private String invoiceDate;25、数值工具类NumberUtils
// 字符串转整型
int id = NumberUtils.toInt(str);26、Collectors.groupingBy分组顺序错误
之前直接使用一个参数进行分组,默认是使用HashMap的,而HashMap是无序的,所以不会按照顺序进行分组。
Collectors.groupingBy(BatchRefundExcelDto::getRefundId);使用LinkedHashMap进行分组即可
Collectors.groupingBy(BatchRefundExcelDto::getRefundId, LinkedHashMap::new, Collectors.toList());27、日志TraceId
作用
由于生产环境并发很大,每个请求之间的日志并不连贯,互相穿插。而traceId可以作为日志的一个唯一标识,用于分辨出哪些日志是哪个请求打印的。
MDC
- 日志追踪目标是每次请求级别的,也就是说同一个接口的每次请求,都应该有不同的traceId。
- 每次接口请求,都是一个单独的线程,所以自然我们很容易考虑到通过ThreadLocal实现上述需求。
- 考虑到log4j本身已经提供了类似的功能MDC,所以直接使用MDC进行实现。
关于MDC的简述
- Mapped Diagnostic Context,即:映射诊断环境。
- MDC是 log4j 和 logback 提供的一种方便在多线程条件下记录日志的功能。
- MDC 可以看成是一个与当前线程绑定的哈希表,可以往其中添加键值对。
关于MDC的关键操作
- 向MDC中设置值:
MDC.put(key, value); - 从MDC中取值:
MDC.get(key); - 将MDC中内容打印到日志中:
%X{ key}
实现方法
采用过滤器的形式,即:自定义一个Filter,继承自GenericFilterBean
实现步骤
1、创建自定义过滤器
@Component
@Slf4j
public class TraceFilter extends OncePerRequestFilter {
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
MDC.put("traceId", getTraceId());
filterChain.doFilter(request, response);
}
private String getTraceId() {
long timestamp = System.currentTimeMillis();
UUID uuid = UUID.randomUUID();
String uniqueId = timestamp + uuid.toString().replace("-", "");
return uniqueId;
}
} 2、在 logback.xml 配置文件中修改日志输出格式,使用 %X{ traceId} 获取tranceId
<appender name="console"
class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>[%date{ HH:mm:ss.SSS} ] %X{ traceId} [%thread] [%-5level] [%logger{ 36} ] %msg%n</pattern>
</encoder>
</appender>28、SpringBoot的AOP
相关概念
- Aspect(切面): Aspect 声明类似于 Java 中的类声明,在 Aspect 中会包含着一些 Pointcut 以及相应的 Advice
- Joint point(连接点):表示在程序中明确定义的点,典型的包括方法调用,对类成员的访问以及异常处理程序块的执行等等,它自身还可以嵌套其它 joint point
- Pointcut(切点):用来描述和指定Join point。表示一组 Joint point,这些 joint point 或是通过逻辑关系组合起来,或是通过通配、正则表达式等方式集中起来,它定义了相应的 Advice 将要发生的地方
- Advice(增强):Advice 定义了在 Pointcut 里面定义的程序点具体要做的操作,它通过 before、after 和 around 来区别是在每个 joint point 之前、之后还是代替执行的代码
- Target(目标对象):织入 Advice 的目标对象
- Weaving(织入):将 Aspect 和其他对象连接起来, 并创建 Adviced object 的过程
Advice 的类型
@before :在 join point 前被执行的 advice. 虽然 before advice 是在 join point 前被执行, 但是它并不能够阻止 join point 的执行, 除非发生了异常(即我们在 before advice 代码中, 不能人为地决定是否继续执行 join point 中的代码)
@AfterReturning:在一个 join point 正常返回后执行的 advice
@AfterThrowing:当一个 join point 抛出异常后执行的 advice
@After:无论一个 join point 是正常退出还是发生了异常, 都会被执行的 advice
@Around:在 join point 前和 joint point 退出后都执行的 advice. 这个是最常用的 advice
切入点表达式关键词用例:
1)execution:用于匹配子表达式。
@Pointcut(“execution(* com.cjm.model...(..))”)
public void before(){ } 2)within:用于匹配连接点所在的Java类或者包。
// 匹配Person类中的所有方法
@Pointcut(“within(com.cjm.model.Person)”)
public void before(){ }
// 匹配com.cjm包及其子包中所有类中的所有方法
@Pointcut(“within(com.cjm..*)”)
public void before(){ } 最简单的使用
@Aspect
@Component
public class Test {
@Before("execution(* com.tl.provider.sale.service.SaleService.*(..))")
public void before() {
// 执行前置操作
}
} 29、Logback的使用
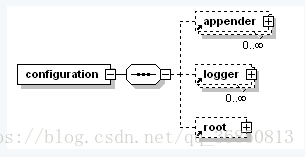
根节点
<configuration>
- scan: 当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true
- scanPeriod: 设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。默认的时间间隔为1分钟
- debug: 当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false
<configuration scan="true" scanPeriod="60 seconds" debug="false">
<!--其他配置省略-->
</configuration> 设置上下文名称
<contextName>
<contextName>myAppName</contextName> 设置变量
<property>
name的值是变量的名称,value的值时变量定义的值
<property name="APP_Name" value="myAppName" />子节点
<appender>
负责写日志的组件,它有两个必要属性name和class,参考文章:https://www.cnblogs.com/lijia0511/p/5680300.html
- name:appender名称
- class:appender的全限定名,例如 ConsoleAppender 输出到控制台,RollingFileAppender 滚动输出到日志文件, FileAppender 直接添加到日志文件
<encoder>:对日志进行格式化。<target>:字符串System.out(默认)或者System.err
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%-4relative [%thread] %-5level %logger{ 35} - %msg %n</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="STDOUT" />
</root>
</configuration>父节点
<root>
用于添加子节点
<root level="INFO">
<!-- 将日志内容应用到指定appender -->
<appender-ref ref="STDOUT" />
</root>
<loger>
用来设置某一个包或者具体的某一个类的日志打印级别、以及指定<appender>,或者将指定包的内容输出到指定文件中。
<loger>有一个name属性,一个可选的level和一个可选的addtivity属性
- name:用来指定受此loger约束的某一个包或者具体的某一个类
- level:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF,还有一个特俗值INHERITED或者同义词NULL,代表强制执行上级的级别
- addtivity:是否向上级loger传递打印信息。默认是true
<logger name="access" level="INFO" additivity="false">
<!-- 将 access 类的日志内容应用到指定appender -->
<appender-ref ref="access" />
</logger>保存日志
<rollingPolicy >
class 属性用于指定滚动策略
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"是 最常用的滚动策略,它根据时间来制定滚动策略,既负责滚动也负责出发滚动
<fileNamePattern>:必要节点,包含文件名及“%d”转换符,“%d”可以包含一个java.text.SimpleDateFormat指定的时间格式,如:%d{yyyy-MM}<maxHistory>:可选节点,控制保留的归档文件的最大数量,超出数量就删除旧文件
<!-- 运行日志,class必须指向RollingFileAppender -->
<appender name="run"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${ path} /run.%d{ yyyy-MM-dd} .log</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern>[%date{ HH:mm:ss.SSS} ] [%thread] [%-5level] [%logger{ 36} ] %msg%n</pattern>
</encoder>
</appender>配置案例
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="60 seconds"
debug="false">
<contextName>jweb_tl_pms</contextName>
<property name="path" value="/data/jweblog/jweb_tl_pms" />
<!-- 控制台 -->
<appender name="console"
class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>[%date{ HH:mm:ss.SSS} ] [%thread] [%-5level] [%logger{ 36} ] %msg%n</pattern>
</encoder>
</appender>
<!-- 访问日志 -->
<appender name="access"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${ path} /access/access.%d{ yyyy-MM-dd} .log
</fileNamePattern>
<maxHistory>3</maxHistory>
</rollingPolicy>
<encoder>
<pattern>[%date{ HH:mm:ss.SSS} ] [%thread] [%-5level] [%logger{ 36} ] %msg%n</pattern>
</encoder>
</appender>
<!-- 运行日志 -->
<appender name="run"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${ path} /run.%d{ yyyy-MM-dd} .log</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern>[%date{ HH:mm:ss.SSS} ] [%thread] [%-5level] [%logger{ 36} ] %msg%n</pattern>
</encoder>
</appender>
<!-- 错误日志 -->
<appender name="error"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<rollingPolicy
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${ path} /error.%d{ yyyy-MM-dd} .log</fileNamePattern>
<maxHistory>21</maxHistory>
</rollingPolicy>
<encoder>
<pattern>[%date{ HH:mm:ss.SSS} ] [%thread] [%-5level] [%logger{ 36} ] %msg%n</pattern>
</encoder>
</appender>
<!-- 访问日志 -->
<logger name="access" level="INFO" additivity="false">
<appender-ref ref="access" />
</logger>
<logger name="com.tl" level="DEBUG">
</logger>
<root level="INFO">
<appender-ref ref="run" />
<appender-ref ref="error" />
<appender-ref ref="console" />
</root>
</configuration>输出日志
public class Test {
private static Logger logger = LoggerFactory.getLogger(Test.class);
public static void main(String[] args) {
String hello = "hello world";
logger.info("test: { } ", hello);
}
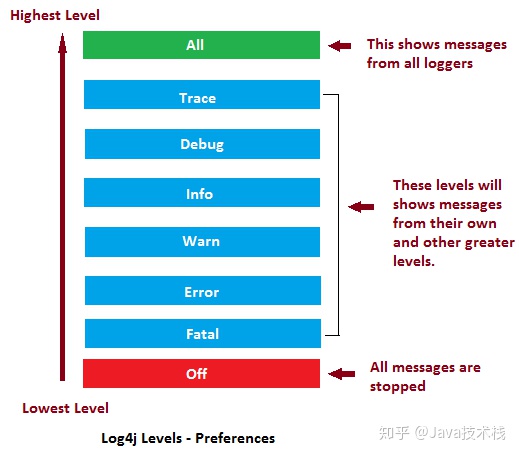
} 30、日志级别
ALL < TRACE < DEBUG < INFO < WARN < ERROR < FATAL < OFF
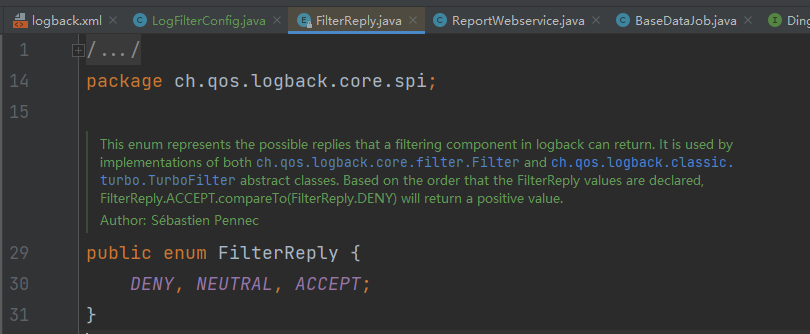
31、自定义日志过滤器
过滤器返回参数有 DENY,NEUTRAL,ACCEPT。
- DENY,日志将立即被抛弃不再经过其他过滤器
- NEUTRAL,有序列表里的下个过滤器过接着处理日志
- ACCEPT,日志会被立即处理,不再经过剩余过滤器
实现步骤
1、继承Filter<ILoggingEvent>,重写 decide 方法,并指定要过滤的类
package com.tl.common.config;
import ch.qos.logback.classic.spi.ILoggingEvent;
import ch.qos.logback.core.filter.Filter;
import ch.qos.logback.core.spi.FilterReply;
public class LogBackFilter extends Filter<ILoggingEvent> {
@Override
public FilterReply decide(ILoggingEvent event) {
// 指定打印日志类
if (event.getLoggerName().contains("com.tl.modules.purchase.report.webservice")) {
return FilterReply.DENY;
} else {
return FilterReply.ACCEPT;
}
}
} 2、在对应的日志配置中加上过滤器
<!-- 控制台 -->
<appender name="console"
class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>[%date{ HH:mm:ss.SSS} ] [%thread] [%-5level] [%logger{ 36} ] %msg%n</pattern>
</encoder>
<!-- 引用自定义过滤器 -->
<filter class="com.tl.common.config.LogBackFilter"/>
</appender>32、请求拦截器
继承 HandlerInterceptorAdapter 类
@Component
public class LogInterceptor extends HandlerInterceptorAdapter {
/**
* Log the request entrance
*/
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
}
/**
* Log the request finished
*/
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler,
ModelAndView modelAndView) {
}
/**
* Log the request exit
*/
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
}
} 33、搜索网站的内容
1、使用必应搜索:https://cn.bing.com/
2、输入搜索内容
# site:<网站> <搜索内容>
site:docs.spring.io application event34、注解service和component的区别
- @Service用于标注业务层组件
- @Controller用于标注控制层组件(如struts中的action)
- @Repository用于标注数据访问组件,即DAO组件
- @Component泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注
35、SpringBoot事件发布与监听
1、创建事件,继承ApplicationEvent
public class DingEvent extends ApplicationEvent {
private final String evenType;
private final JSONObject content;
public DingEvent(Object source, String evenType, JSONObject content) {
super(source);
this.evenType = evenType;
this.content = content;
}
public String getEvenType() {
return evenType;
}
public JSONObject getContent() {
return content;
}
} 2、创建发布器,实现ApplicationEventPublisherAware
@Component
public class DingPublisher implements ApplicationEventPublisherAware {
private ApplicationEventPublisher publisher;
@Override
public void setApplicationEventPublisher(ApplicationEventPublisher applicationEventPublisher) {
this.publisher = applicationEventPublisher;
}
/**
* 发布事件
*/
public void sendDingEvent(String evenType, JSONObject content) {
publisher.publishEvent(new DingEvent(this, evenType, content));
}
} 3、定义监听器,可以继承ApplicationListener<BlockedListEvent>接口,也可以直接在方法上增加@EventListener注解(condition可以增加监听条件)
@Service
public class BlockedListNotifier {
Logger logger = LoggerFactory.getLogger(BlockedListNotifier.class);
@Autowired
private DingInfoBiz dingInfoBiz;
/**
* 监听钉钉用户信息变更
*/
@EventListener(condition = "#event.evenType.startsWith('user')")
public void onModifyUserEvent(DingEvent event) throws ApiException {
logger.info("BlockedListNotifier.onAddressBookEvent onModifyUserEvent:{ } ", JSON.toJSONString(event));
dingInfoBiz.updateUser(event.getEvenType(), event.getContent().getString("UserId"));
}
} 监听器方法默认为同步
事件侦听器同步接收事件。这意味着publishEvent()方法将一直阻塞,直到所有侦听器都处理完事件。这种同步单线程方法的一个优点是,当侦听器接收到事件时,如果事务上下文可用,它将在发布服务器的事务上下文中操作。
而加上@Async注解可以让监听方法变为异步
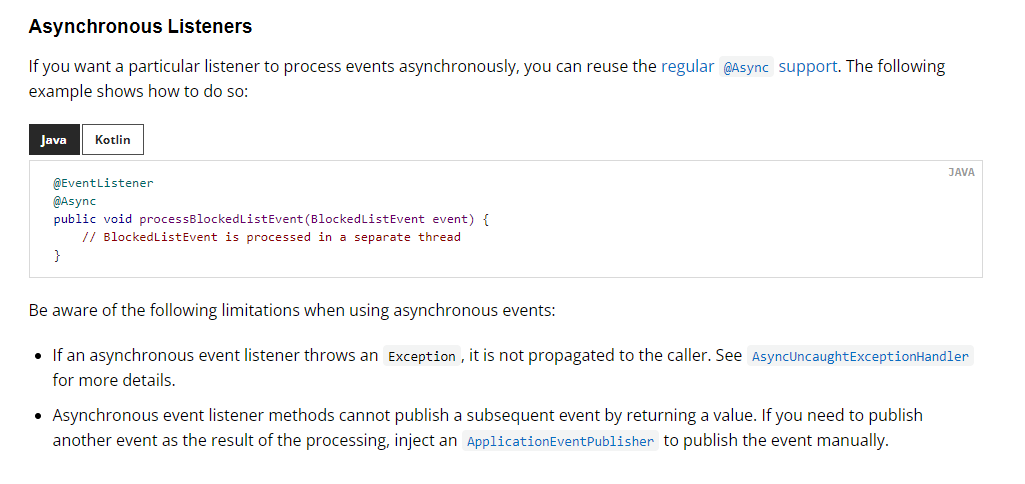
36、Java使用正则表达式
String s = "[\"15504563517131058\",\"15504563517131057\"]";
Pattern pattern = Pattern.compile("[0-9]+");
Matcher matcher = pattern.matcher(s);
// 只有matcher.find()为true的时候,才能输出内容
while(matcher.find()) {
System.out.println(matcher.group());
} 37、枚举的使用
public enum MyEnum {
VALUE1(100),
VALUE2(200),
VALUE3(300);
private final Integer value;
MyEnum(Integer value) {
this.value = value;
}
public Integer getValue() {
return value;
}
}
// 获取枚举的值
public class Test1 {
@Test
public void test1() {
System.out.println(MyEnum.VALUE1.getValue());
}
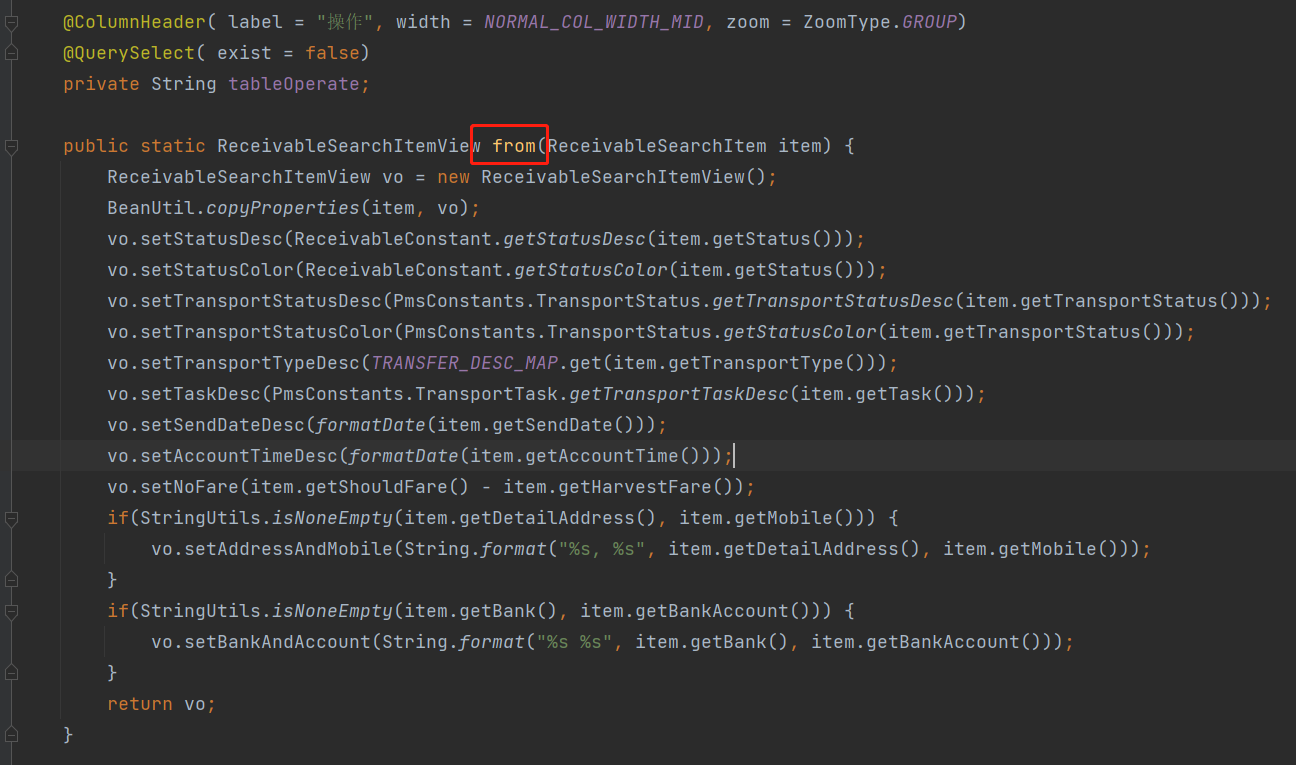
} 38、分页查询后将对象封装为vo
使用convert()方法
@Override
public IPage<ReceivableSearchItem> search(Page<ReceivableSearchItem> page,
Collection<SearchQuery> queries,
Collection<SearchQuery> groups,
Collection<SearchQuery> orders) {
commonDefaultHandle(queries, groups, orders);
IPage<ReceivableSearchItem> result = commonSearch(page, queries, groups, orders);
return result.convert(ReceivableSearchItemView::from);
} 
39、LocalDate格式化
LocalDate date = LocalDate.now();
date.format(DateTimeFormatter.ISO_DATE);40、Java请求
// 封装请求参数
QueryParam params = QueryParam.create()
.add("id", u8code)
.add("toAccount", toAccount)
.add("accountNo",subject);
Request request = new Request.Builder().url(params.catURL(url)).get().build();
// 进行请求
OkHttpClient client = new OkHttpClient.Builder()
//设置读取超时时间
.readTimeout(20, TimeUnit.MINUTES)
//设置写的超时时间
.writeTimeout(20, TimeUnit.MINUTES)
//设置连接超时时间
.connectTimeout(1, TimeUnit.MINUTES)
.build();
String body = client.newCall(request).execute().body().string();41、获取月初或者月末
// 获取月初
LocalDate first = LocalDate.now().with(TemporalAdjusters.firstDayOfMonth());
// 获取这个月最后一天的日期对象
LocalDate last = LocalDate.now().with(TemporalAdjusters.lastDayOfMonth());2、前端内容
1、SCSS的基本内容
Sass就是css的预处理器,Scss是Sass3版本中引入的新语法特性
vue中使用scss,安装:
cnpm i -S node-sass sass-loader使用方法:
<style lang="scss"> </style>支持定义变量,内容嵌套等内容
参考文章:https://blog.csdn.net/qq_40323256/article/details/109138173
中文文档:https://www.sass.hk/docs/
2、切换分支
git checkout [分支名]3、Vue的8个钩子函数
- beforeCreate:创建前执行
- created:创建后执行
- beforeMount:挂在前执行
- Mount:挂在后执行
- beforeUpdate:data() 中的数据更新前执行
- updated:data() 中的数据更新后执行
- beforeDestory:销毁前执行
- destoryed:销毁后执行

4、Vue修改引用对象的属性值
// 定义一个引用对象
data() {
return {
peple: [
{
name: '小明',
age: 18
} ,{
name: '小红',
age: 19
}
]
}
}
// 需要在一个函数中修改小明的年龄
this.peple[0].age = 19; // 这样可以修改 data() 中的数据,但是<templete>中的内容不一定会跟着改变
this.$set(this.peple[0], age, 19); // 这样既可以修改 data() 中的数据,也可以让渲染的内容随着更新5、Chrome浏览器安装Vue插件
打开Github地址:https://github.com/vuejs/vue-devtools/tree/v5.1.1
下载压缩包到本地,然后解压
在文件路径下执行如下命令
npm install npm run build然后进入
shell -> chrome目录,修改manifest.json文件,将persistent设置为true即可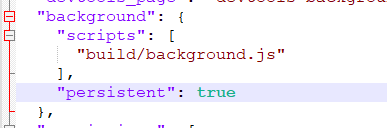
在chrome浏览器中选择
chrome文件进行导入插件打开使用
Vue框架搭建的项目即可看到插件图标被点亮
打开开发者模式就可以查看Vue的一些信息了(不过可能是b站的vue文件经过打包了,看不到下方信息)
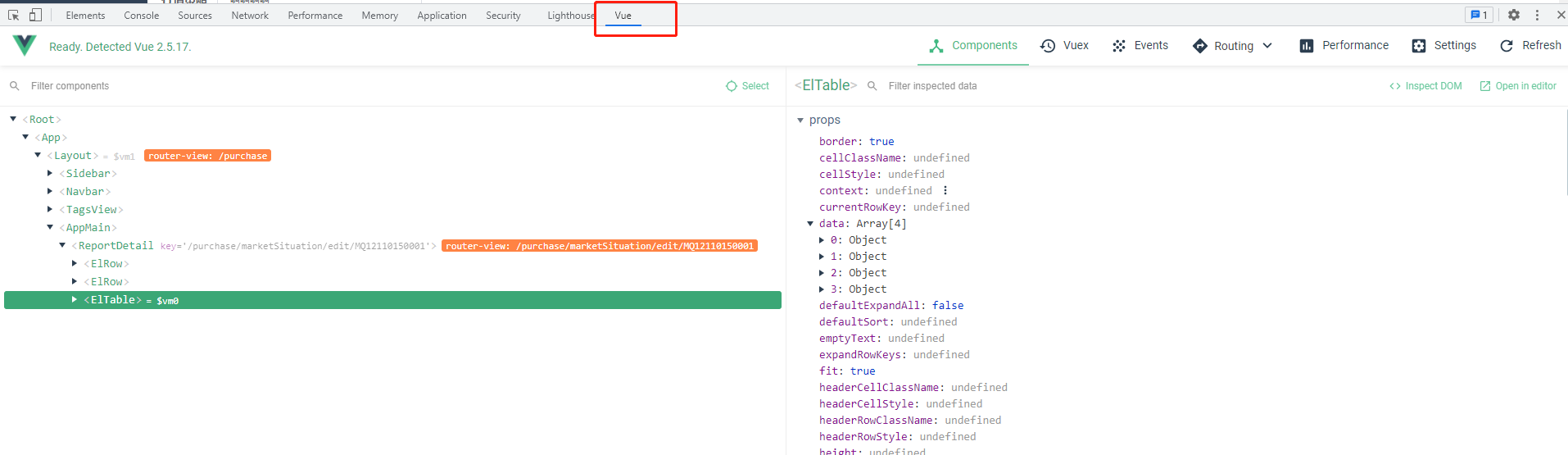
6、1 - 0.9 不等于 0.1 的问题
分析
因为精度问题,js所有的数字都是以IEEE-754标准格式表示的。所以比如 1.1,其程序实际上无法真正的表示 ‘1.1’,而只能做到一定程度上的准确,这是无法避免的精度丢失:1.09999999999999999。
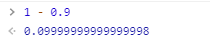
所以就会导致一些神奇的现象
console.log(1.0-0.9 == 0.1) //false
console.log(1.0-0.8 == 0.2) //false
console.log(1.0-0.7 == 0.3) //false
=====================================
console.log(1.0-0.6 == 0.4) //true
console.log(1.0-0.5 == 0.5) //true
console.log(1.0-0.4 == 0.6) //true
console.log(1.0-0.3 == 0.7) //true
console.log(1.0-0.2 == 0.8) //true
console.log(1.0-0.1 == 0.9) //true方法
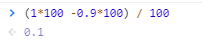
方法一:
将小数的计算变为整数计算
方法二:
使用
toFixed进行四舍五入(1 - 0.9).toFixed(2); // 保留小数点后两位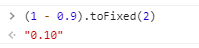
7、安装淘宝镜像cnpm
npm install -g cnpm -registry=https://registry.npm.taobao.org8、使用npm删除文件
安装工具
npm install rimraf -g删除文件
rimraf node_modules9、错误收集
cnpm问题
cnpm : 无法加载文件 C:\Users\oor\AppData\Roaming\npm\cnpm.ps1,因为在此系统上禁止运行脚本。...搜索PowerShell以管理员身份运行
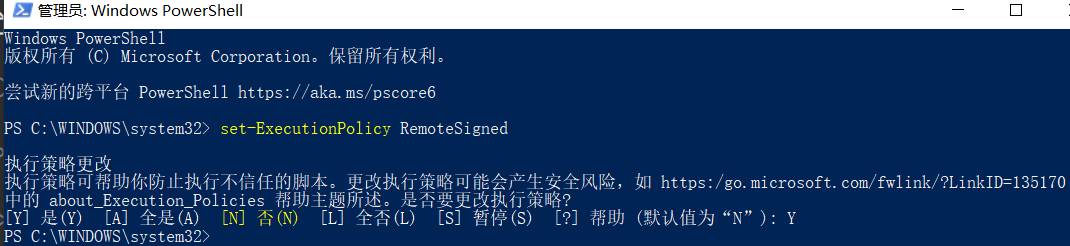
输入set-ExecutionPolicy RemoteSigned,选择Y 或者A ,就好了

10、Vue父组件调用子组件方法
在子组件上增加
ref属性<logs-tab-pane :id="current.id + ''" :type="logType" ref="logsTab"></logs-tab-pane>直接调用子组件方法
this.$refs.logsTab.getLogs();不过这样子调用可能会出现数据滞后的问题,也就是
getlog()方法使用的 id 还是上一次传进去的值使用异步更新方法
if (this.$refs.logsTab) { // $nextTick 可以进行异步更新, this.$nextTick(() => { this.$refs.logsTab.getLogs(); } ); }
11、ajax设置请求头
ajax({
url: '/pc/logistics/cost/submitDingAudit',
method: 'POST',
beforeSend: function (request) {
request.setRequestHeader('contentType', 'application/json');
} ,
data: params
} ).then(
// 请求成功的处理
(res) => {
const { msg } = res;
this.$message.success(msg);
} ,
// 请求失败的处理
() => {
this.loading = false;
}
);12、vue的change事件携带参数
@change="selectCustomer($event, item)"13、vuex发送请求
1、在store目录下分别创建两个对应的.js文件
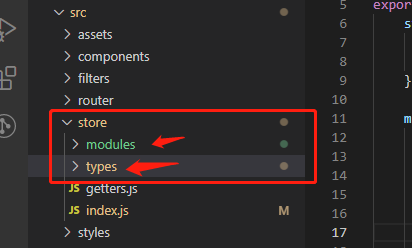
2、在modules目录下的js文件编写功能代码
import Vue from 'vue';
import ajax from '@/utils/ajax';
import * as Types from '@/store/types/index';
export default {
state: { } ,
mutations: {
[Types.UPDATE_TRANSPORT2_STATE](state, payload) {
for (let key in payload) {
if (typeof payload[key] !== 'undefined') {
Vue.set(state, key, payload[key]);
}
}
}
} ,
actions: {
[Types.GET_TRANSPORT2_DETAIL]({ commit } , { transportId } ) {
return ajax({
url: '/pc/logistics/transport/getDetail',
method: 'POST',
data: { id: transportId }
} ).then(
(res) => {
return Promise.resolve(res);
} ,
(res) => {
return Promise.reject(res);
}
);
}
}
} 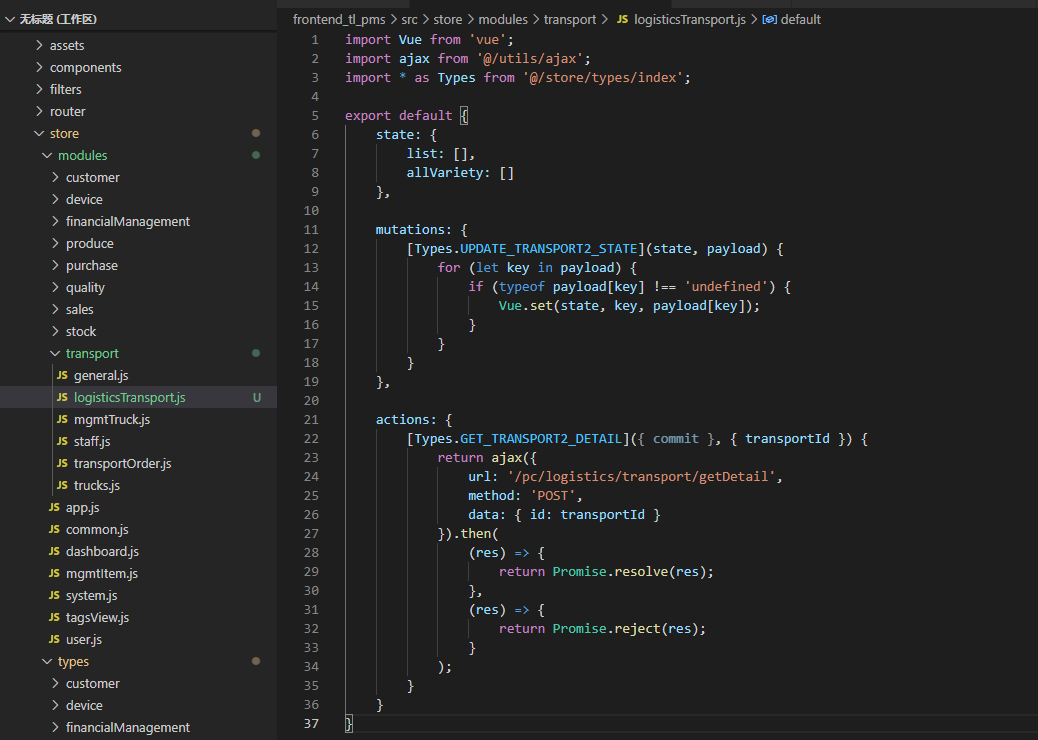
3、在types目录下的js文件编写action事件
/* mutation */
export const UPDATE_TRANSPORT2_STATE = 'UPDATE_TRANSPORT2_STATE';
/* action */
export const GET_TRANSPORT2_DETAIL = 'GET_TRANSPORT2_DETAIL';4、在types目录下的index.js中引入文件
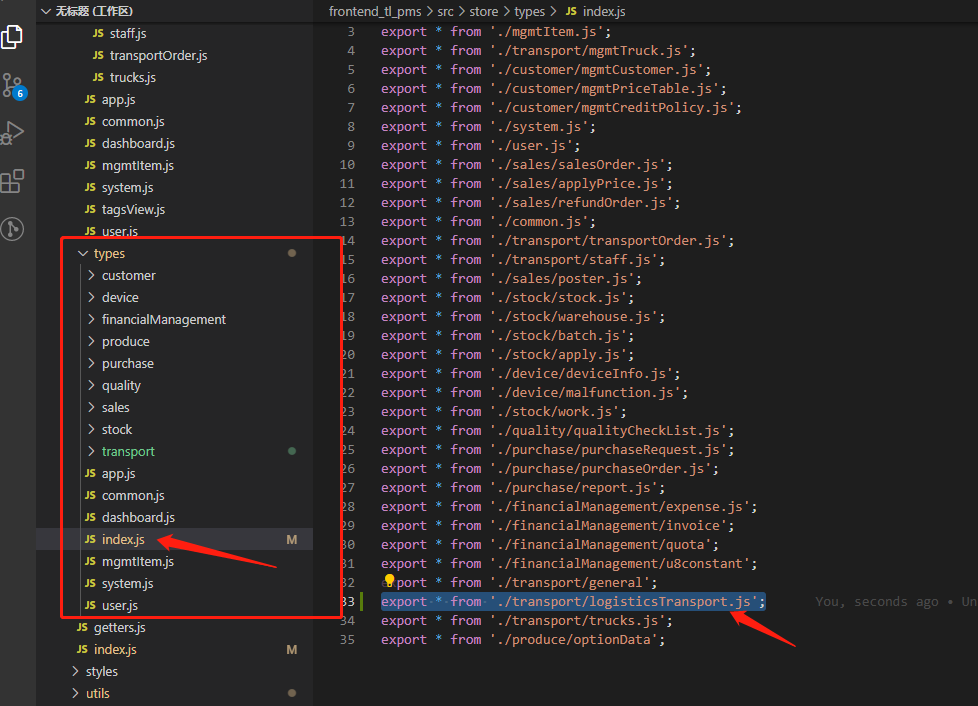
5、在modules目录下的index.js文件暴露这个vuex
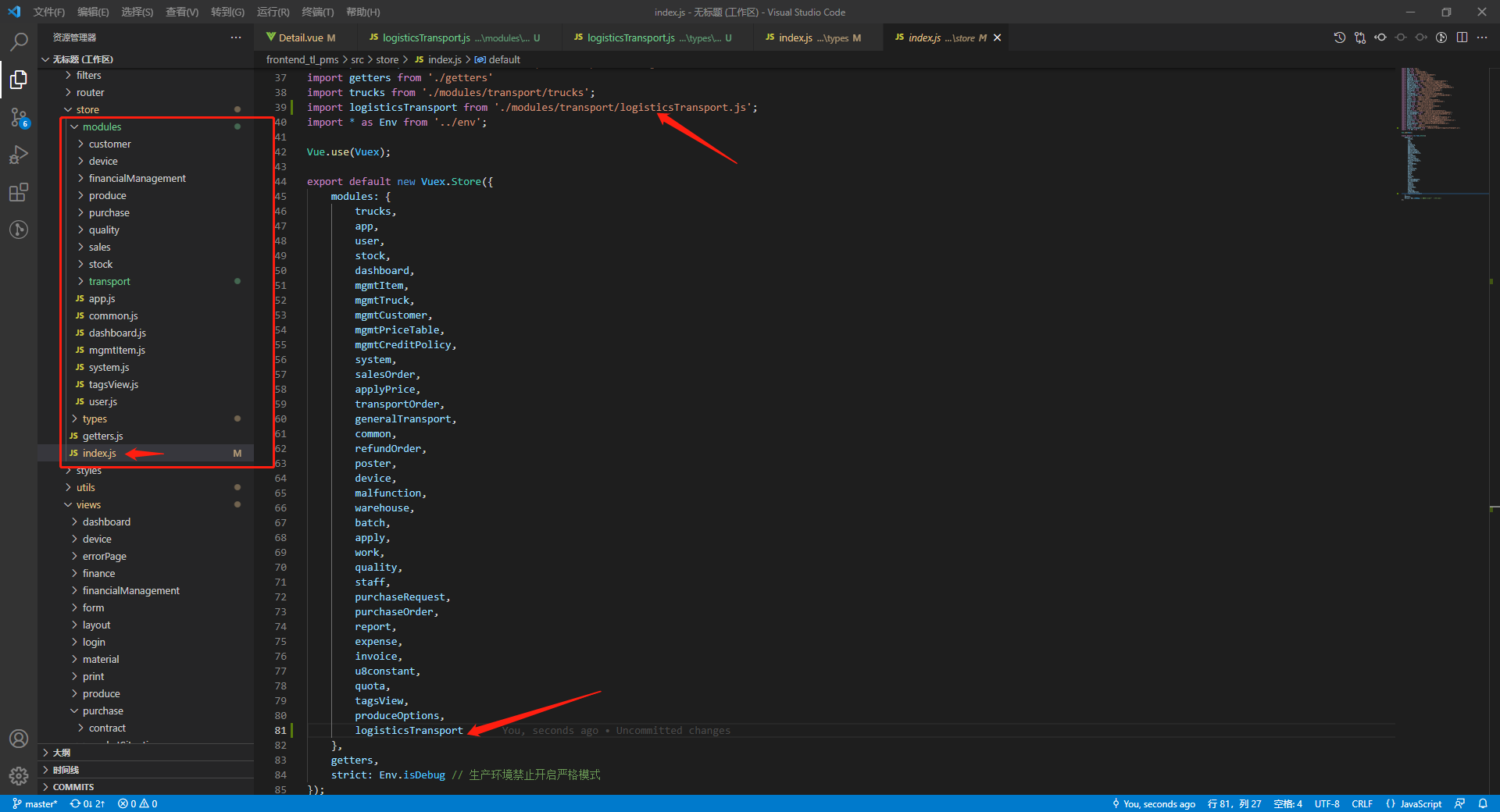
14、数值格式化
export function formatPrice(money, zeroNumber = 2) {
let s = money.toFixed(zeroNumber);
/**正则判断**/
while (/\d{ 4} (\.|,)/.test(s)) {
s = s.replace(/(\d)(\d{ 3} (\.|,))/, "$1,$2"); /**每隔3位添加一个**/
}
return s;
} 15、vscode识别不到npm
场景:在vscode中无法识别npm,而在外面的终端中可以输出npm信息
原因:这是在安装vscode之后就打开了它的终端,所以每次进入都是那个终端,所以无法识别到后来安装的nodejs
解决方法:直接重新打开一个vscode的终端即可
16、node-sass 安装失败
依次执行下方命令即可
npm uninstall node-sass
npm i node-sass –sass_binary_site=https://npm.taobao.org/mirrors/node-sass/
3、运维内容
1、修改文件权限
chmod 777 [文件名]2、使用Nginx配置证书
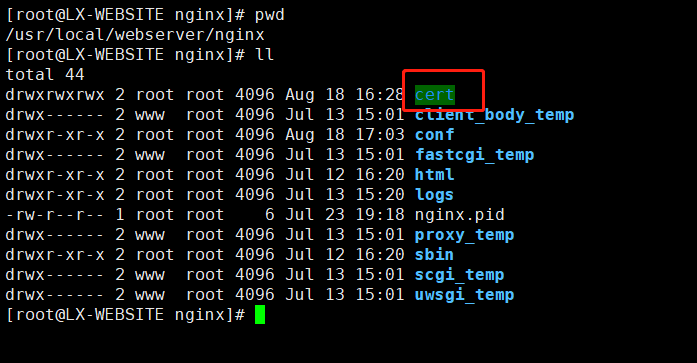
下载证书
将证书上传到服务器上,一般与配置文件同级目录下创建 cert 文件夹
查询文件位置的方式
ps -ef | grep nginx修改配置文件,一般在conf文件下
http { upstream jweb_tl_data { server 10.104.194.110:9007; } server { listen 80; listen [::]:80; server_name [网站域名]; return 301 https://[网站域名]; # 配置重定向 } server { listen 443 ssl; server_name [网站域名]; index index.html; gzip on; gzip_min_length 1k; gzip_comp_level 5; gzip_types text/plain application/x-javascript text/css application/xml application/javascript application/json; ssl_certificate [证书文件 .crt=]; ssl_certificate_key [证书密钥文件 .key]; ssi on; ssi_silent_errors on; ssi_types text/shtml; # 主页访问地址,因为使用的是静态的html网页,所以直接使用location就可以完成了。 location / { # 文件夹 root /usr/local/xiaojiang/webstatic/; # 主页文件 index index.html; } } }重启Nginx服务
./nginx -s reload
报错:
nginx: [emerg] the "ssl" parameter requires ngx_http_ssl_module in /usr/local/nginx/conf/conf.d/myweb_beta.conf:13这是因为ssl模块并未被安装
3、拷贝文件夹
# 需要加上-r
cp -r [文件夹] [目的地]4、新的测试环境搭建
环境配置
- JDK
- 安装命令:
yum install java-1.8.0-openjdk.x86_64 - 检测命令:
java -version
- 安装命令:
- Maven
- 安装命令:
yum install maven - 检测命令:
mvn -v
- 安装命令:
- Node
- 安装命令:
yum install nodejs - 检测命令:
npm -v
- 安装命令:
- pm2
- 前置条件:需要安装 Node
- 安装命令:
npm install pm2 -g
后端配置
克隆后端项目
cd /usr/local/jweb git clone https://codeup.aliyun.com/5fb25659e89148238ce80ead/tailiang/jweb_tl_pms.git jweb_tl_pms2拷贝
build.sh、jmxremote、java_pid4845.hprof和.mvn文件cd /usr/local/jweb/jweb_tl_pms cp -r build.sh ../jweb_tl_pms_test/ cp -r jmxremote ../jweb_tl_pms_test cp -r java_pid4845.hprof ../jweb_tl_pms_test cp -r .mvn ../jweb_tl_pms_test
赋予
mvnw权限chmod 777 mvnw创建日志存放目录以及软连接
# 创建日志目录 cd /data/jweblog mkdir jweb_tl_pms2 cd jweb_tl_pms2 mkdir access # 创建软链接 cd /usr/local/jweb/jweb_tl_pms2 ln -s /data/jweblog/jweb_tl_pms2 logs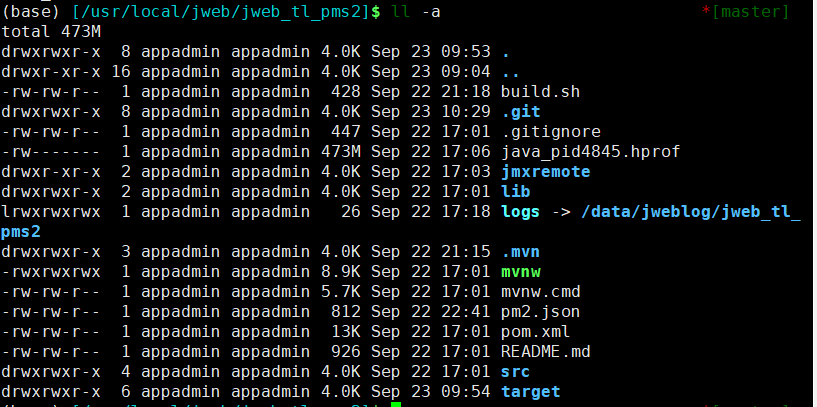
创建备份文件目录
cd /data/backup mkdir jweb_pms2
修改配置文件
修改
build.sh文件,只需要修改备份文件位置,和pm2的应用名称# 拉取最新代码 # git pull https://gitee.com/tailiang/jweb_tl_pms.git git pull # 删除1天以前备份文件(修改) location="/data/backup/jweb_pms2/" fileName=`date +%Y%m%d%H%M%S` path="${ location} ${ fileName} .jar" # echo "start copy to ${ path} !" find $location -mtime +1 -type f |xargs rm -f # 备份.jar文件 cp ./target/*.jar ${ path} # 打包和重启(修改) ./mvnw clean package -Dmaven.test.skip=true pm2 restart jweb_tl_pms2修改
pm2.json文件{ // 应用名称 "name": "jweb_tl_pms2", "script": "/usr/bin/java", // 设置项目启动的参数,需要修改active "args": [ "-Xms128m", "-Xmx512m", "-XX:PermSize=128m", "-XX:MaxNewSize=256m", "-XX:MaxPermSize=128m", "-XX:+HeapDumpOnOutOfMemoryError", "-XX:+UseParallelGC", "-XX:+UseParallelOldGC", "-jar", "target/jweb_tl_pms-1.0.0-SNAPSHOT.jar", "--spring.profiles.active=beta2" ], "exec_interpreter": "", "exec_mode": "fork" }修改
.git的config文件,否则其他人无法进行git操作cd /usr/local/jweb/jweb_tl_pms cp .git/config ../jweb_tl_pms2/.git
项目配置—IDEA
增加配置文件
application-test.yml,并复制粘贴上beta的文件内容,然后修改服务端口,增加配置日志,关闭定时任务# 修改服务端口 server: address: 0.0.0.0 port: 9012 # 修改注册中心端口,-1为随机分配 dubbo: protocol: port: -1 # 配置日志文件 logging: config: classpath:logback-beta2.xml创建日志文件
logback-test.xml,复制粘贴logback.xml的内容,然后修改path路径<property name="path" value="/data/jweblog/jweb_tl_pms2" />将项目上传到云效上
服务器启动
打包项目
# 打包并跳过测试(因为测试时间好长啊啊啊) mvn package -Dmaven.test.skip=true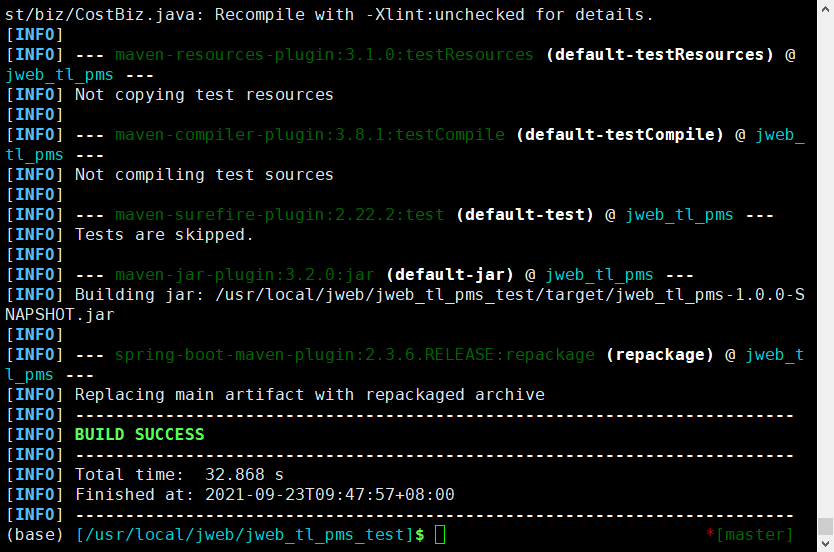
拉取最新代码
git pull启动pm2项目
pm2 start pm2.json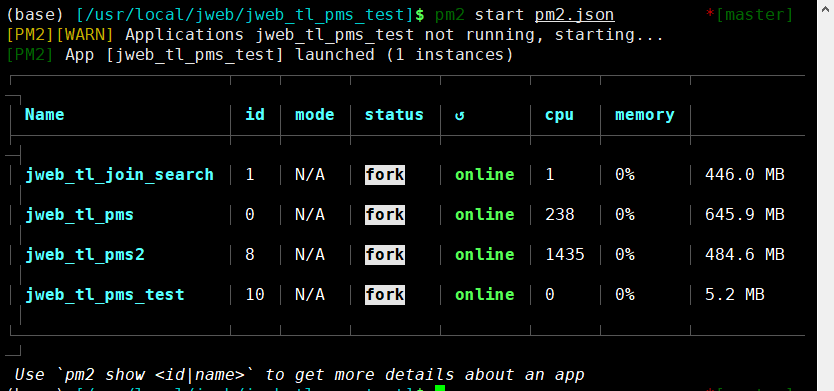
此致,后面的更新均可直接执行
sh builid.sh
前端配置
配置
nginx配置文件,复制粘贴tl_pms.conf文件内容cd /etc/nginx/conf.d touch tl_pms2.conf修改配置文件
# 配置项目端口 upstream jweb_tl_pms { server 127.0.0.1:9012; } server { # 设置域名 server_name beta2.pms.tailiangwx.com; # 修改前端项目的存放路径 location =/ { root /data/webstatic/pms2/; index index.html; } …… }创建前端目录
cd /data/webstatic mkdir pms2拷贝
dingh5文件夹到目录下cd /data/webstatic/pms cp -r ./dingh5 ../pms2
前端项目配置——VsCode
修改
package.json文件,增加test打包方式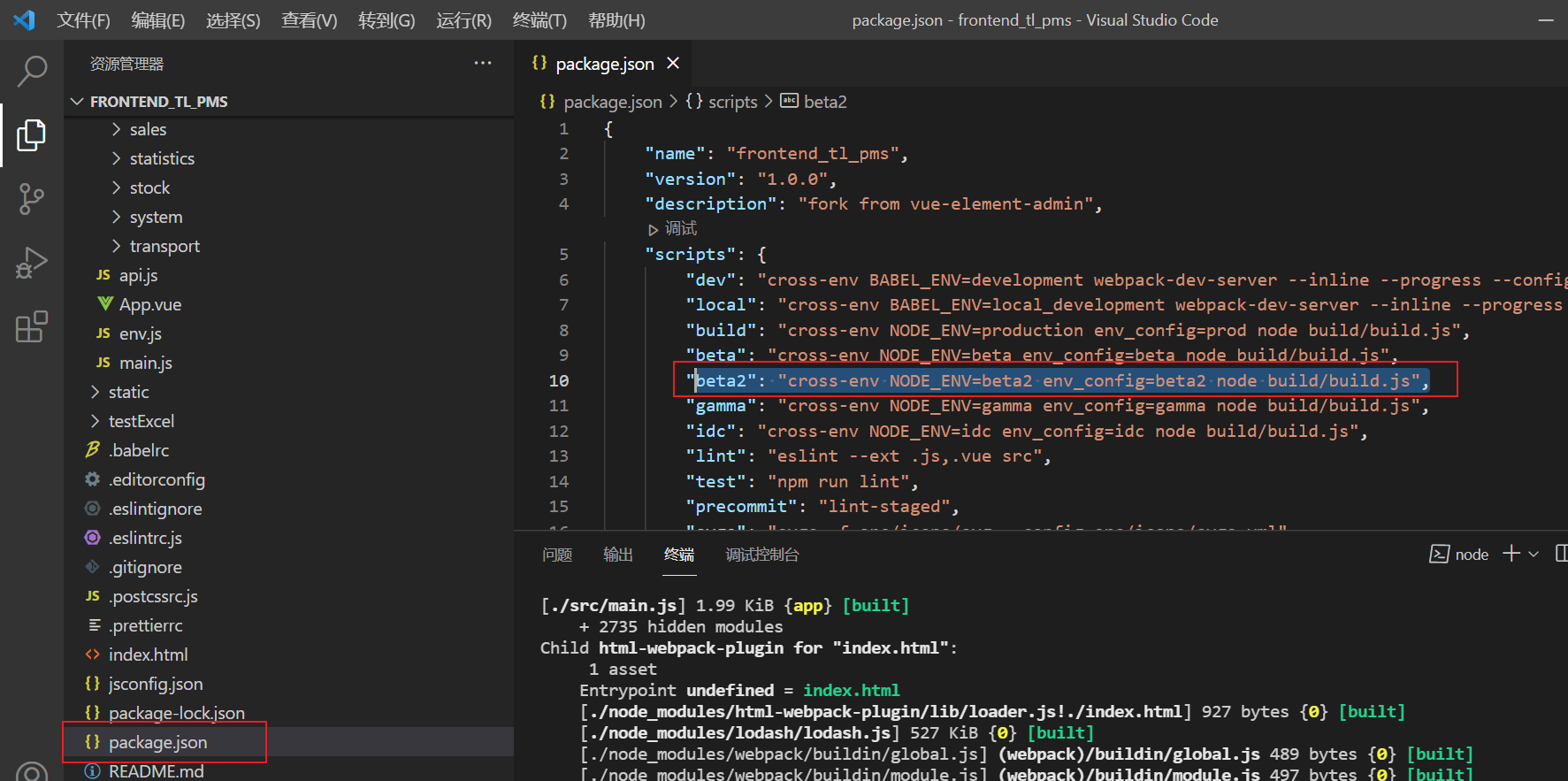
在
config目录下创建beta2.env.js文件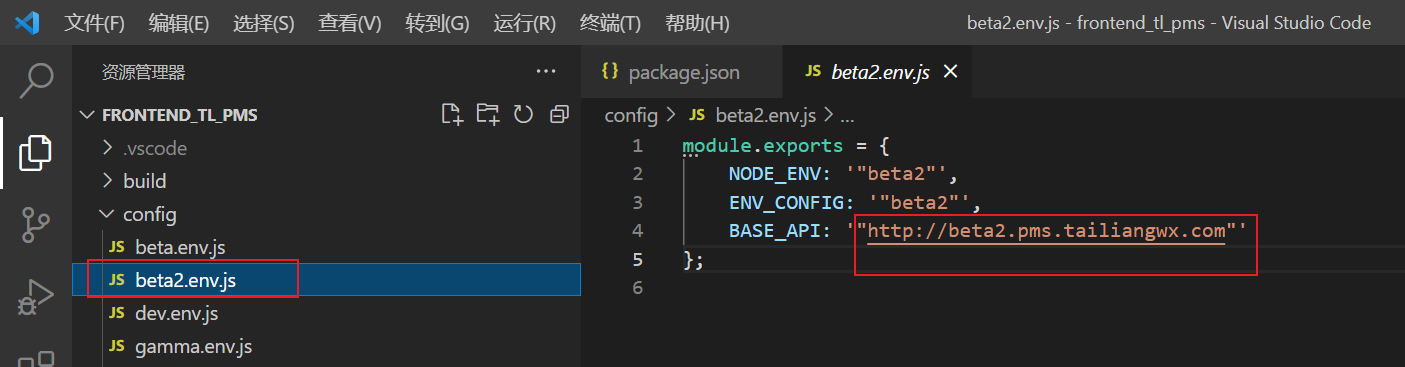
然后执行
npm run beta2即可打包,打包之后将文件上传到/data/webstatic/pms2目录即可最后如果修改
nginx配置文件,需要执行重启即可./nginx -s reload
5、windows怎么关闭指定端口服务
查看所有端口
查询所有端口服务
netstat -ano关闭对应的pid
taskkill /f /pid 15952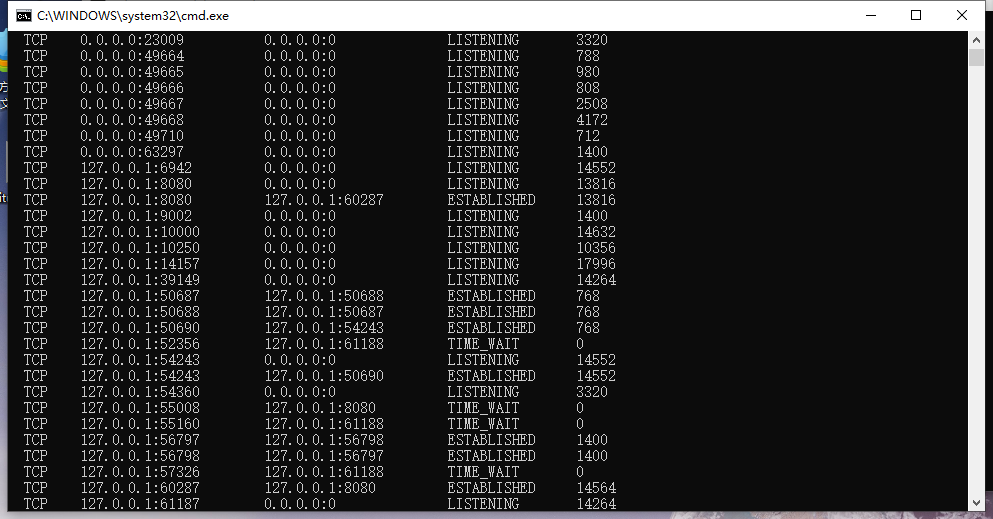
查看指定端口
netstat -aon|findstr "9002"
taskkill /f /pid 20952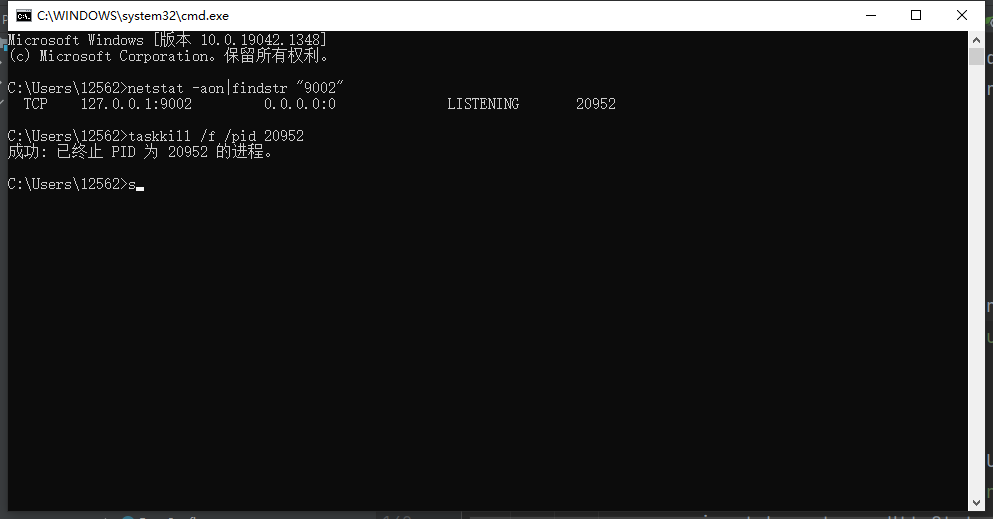
6、查询文件位置
查询所有包含nginx的文件名字位置
find / -name nginx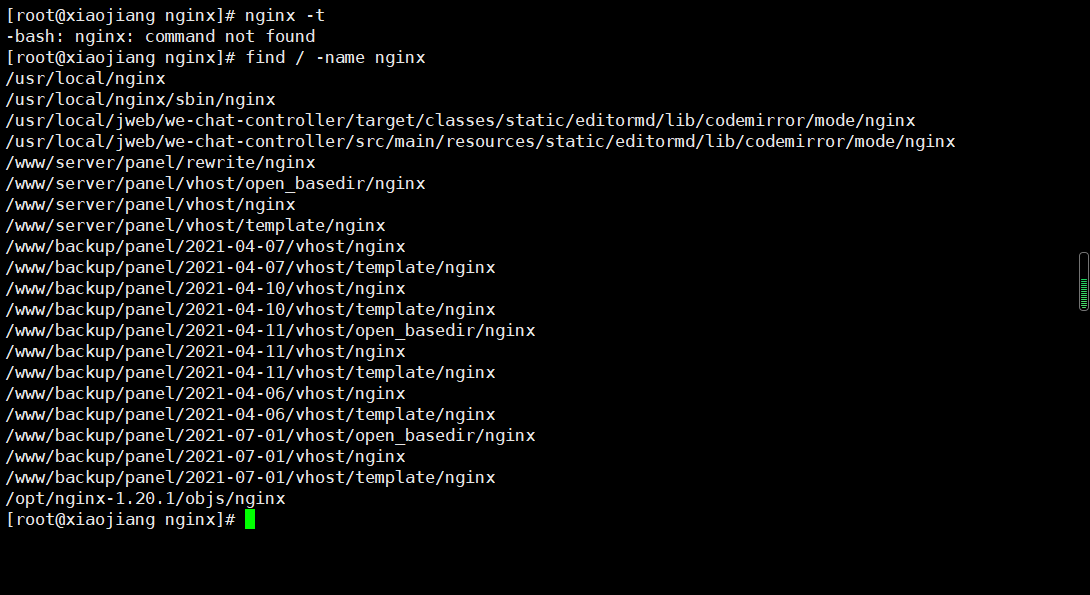
7、nginx配置环境变量
1)-bash:nginx:未找到命令(command not found)说明nginx还没有配置到环境变量里
vi /etc/profile2)在文件最后加入一行代码(根据自己的安装目录填写)
export PATH=$PATH:/usr/local/nginx/sbin3)刷新配置文件/etc/profile
source /etc/profile8、查看端口使用情况
netstat -anp|grep 80009、配置服务器
安装Nginx
1、下载安装包:http://nginx.org/en/download.html
2、将安装包上传到服务器的/etc/nginx目录下,然后执行
# 解压文件
tar -zxvf nginx-1.20.1.tar.gz
# 进入nginx目录
cd nginx-1.20.1
# 开始安装,依次执行下方指令
./configure --prefix=/etc/nginx --conf-path=/etc/nginx/nginx.conf
make
make install安装Redis
1、下载安装包:https://redis.io/
2、上传到/etc/redis目录下
3、进行解压
tar -zxvf redis-6.2.6.tar.gz4、开始安装
make PREFIX=/etc/redis install5、redis配置文件
cd /etc/redis/bin
# 复制配置文件
cp -r /etc/redis/redis-6.2.6/redis.conf /etc/redis/bin
# 修改配置文件
vim redis.conf
# 修改端口
port 1268
# 开启后台运行
daemonize yes
# 配置密码
requirepass 6DY1k2wWFE6hDG4b6、启动redis
redis-server redis.conf- daemonize介绍
- redis.conf配置文件中daemonize守护线程,默认是NO。
- daemonize是用来指定redis是否要用守护线程的方式启动。
- daemonize 设置yes或者no区别
daemonize:yes:redis采用的是单进程多线程的模式。当redis.conf中选项daemonize设置成yes时,代表开启守护进程模式。在该模式下,redis会在后台运行,并将进程pid号写入至redis.conf选项pidfile设置的文件中,此时redis将一直运行,除非手动kill该进程。daemonize:no: 当daemonize选项设置成no时,当前界面将进入redis的命令行界面,exit强制退出或者关闭连接工具(putty,xshell等)都会导致redis进程退出。
安装JDK
- 安装命令:
yum install java-1.8.0-openjdk.x86_64 - 检测命令:
java -version
安装Maven
- 安装命令:
yum install maven - 检测命令:
mvn -v
安装Node
- 安装命令:
yum install nodejs - 检测命令:
npm -v
安装pm2
- 前置条件:需要安装 Node
- 安装命令:
npm install pm2 -g
安装Git
- 安装命令:
yum install git - 检测命令:
git --version
创建用户和证书
1、创建用户
adduser appadmin
su appadmin2、生成证书
ssh-keygen -t rsa -f ~/.ssh/TL-BETA-02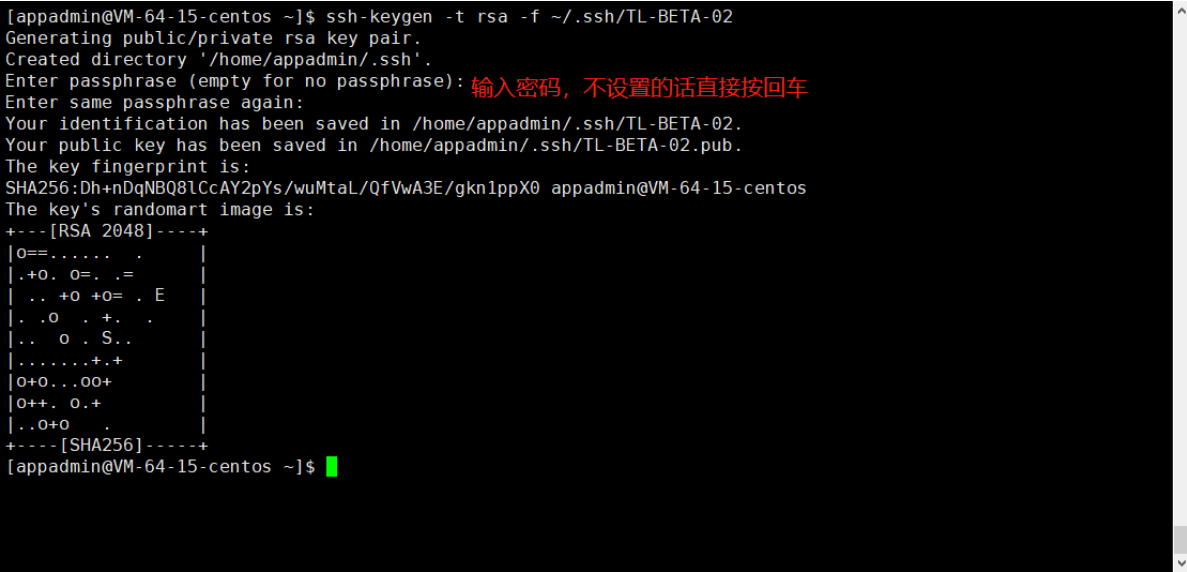
3、注册公钥
# 在服务器上注册公钥
cd ~/appadmin/.ssh
cat TL-BETA-02.pub >> authorized_keys
# ssh 对目录的权限有要求,要设置下新生成的config文件权限才行
chmod 600 authorized_keys4、下载密钥
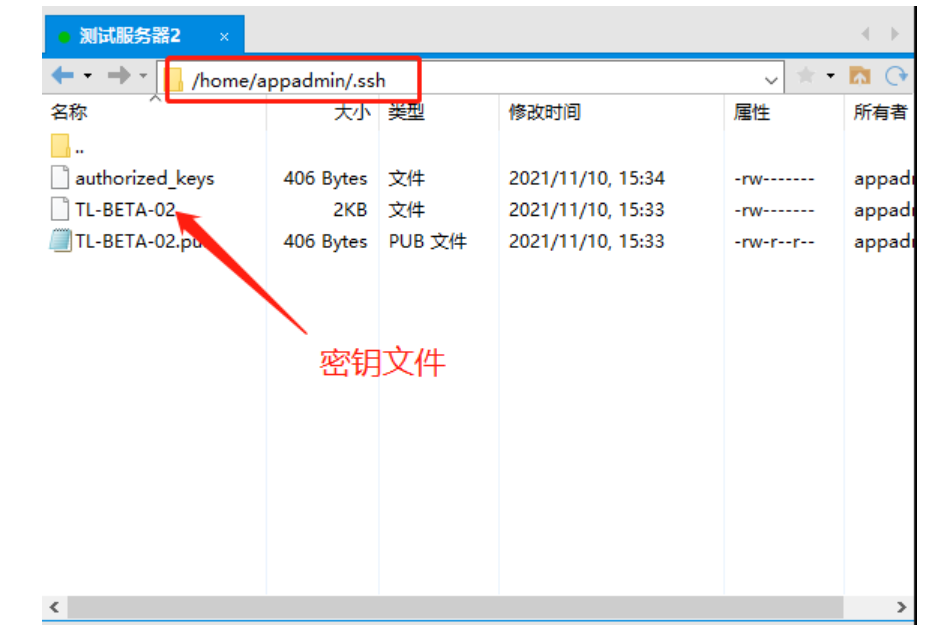
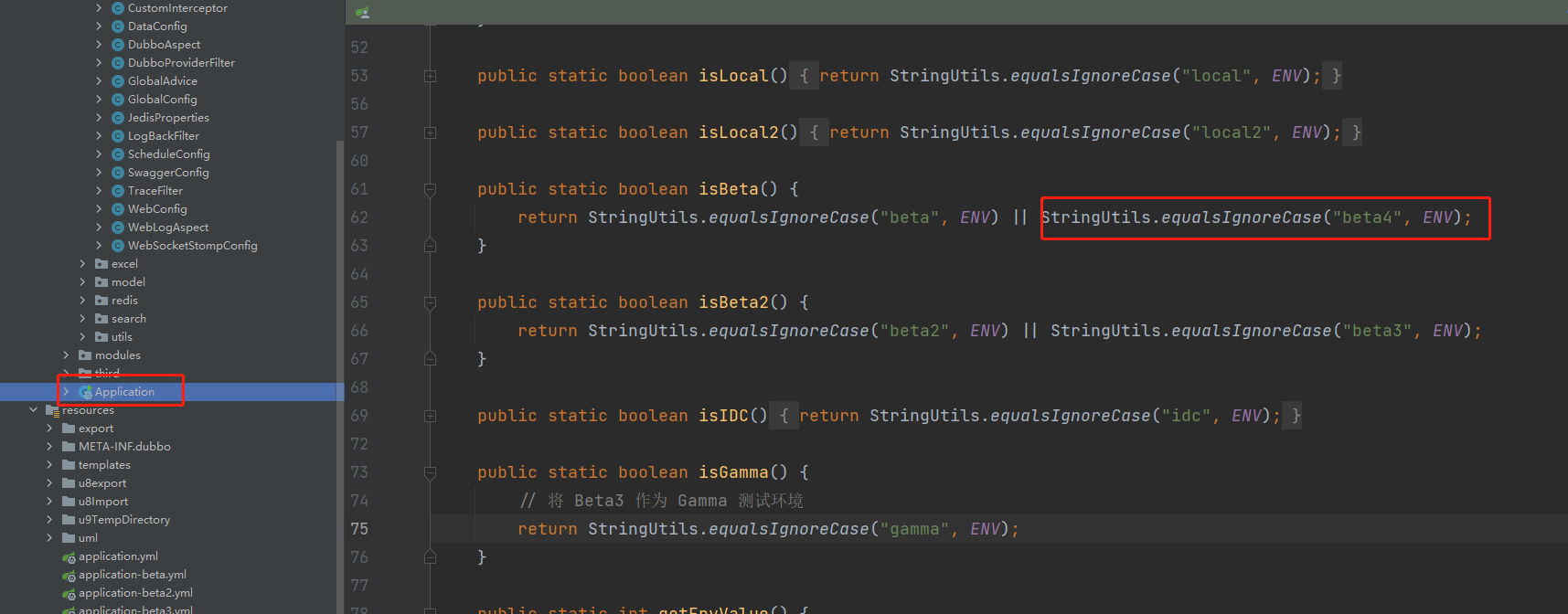
在应用中增加Beta4环境
4、Git相关
1、git修改用户名
查看当前用户信息
git config user.name全局修改
git config --global user.name 用户名
git config --global user.email 邮箱名修改当前的 project
git config user.name 用户名
git config user.email 邮箱名2、git rebase的使用
Git - 变基
官方文档:https://git-scm.com/book/zh/v2/Git-%E5%88%86%E6%94%AF-%E5%8F%98%E5%9F%BA
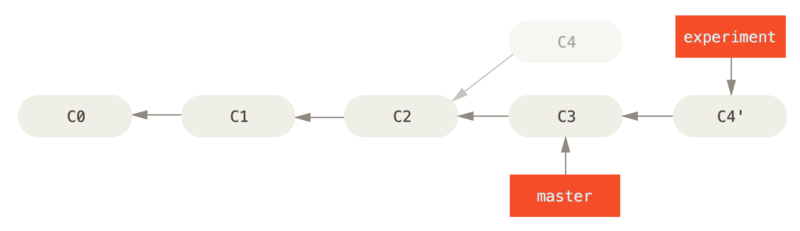
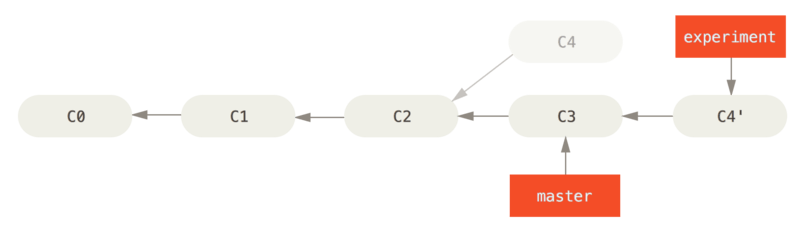
通过合并操作来整合分叉的历史,你可以提取在 C4 中引入的补丁和修改,然后在 C3 的基础上应用一次。 在 Git 中,这种操作就叫做 变基(rebase)。 你可以使用 rebase 命令将提交到某一分支上的所有修改都移至另一分支上,就好像“重新播放”一样。
在这个例子中,你可以检出 experiment 分支,然后将它变基到 master 分支上:
$ git checkout experiment
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: added staged command它的原理是首先找到这两个分支(即当前分支 experiment、变基操作的目标基底分支 master) 的最近共同祖先 C2,然后对比当前分支相对于该祖先的历次提交,提取相应的修改并存为临时文件, 然后将当前分支指向目标基底 C3, 最后以此将之前另存为临时文件的修改依序应用。
在 Git 中整合来自不同分支的修改主要有两种方法:合并merge 以及 变基rebase。
变基最新的远端代码
git rebase remotes/origin/master
# 或者直接使用
git pull --rebase origin masterGit - 重写历史
官方文档:https://git-scm.com/book/zh/v2/Git-%E5%B7%A5%E5%85%B7-%E9%87%8D%E5%86%99%E5%8E%86%E5%8F%B2
在使用 Git 时,可能想要修订提交历史。也可以重写已经发生的提交。 这可能涉及改变提交的顺序,改变提交中的信息或修改文件,将提交压缩或是拆分, 或完全地移除提交。
但最好是在将工作成果与他人共享之前进行重写操作,否则修改之后只能进行强推。

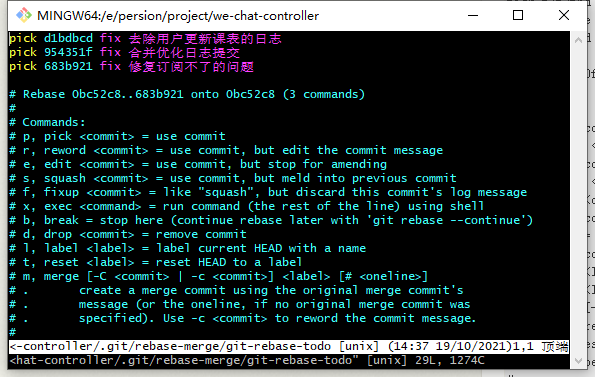
git rebase -i 常用指令
# 修改最近三次提交信息
$ git rebase -i HEAD~3
# 修改 a5f4a0d 提交之后的内容
$ git rebase -i a5f4a0d
# 查看最近三次提交的信息和短id
$ git log --pretty=format:"%h %s" HEAD~3..HEAD输入以上命令指令之后会在文本编辑器上给你一个提交的列表,不过文本编辑器的内容是反序显示的,即最近一次提交在最下方。

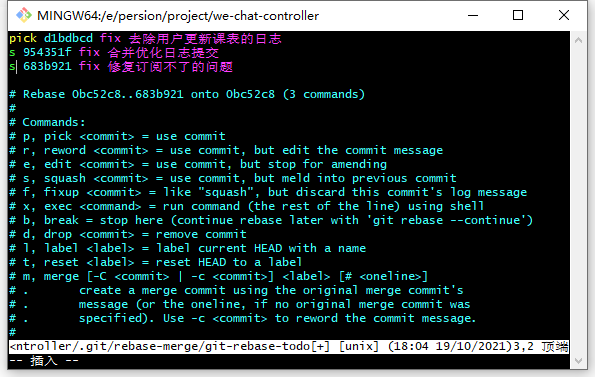
编辑器指令
- pick:保留该commit(缩写:p)
- reword:保留该commit,但我需要修改该commit的注释(缩写:r)
- edit:保留该commit, 但我要停下来修改该提交(不仅仅修改注释)(缩写:e)
- squash:将该commit和前一个commit合并(缩写:s)
- fixup:将该commit和前一个commit合并,但我不要保留该提交的注释信息(缩写:f)
- exec:执行shell命令(缩写:x)
- drop:我要丢弃该commit(缩写:d)
编辑完成之后按Esc 并输入:Wq即可保存退出并执行,如果是使用edit指令,可以将游标移动到指定的位置,进行修改或者添加提交。
3、git修改注释内容
修改最后一次提交的内容
git commit --amend或者通过 rebase 对之前的进行处理
选中对应的提交,使用e可以将游标指向该次提交
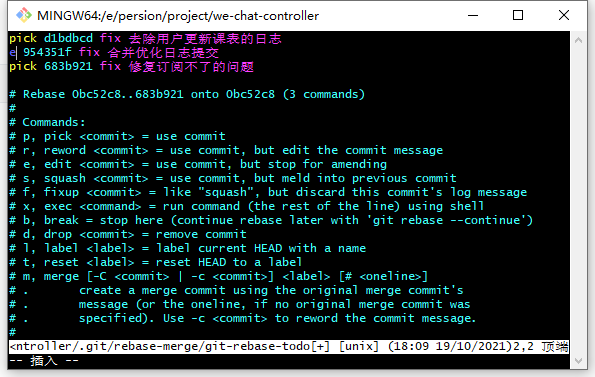
执行git commit --amend
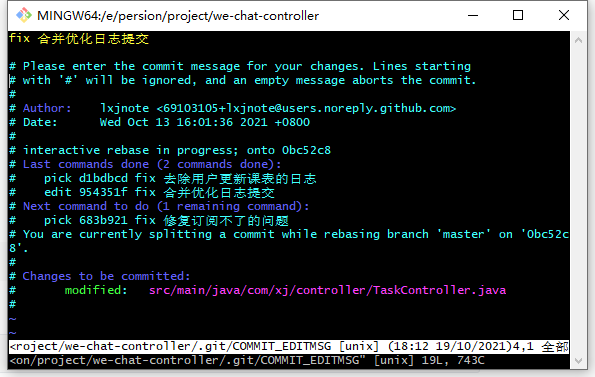
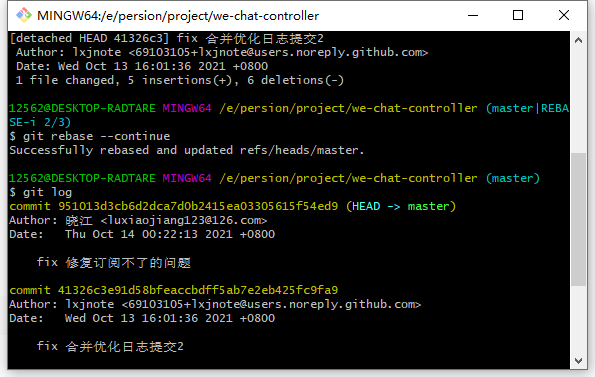
最后将游标指向回去即可git rebase --continue
4、git push
git push 命用于从将本地的分支版本上传到远程并合并
命令格式如下:
git push <远程主机名> <本地分支名>:<远程分支名>如果本地分支名与远程分支名相同,则可以省略冒号:
git push <远程主机名> <本地分支名>5、git pull
git pull 命令用于从远程获取代码并合并本地的版本。
命令格式如下:
git pull <远程主机名> <远程分支名>:<本地分支名>使用下面的关系区别这两个操作:
git pull 相当于 git fetch + git merge
git pull --rebase 相当于 git fetch + git rebase
参考文章:
6、git fetch
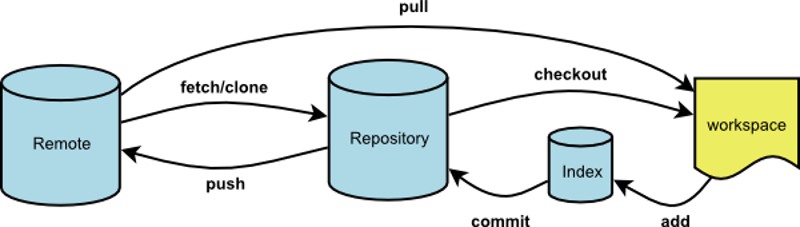
概念
可以简单的概括为:
git fetch是将远程主机的最新内容拉到本地,用户在检查了以后决定是否合并到工作本机分支中。
而git pull 则是将远程主机的最新内容拉下来后直接合并,即:git pull = git fetch + git merge,这样可能会产生冲突,需要手动解决。
常用命令
# 这个命令将某个远程主机的更新全部取回本地
$ git fetch <远程主机名>
# 如果只想取回特定分支的更新,可以指定分支名
$ git fetch <远程主机名> <分支名>7、git revert
git revert 撤销 某次操作,此次操作之前和之后的commit和history都会保留,并且把这次撤销作为一次最新的提交。
$ git revert HEAD^ # 撤销前一次 commit
$ git revert <SHA-1> # (比如:fa042ce57ebbe5bb9c8db709f719cec2c58ee7ff)撤销指定的版本,撤销也会作为一次提交进行保存。git revert是提交一个新的版本,将需要revert的版本的内容再反向修改回去。
8、git reset
git reset 命令用于回退版本,可以指定退回某一次提交的版本。
$ git reset --hard HEAD^ # 回退所有内容到上一个版本
$ git reset --hard 052e # 回退到指定版本HEAD 说明:
- HEAD 表示当前版本
- HEAD^ 上一个版本
- HEAD^^ 上上一个版本
- HEAD^^^ 上上上一个版本
- 以此类推…
可以使用 ~数字表示
- HEAD~0 表示当前版本
- HEAD~1 上一个版本
- HEAD^2 上上一个版本
- HEAD^3 上上上一个版本
- 以此类推…
9、git 分支管理
创建分支
# 创建分支
$ git branch <分支名>
# 切换分支
$ git checkout <分支名>
# 创建并切换到新分支
$ git checkout -b <分支名>查看所有分支
# 查看本地分支
$ git branch
# 查看远程分支
$ git branch -r
# 查看所有分支
$ git branch -a删除分支
# 删除本地分支
$ git branch -d <分支名>、
# 强制删除
$ git branch -D <分支名>
# 删除远端分支
$ git push origin --delete <分支名>分支合并
# 将其他分支合并到当前分支
$ git merge <分支名>10、merge 和 rebase 的区别
git merge
git 会自动根据两个分支的共同祖先和两个分支的最新提交进行一个三方合并,然后将合并中修改的内容生成一个新的 commit。
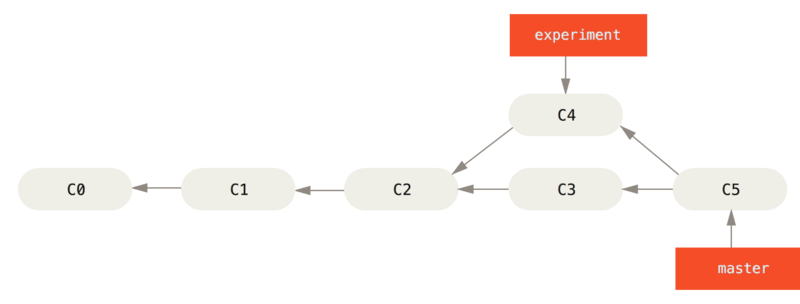
git rebase
首先找到这两个分支(即当前分支 experiment、变基操作的目标基底分支 master) 的最近共同祖先 C2,然后对比当前分支相对于该祖先的历次提交,提取相应的修改并存为临时文件, 然后将当前分支指向目标基底 C3, 最后以此将之前另存为临时文件的修改依序应用。
因此也不会产生新的提交。
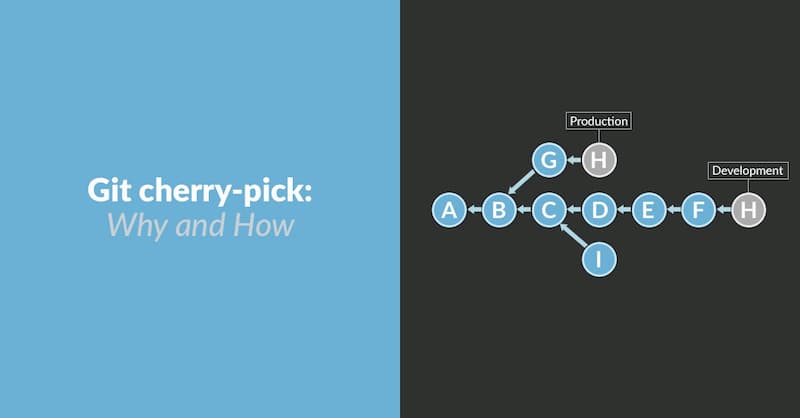
11、git cherry-pick
用于摘取其他分支上的部分提交。
# 将指定的提交(commit)应用于当前分支
$ git cherry-pick <commitHash>
# 摘取多个提交(之间用空格分开)
$ git cherry-pick <HashA> <HashB>
# 一系列的连续提交
$ git cherry-pick A..B # 不包含A
$ git cherry-pick A^..B # 包含A配置项
git cherry-pick命令的常用配置项如下。
(1)-e,--edit
打开外部编辑器,编辑提交信息。
(2)-n,--no-commit
只更新工作区和暂存区,不产生新的提交。
(3)-x
在提交信息的末尾追加一行(cherry picked from commit ...),方便以后查到这个提交是如何产生的。
(4)-s,--signoff
在提交信息的末尾追加一行操作者的签名,表示是谁进行了这个操作。
(5)-m parent-number,--mainline parent-number
如果原始提交是一个合并节点,来自于两个分支的合并,那么 Cherry pick 默认将失败,因为它不知道应该采用哪个分支的代码变动。
12、git stash
存储
git stash save "描述语言"弹出存储
git stash pop应用存储
git stash apply stash@{ 1} 查看存储列表
git stash list13、git reflog
查看git修改日志
git reflog
回退到指定修改节点
git reset --hard 'HEAD@{ 2} '14、origin
远程主机名
origin 并不是指得是远程的仓库,而是指得是远程仓库在本地的一个指针(这个指针有可能过时的)。当我们使用使用merge 的时候,我们进行合并的时候只是上一次fetch 从远程拿到的版本。不是远程仓库的最新版本。
比如命令:
git merge origin master # 将origin merge 到 master 上
git merge origin/master # 将origin上的master分支 merge 到当前 branch 上 指的就是将本地的远端分支与本地的master 分支进行合并。
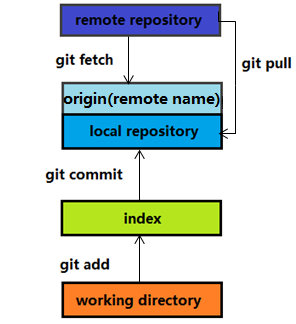
1、git fetch只会将本地库所关联的远程库(origin)的commit id更新至最新
2、git pull会将本地库更新至远程库的最新状态
所以 git fetch 和 git merge 共同效果并不完全等同于 git pull
# 将从origin remote, master分支中提取更改,并将它们合并到本地签出分支。
git pull origin master
# 将从本地存储的分支origin/master抽取更改,并将其合并到本地签出分支。 origin/master分支本质上是最初从origin提取的“缓存副本”。
git pull origin/master15、强制拉取
git fetch --all
git reset --hard origin/master
git pull 5、数据库操作
1、连接查询join
类别
内连接:(inner) join (交集)
select * from table1 join table2 on table1.id=table2.id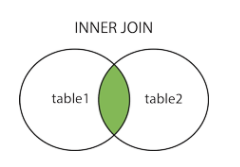
左(外)连接:left (outer) join (查询左边的所有行,右边查询不到默认为null)
select * from table1 left join table2 on table1.id=table2.id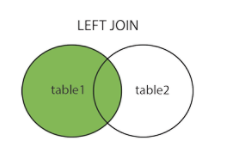
右(外)连接:right (outer) join (查询右边的所有行,左边查询不到默认为null)
select * from table1 right join table2 on table1.id=table2.id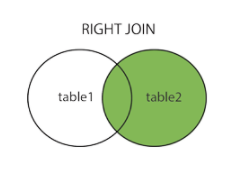
全连接:full join (为空的就显示null,相当于求并集)
交叉连接:from [多个表格] (笛卡尔积,获取交集)
2、分组group by
将查询结果按照某一字段进行分组,所以被选中的字段不会重复。用于结合聚合函数,根据一个或多个列对结果集进行分组。
select name, sum(grade) from student group by name3、组合查询union
union 语法
用于连接多个select语句,并且每个语句必须包含相同的列、表达式或聚集函数。
SELECT name, column_name(s) FROM table_name1
UNION
SELECT name, column_name(s) FROM table_name2union all 语法
因为union默认会去除查询结果中重复的数据集,而使用union all 可以查询出两个表格的所有数据
SELECT name, column_name(s) FROM table_name1
UNION ALL
SELECT name, column_name(s) FROM table_name24、联表删除
delete
report, item
FROM
`t_purchase_market_report` report
LEFT JOIN t_purchase_market_report_item item ON report.reportId = item.reportId
WHERE
report.createTime BETWEEN '2021-10-14 19:52:09'
AND '2021-10-14 19:54:09' 5、查询插入
INSERT INTO t_biz_role_auth (
`roleId`,
`authId`,
`authType`,
`accessType`,
`name`,
`createTime`,
`updateTime` )
SELECT
`roleId`,
1123,
`authType`,
`accessType`,
'请购单创建',
`createTime`,
`updateTime`
FROM
t_biz_role_auth
WHERE
authId = 1122;6、行锁for update
for update
for update是一种行级锁,又叫排它锁,一旦用户对某个行施加了行级加锁,则该用户可以查询也可以更新被加锁的数据行,其他用户只能查询但不能更新被加锁的数据行。行锁永远是独占方式锁。
只有当出现如下之一的条件,才会释放共享更新锁:
1、执行提交(COMMIT)语句
2、退出数据库(LOG OFF)
3、程序停止运行
使用方法
例1: (明确指定主键,并且数据真实存在,row lock)
SELECT * FROM user WHERE id=3 FOR UPDATE;
SELECT * FROM user WHERE id=3 and name='Tom' FOR UPDATE;例2: (明确指定主键,但数据不存在,无lock)
SELECT * FROM user WHERE id=0 FOR UPDATE;例3: (主键不明确,table lock)
SELECT * FROM user WHERE id<>3 FOR UPDATE;
SELECT * FROM user WHERE id LIKE '%3%' FOR UPDATE;例4: (无主键,table lock)
SELECT * FROM user WHERE name='Tom' FOR UPDATE;7、事务
四大特性
- 原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
- 隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- 持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
事务处理方法
1、开启和提交事务
BEGIN或START TRANSACTION开始一个事务ROLLBACK或ROLLBACK WORK事务回滚COMMIT或COMMIT WORK事务确认
2、直接用 SET 来改变 MySQL 的自动提交模式
SET AUTOCOMMIT=0禁止自动提交SET AUTOCOMMIT=1开启自动提交
8、索引INDEX
概念
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。
普通索引
创建索引的方法
# 方法一
CREATE INDEX indexName ON table_name (column_name)
# 方法二
ALTER table tableName ADD INDEX indexName(columnName)
# 方法三
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
); 删除索引
DROP INDEX [indexName] ON mytable; 唯一索引
索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式:
# 方法一
CREATE UNIQUE INDEX indexName ON mytable(username(length))
# 方法二
ALTER table mytable ADD UNIQUE [indexName] (username(length))
# 方法三
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
UNIQUE [indexName] (username(length))
);删除索引
ALTER TABLE testalter_tbl DROP INDEX c;四种添加数据表索引的方式
- **ALTER TABLE tbl_name ADD PRIMARY KEY (column_list):**该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
- ALTER TABLE tbl_name ADD UNIQUE index_name (column_list): 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
- ALTER TABLE tbl_name ADD INDEX index_name (column_list): 添加普通索引,索引值可出现多次。
- **ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):**该语句指定了索引为 FULLTEXT ,用于全文索引。
显示索引信息
SHOW INDEX FROM table_name强制使用主键索引
force index(PRI)
9、on duplicate key update
如果主键不存在就插入,存在则执行 update 后面的更新语句
INSERT INTO t_biz_user_role(uin, roleId, roleName) values (#{ uin} , #{ roleId} , #{ roleName} ) on duplicate key update roleName=#{ roleName} 6、Maven基本指令
需要先执行下方代码
mvn -N io.takari:maven:0.7.7:wrapper
mvn clean install 安装mvn,生成.mvn文件
mvn -version 查看maven的版本及配置信息
mvn compile 编译项目代码
mvn package 打包项目
mvn package -Dmaven.test.skip=true 打包项目时跳过单元测试
mvn test 运行单元测试
mvn clean 清除编译产生的target文件夹内容,可以配合相应命令一起使用,如mvn clean package, mvn clean test
mvn deploy 打包后将其安装到pom文件中配置的远程仓库
mvn eclipse:eclipse 将maven生成eclipse项目结构
mvn eclipse:clean 清除maven项目中eclipse的项目结构
mvn site 生成站点目录
mvn dependency:list 显示所有已经解析的所有依赖
mvn dependency:tree 以树的结构展示项目中的依赖
mvn dependency:analyze 对项目中的依赖进行分析,依赖未使用,使用单未引入
mvn tomcat:run 启动tomcat
7、pm2常用指令
pm2官方文档:https://pm2.keymetrics.io/docs/usage/quick-start/
pm2是一个进程管理工具,可以用它来管理你的node进程,并查看node进程的状态,当然也支持性能监控,进程守护,负载均衡等功能
pm2需要全局安装 npm install -g pm2
为pm2创建软连接 ln -s /usr/local/node/bin/pm2 /usr/local/bin/
启动进程/应用 pm2 start bin/www 或 pm2 start app.js
重命名进程/应用 pm2 start app.js --name wb123
添加进程/应用 watch pm2 start bin/www --watch
结束进程/应用 pm2 stop www
结束所有进程/应用 pm2 stop all
删除进程/应用 pm2 delete www
删除所有进程/应用 pm2 delete all
列出所有进程/应用 pm2 list
查看某个进程/应用具体情况 pm2 describe www
查看进程/应用的资源消耗情况 pm2 monit
查看pm2的日志 pm2 logs
若要查看某个进程/应用的日志,使用 pm2 logs www
重新启动进程/应用 pm2 restart www
重新启动所有进程/应用 pm2 restart all
8、Linux相关
1、创建文件夹
mkdir
2、删除文件
rm -rf <文件名>
3、创建SSH登录证书
生成证书
输入指令
ssh-keygen -t rsa -f ~/.ssh/TL-BETA-02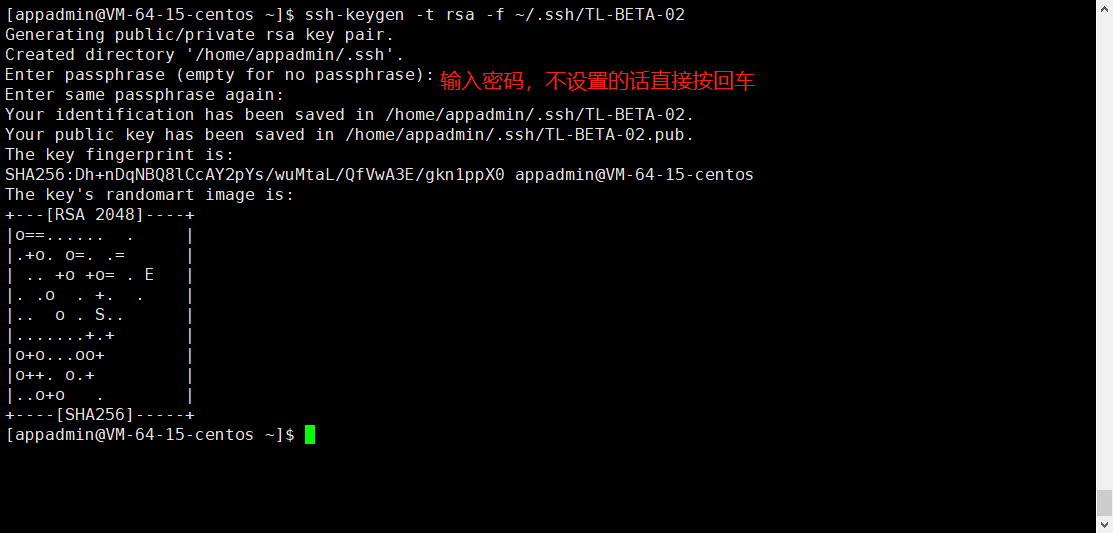
注册公钥
# 在服务器上注册公钥
cat TL-BETA-02.pub >> authorized_keys
# ssh 对目录的权限有要求,要设置下新生成的config文件权限才行
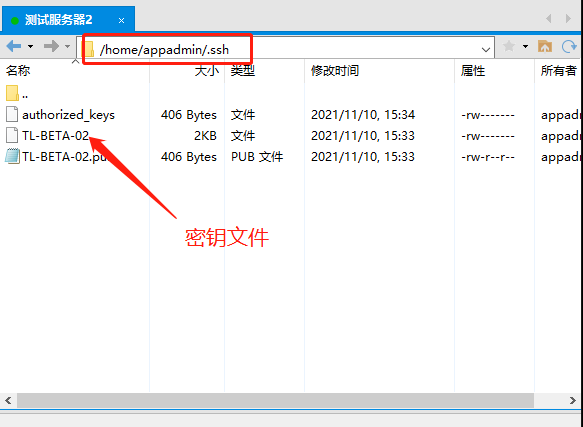
chmod 600 authorized_keys下载密钥
使用密钥连接服务器
输入用户名,选择登录方式,点击设置
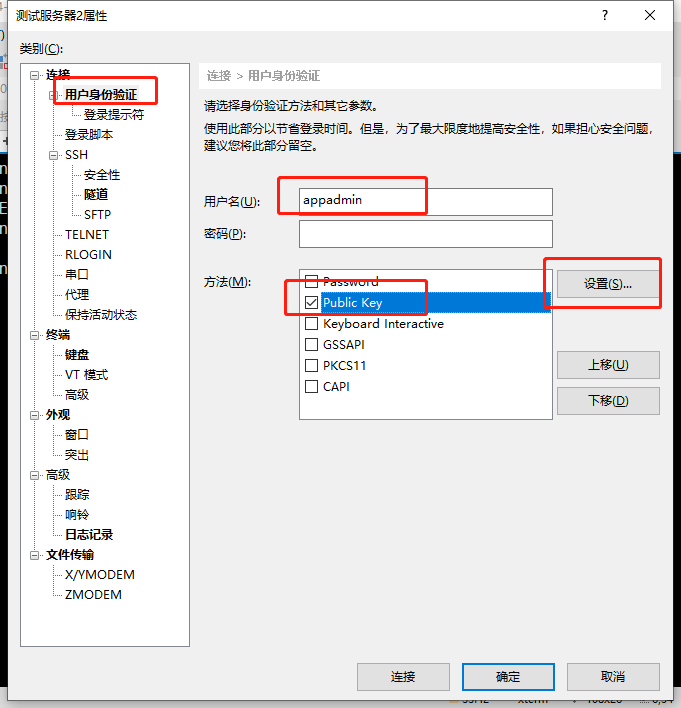
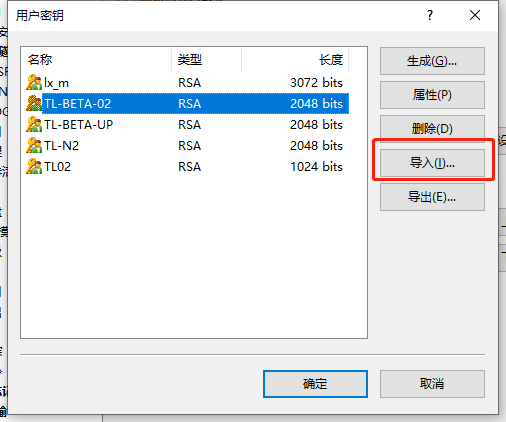
导入对应的密钥然后点击确定即可
4、less相关
外部命令
- -b <缓冲区大小> 设置缓冲区的大小
- -e 当文件显示结束后,自动离开
- -f 强迫打开特殊文件,例如外围设备代号、目录和二进制文件
- -g 只标志最后搜索的关键词
- -i 忽略搜索时的大小写
- -m 显示类似more命令的百分比
- -N 显示每行的行号
- -o <文件名> 将less 输出的内容在指定文件中保存起来
- -Q 不使用警告音
- -s 显示连续空行为一行
- -S 行过长时间将超出部分舍弃
- -x <数字> 将”tab”键显示为规定的数字空格
搜索命令
- /字符串:向下搜索”字符串”的功能
- ?字符串:向上搜索”字符串”的功能
- n:重复前一个搜索(与 / 或 ? 有关)
- N:反向重复前一个搜索(与 / 或 ? 有关)
翻页命令
- b 向上翻一页
- f 向下翻一页
- j 下一行
- k 上一行
- d 向后翻半页
- u 向前滚动半页
- y 向前滚动一行
- 空格键 滚动一页
- 回车键 滚动一行
- [pagedown]: 向下翻动一页
- [pageup]: 向上翻动一页
其他导航
- G - 移动到最后一行
- g - 移动到第一行
- q / ZZ - 退出 less 命令
标记导航
- m + a: 使用 a 标记文本的当前位置,使用单个字母标记
- ‘a:导航到标记 a 处
其他命令
v - 使用配置的编辑器编辑当前文件
h - 显示 less 的帮助文档
&pattern - 仅显示匹配模式的行,而不是整个文件,进去就出不来啊啊啊啊
大写 F,就会有类似 tail -f 的效果,读取写入文件的最新内容, 按 ctrl+C 停止。
v 进入编辑模型, shift+ZZ 保存退出到 less 查看模式。
:e 查看下一个文件, 用 :n 和 :p 来回切换。
5、查看服务器是多少位的
getconf LONG_BIT6、服务器配置蒲公英
1、安装蒲公英:https://service.oray.com/question/5063.html
2、登录蒲公英后台,并创建网络,添加软件成员
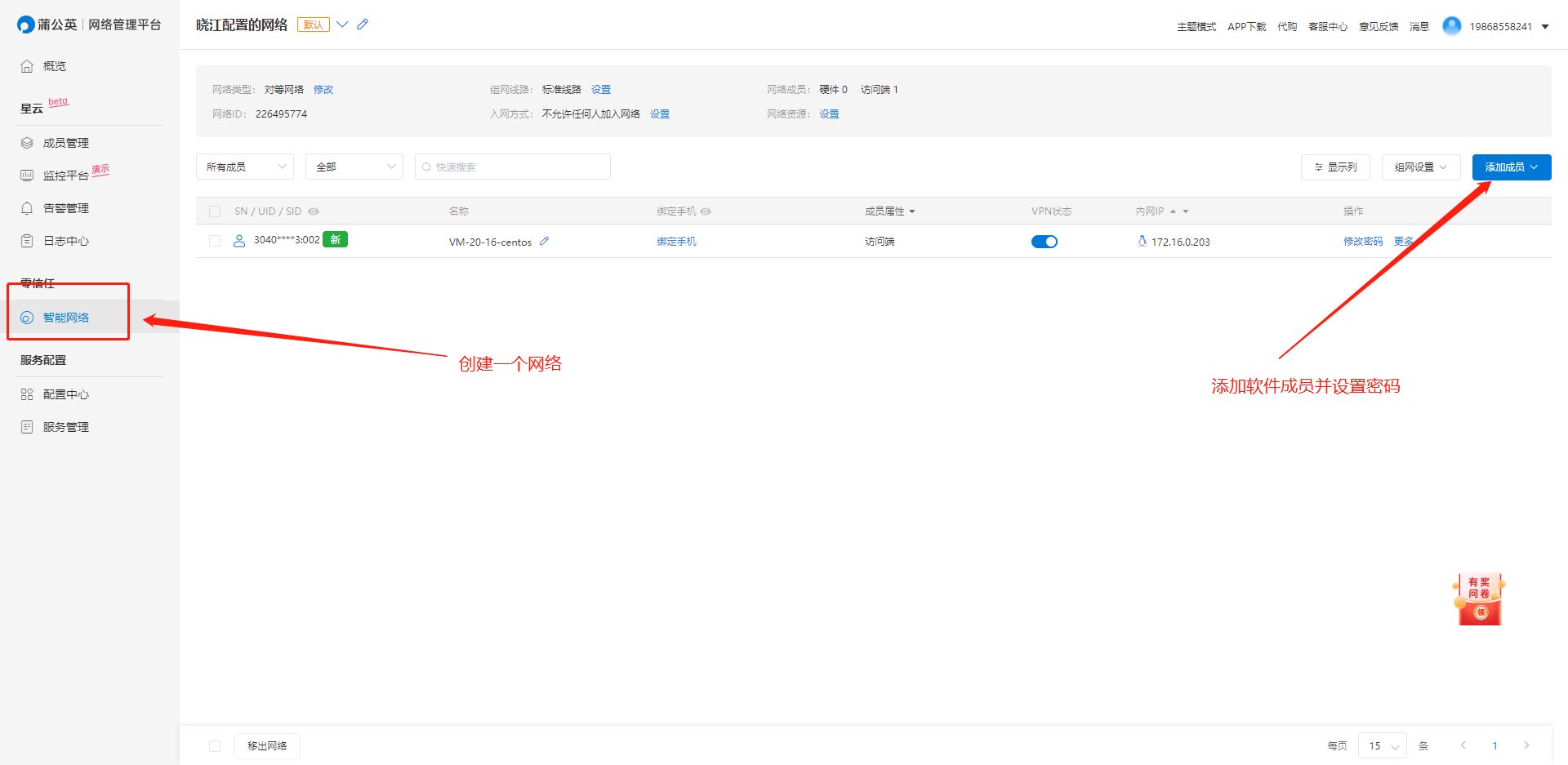
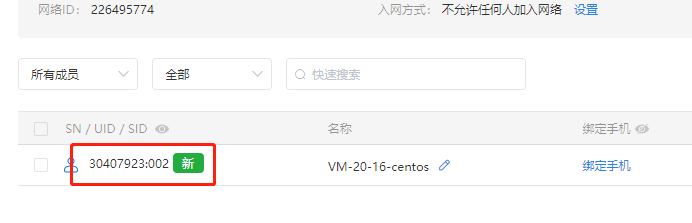
3、使用成员账号进行登录
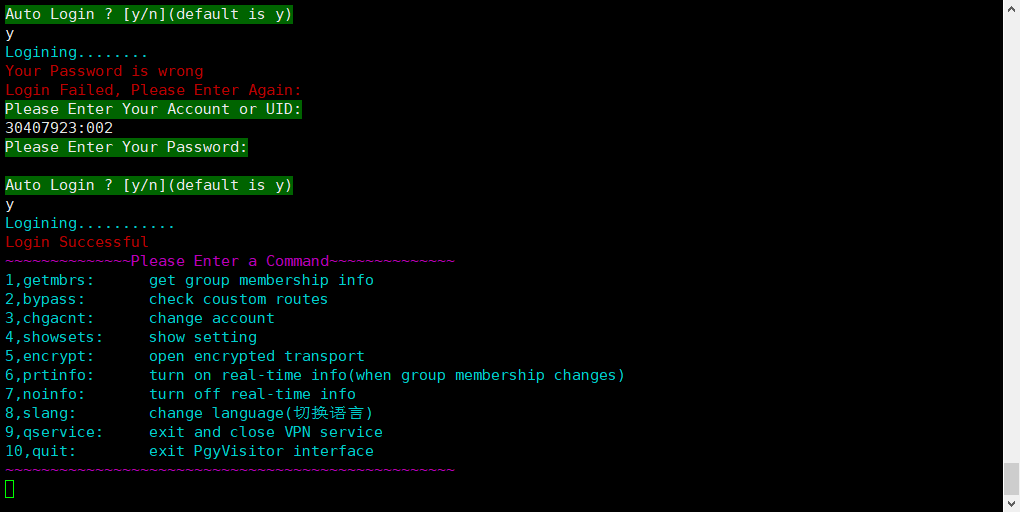
4、在服务器上输入 pgyvpn即可登录
7、修改Linux样式
1、修改 ~/.bashrc 文件,增加
PS1="(\u) \[\e[36;40m\][\w]\[\e[0m\]\\[\e[36;40m\]\\$\[\e[0m\] " 2、重新加载配置
source ~/.bashrc8、安装Nginx
sudo rpm -Uvh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
sudo yum install -y nginx9、安装Redis
yum install redis10、echo命令
1、echo命令我们经常使用的选项有两个,一个是-n,表示输出之后不换行。另外一个是-e,表示对于转义字符按对应的方式处理,假设不加-e那么对于转义字符会按普通字符处理。
2、echo输出时的转义字符\b 表示删除前面的空格\n 表示换行\t 表示水平制表符\v 表示垂直制表符\c \c后面的字符将不会输出,同一时候,输出完毕后也不会换行\r 输出回车符(可是你会发现\r前面的字符没有了)\a 表示输出一个警告声音
3、echo中的重定向,能够把内容输出到文件里而不是标准输出
echo "hello world!" > test1.tmp11、LogStash的安装
1、下载rpm安装包
2、上传到服务器上并解压安装
rpm -ivh logstash-7.16.3-x86_64.rpm 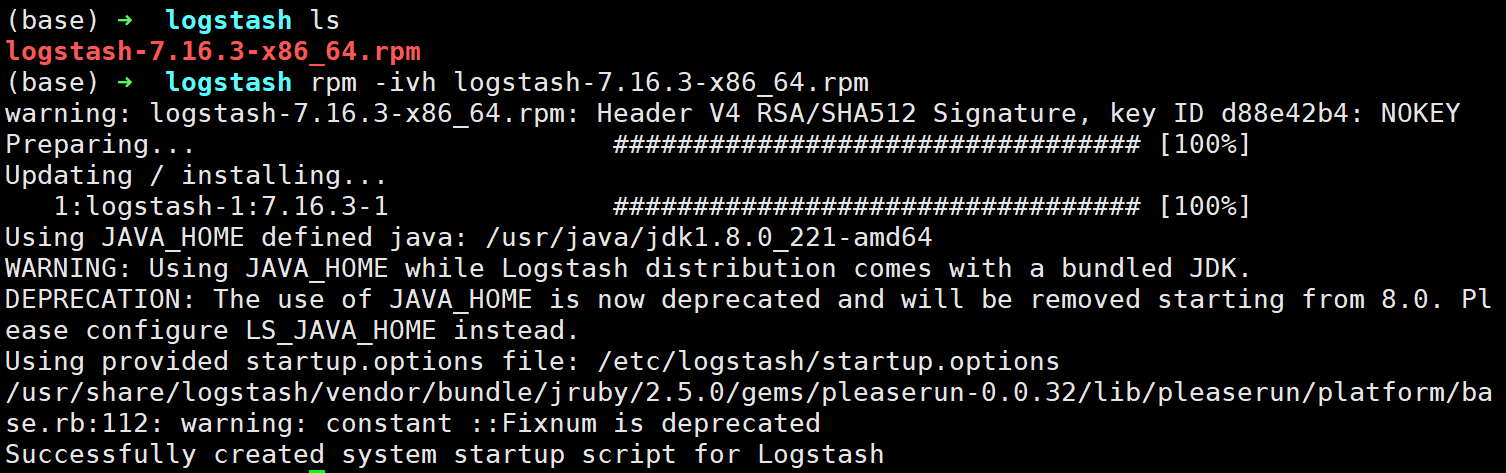
3、查看文件所在路径
whereis logstash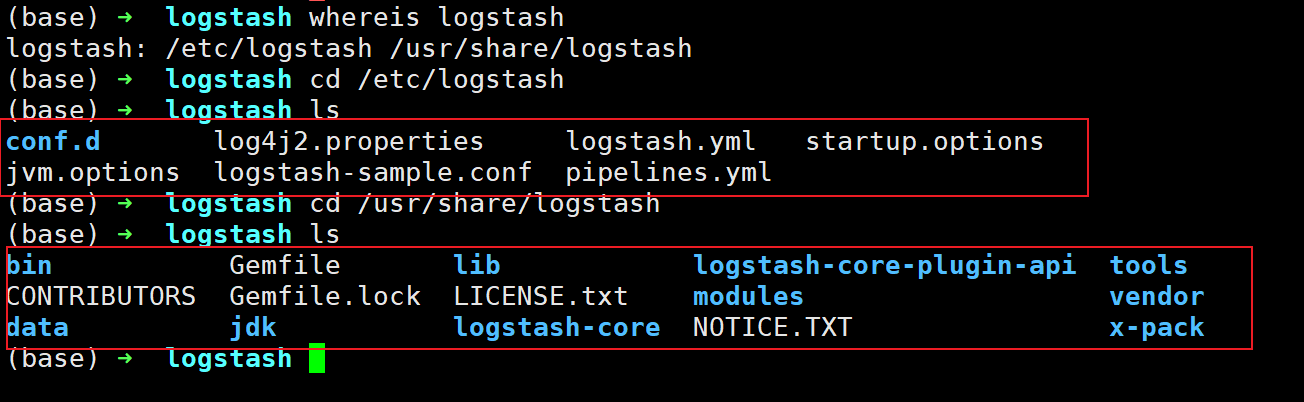
4、添加可执行文件路径
vim /etc/profile.d/logstash.sh
# 输入内容
export PATH=$PATH:/usr/share/logstash/bin
# 重新加载配置文件
source /etc/profile.d/logstash.sh5、进入配置文件目录,编辑内容
cd /etc/logstash/conf.d
vim logstash.conf
# 输入内容
input {
stdin { # 标准输入
}
}
output {
stdout { # 标准输入
codec => rubydebug # 编码格式ruby
}
} 6、启动Logstash测试
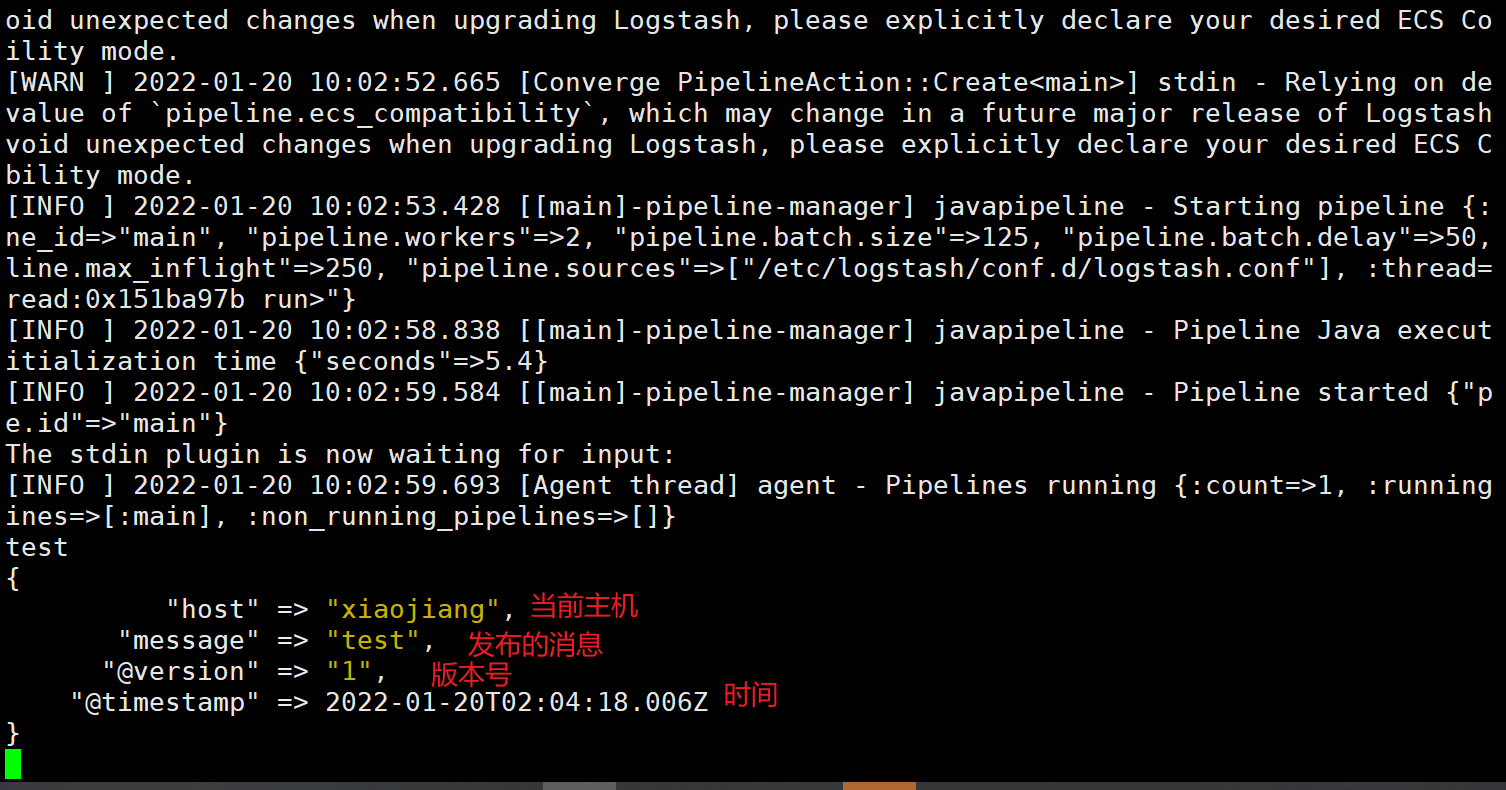
logstash -f /etc/logstash/conf.d/logstash.conf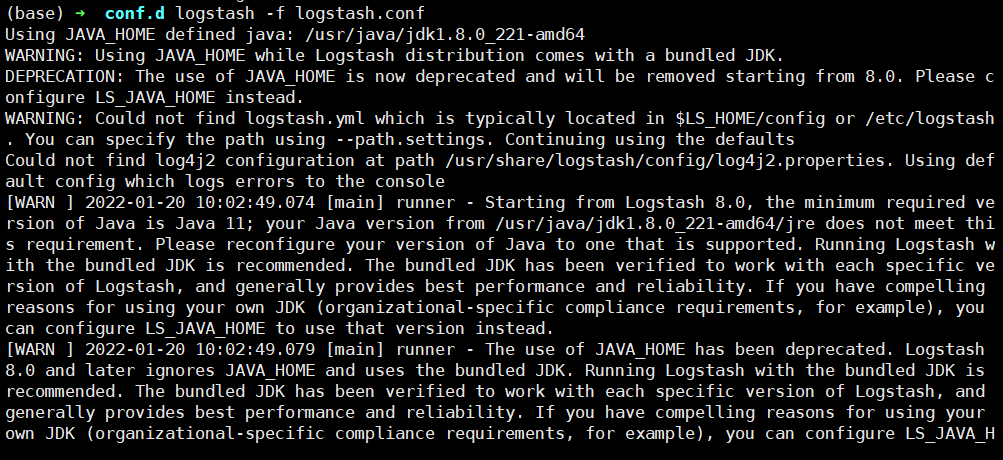
启动之后就可以输入内容
12、LogStash监听日志
1、创建日志文件测试
vim test.log
11111
22222
333332、修改配置文件
input {
file {
path => "/etc/logstash/conf.d/test.log" #可以touch一个文件,随意弄点数据
type => syslog
exclude => "*.gz" #不想监听的文件规则,基于glob匹配语法
start_position => "beginning" #第一次从头开始读取文件 beginning or end
stat_interval => "3" #定时检查文件是否更新,默认1s
}
}
output {
stdout {
codec => rubydebug
}
} 3、启动LogStash
logstash -f logstash.conf启动完成之后就会读取并输出日志
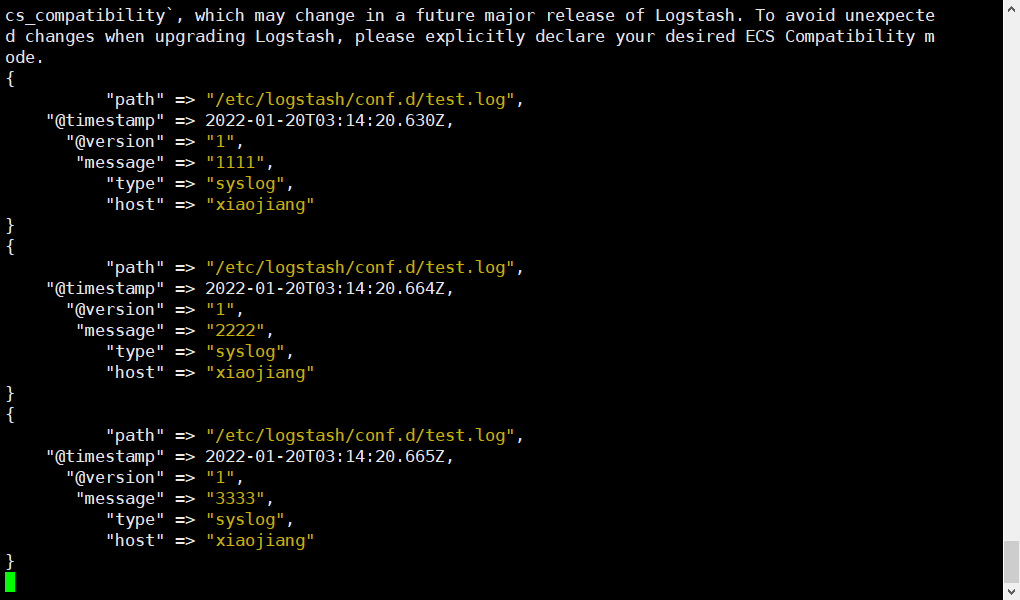
4、修改日志文件的内容,LogStash也可以监听到最新的变化
# "444"将覆盖原有的内容
echo "444" > test.log
# 或者直接编辑文件
vim test.log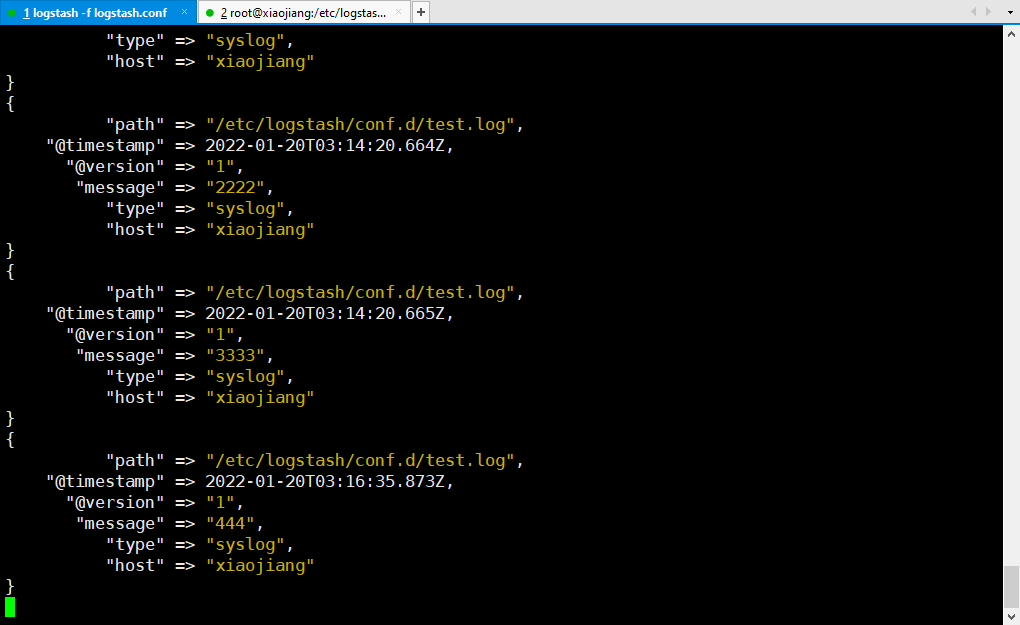
13、 LogStash Filter插件
数据从源传输到存储的过程中,Logstash的filter过滤器能够解析各个事件,识别已命名的字段结构,并将它们转换成通用的格式,以便轻松,更快速的分析和实现商业价值。
利用Grok从非结构化数据中派生出结构
利用geoip从ip地址分析出地理坐标
利用useragent从请求中分析操作系统,设备类型
Grok 插件
grok其实是带有名字的正则表达式集合,grok内置了很多pattern可以直接使用,grok语法生成器
%{ IPORHOST:clientip}
%{ NGUSER:ident}
%{ NGUSER:auth}
\[%{ HTTPDATE:timestamp} \]
"%{ WORD:verb} %{ URIPATHPARAM:request} HTTP/%{ NUMBER:httpversion} "
%{ NUMBER:response} (?:%{ NUMBER:bytes} |-) (?:"(?:%{ URI:referrer} |-)"|%{ QS:referrer} )
%{ QS:agent} %{ QS:xforwardedfor} %{ IPORHOST:host} %{ BASE10NUM:request_duration} 在配置文件中添加
input {
file {
path => "/etc/logstash/conf.d/test.log" #可以touch一个文件,随意弄点数据
type => syslog
exclude => "*.gz" #不想监听的文件规则,基于glob匹配语法
start_position => "beginning" #第一次从头开始读取文件 beginning or end
stat_interval => "3" #定时检查文件是否更新,默认1s
}
}
filter {
grok {
match => {
"message" => "%{ COMBINEDAPACHELOG} "
}
}
}
output {
stdout {
codec => rubydebug
}
} 14、LogStash配置
读取文件File
input {
file {
path => ["/var/log/*.log", "/var/log/message"]
type => "system"
start_position => "beginning"
}
} - discover_interval:每隔多久去检查一次被监听的
path下是否有新文件。默认值是 15 秒 - exclude:不想被监听的文件可以排除出去,这里跟
path一样支持 glob 展开 - sincedb_path:如果你不想用默认的
$HOME/.sincedb(Windows 平台上在C:\Windows\System32\config\systemprofile\.sincedb),可以通过这个配置定义 sincedb 文件到其他位置 - sincedb_write_interval:每隔多久写一次 sincedb 文件,默认是 15 秒
- stat_interval:每隔多久检查一次被监听文件状态(是否有更新),默认是 1 秒
- start_position:从什么位置开始读取文件数据,默认是结束位置。如果是要导入原有数据,把这个设定改成 “beginning”
增加输出字段
input { #日志数据输入来源log4j
log4j {
host => "10.104.112.175"
port => 4561
type => "simple"
}
log4j {
host => "10.104.112.175"
port => 4560
type => "detail"
}
}
filter { #logstash过滤器
if [type] == "simple" {
mutate{
split => ["message","|"] #按 | 进行split切割message
add_field => {
"requestId" => "%{ [message][0]} "
}
add_field => {
"timeCost" => "%{ [message][1]} "
}
add_field => {
"responseStatus" => "%{ [message][2]} "
}
add_field => {
"channelCode" => "%{ [message][3]} "
}
add_field => {
"transCode" => "%{ [message][4]} "
}
}
mutate {
convert => ["timeCost", "integer"] #修改timeCost字段类型为整型
}
} else if [type] == "detail" {
grok{
match => { #将message里面 TJParam后面的内容,分隔并新增为ES字段和值
"message" => ".*TJParam %{ PROG:requestId} %{ PROG:channelCode} %{ PROG:transCode} "
}
}
grok{
match => {
"message" => "(?<temMsg>(.*)(?=TJParam)/?)" #截取TJParam之前的字符作为temMsg字段的值
remove_field => ["message"] #删除字段message
}
}
mutate {
rename => { "temMsg" => "message"} #重命名字段temMsg为message
}
}
}
output {
elasticsearch {
action => "index"
hosts => "10.104.112.175:9200"
index => "supergwlog--%{ +YYYY-MM} "
}
} 15、解压缩
压缩文件
# mydata目录压缩为mydata.zip
zip -r mydata.zip mydata解压文件
# 把mydata.zip解压到当前目录
unzip mydata.zip16、关闭Kibana
# 查看进程pid
netstat -pln | grep 560117、Nginx配置默认响应
当项目重启的时候,nginx可以对请求进行默认回复,将500响应变为200
location /system_updating {
internal;
default_type application/json;
return 200 '{ "code":100000, "msg":"系统更新中,请稍等片刻"} ';
}
location /frontend_error {
internal;
default_type application/json;
return 200 '{ "code":100000, "msg":"页面异常,请截图反馈至产品助理"} ';
}
location / {
#add_header Access-Control-Allow-Origin *;
#add_header Access-Control-Allow-Headers X-Requested-With;
#add_header Access-Control-Allow-Methods GET,POST,OPTIONS;
proxy_pass http://jweb_tl_pms/;
proxy_set_header Host $host;
proxy_intercept_errors on;
error_page 400 =200 /frontend_error;
error_page 502 =200 /system_updating;
} 18、find查找文件
find / -name 'redis*'19、crontab定时任务
# 查看定时任务
crontab -l
# 编辑定时任务
crontab -e
50 14 * * 1-5 /usr/local/python/run.sh > /tmp/jiang.log 2>&1 &
9、开发工具的使用
1、IDEA
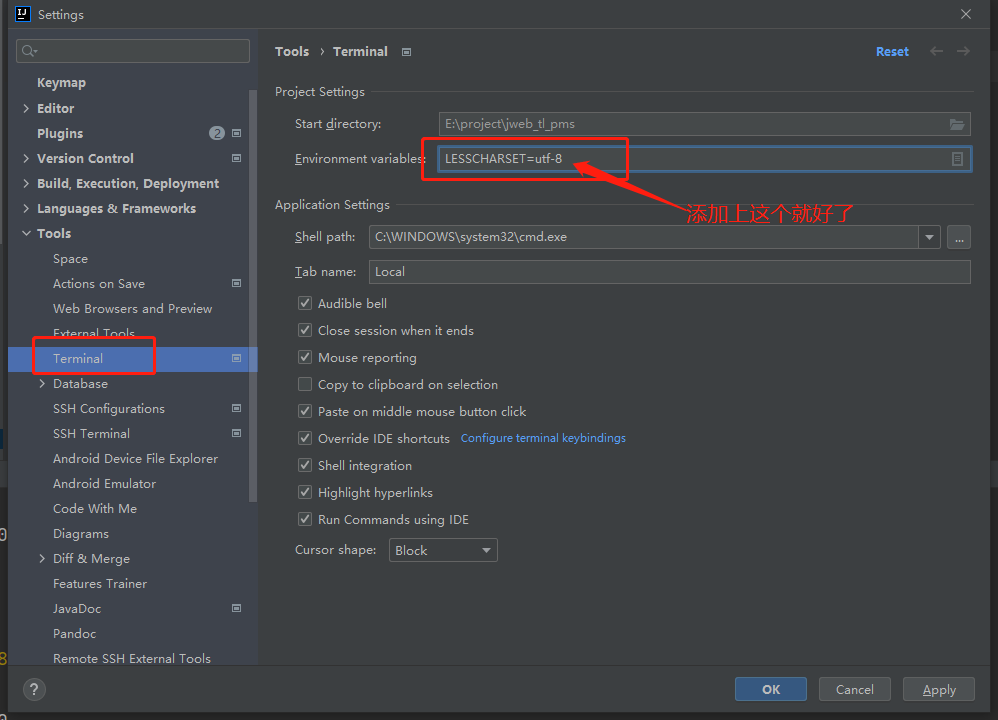
解决终端的中文乱码问题
在设置中添加上LESSCHARSET=utf-8
代码对齐快捷键
Ctrl+Alt+L
2、VsCode
多行编辑
- Alt+鼠标左键(跨行需要每行单点)
- Alt+shift+鼠标拖动选中
- 光标选中元素 Ctrl+d
自动对齐
Shift + Alt + F
10、Python笔记
1、图片转成Base64
import base64
# 读取图片数据,使用Base64编码
with open(image_path, 'rb') as f:
image = f.read()
image_base64 = str(base64.b64encode(image), encoding='utf-8')2、读取yml文件
import yaml
with open('./config.yml', 'r', encoding='utf-8-sig') as f:
file = f.read()
data = yaml.load(file, Loader=yaml.FullLoader)
print(data)- 本文链接:https://lxjblog.gitee.io/2022/07/13/%E6%97%A5%E5%B8%B8%E8%AE%B0%E5%BD%95/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。