ELK三件套
环境搭建
ElasticSearch
window
安装ElasticSearch
官网:https://www.elastic.co/cn/elasticsearch/
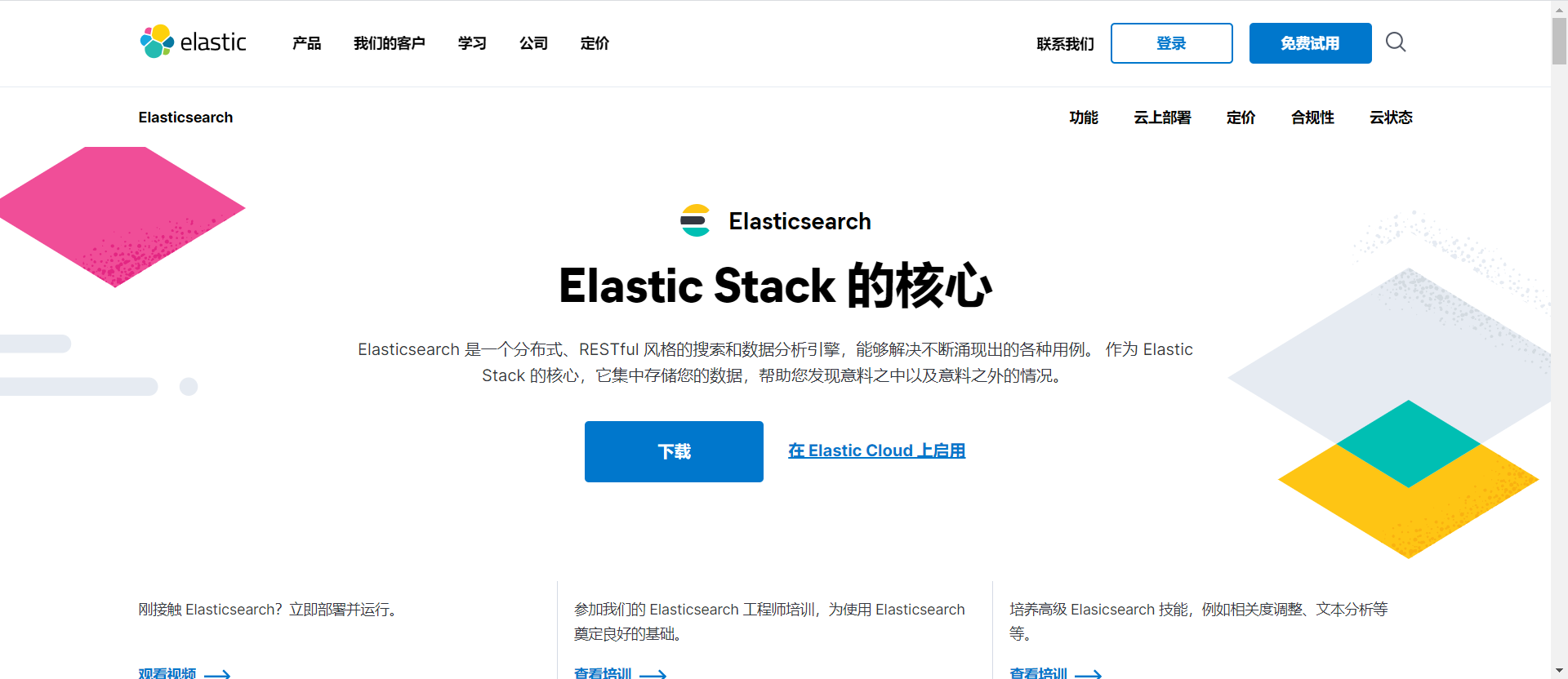
点击下载,然后选择对应的系统版本
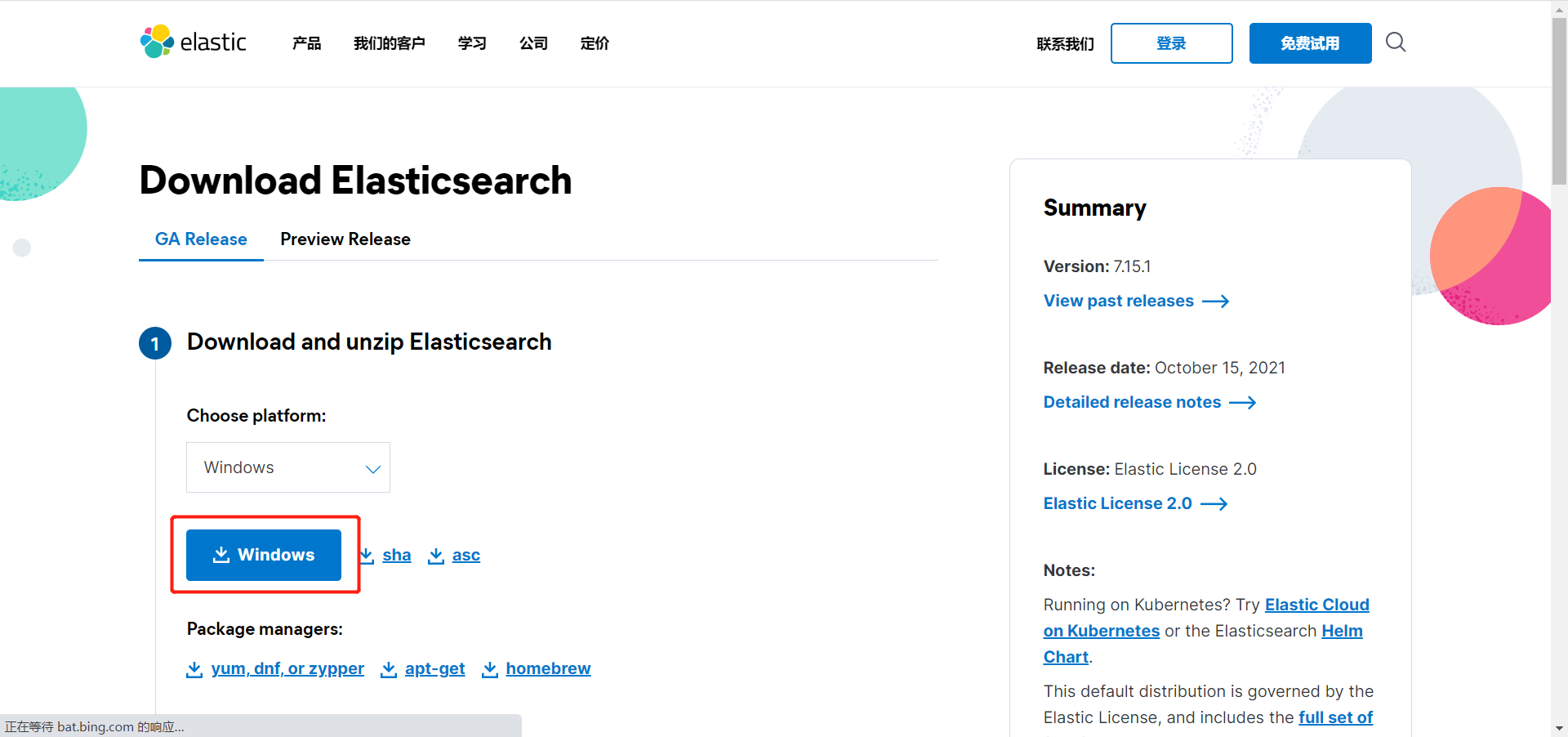
最后解压即可
文件说明:
bin 启动文件
config 配置文件
log4js 日志配置文件
jvm.options java虚拟机相关配置
elasticsearch.yml elasticsearch的配置文件
lib 相关jar包
logs 日志
modules 功能模块
plugins 插件双击elasticsearch.bat文件就可以启动了
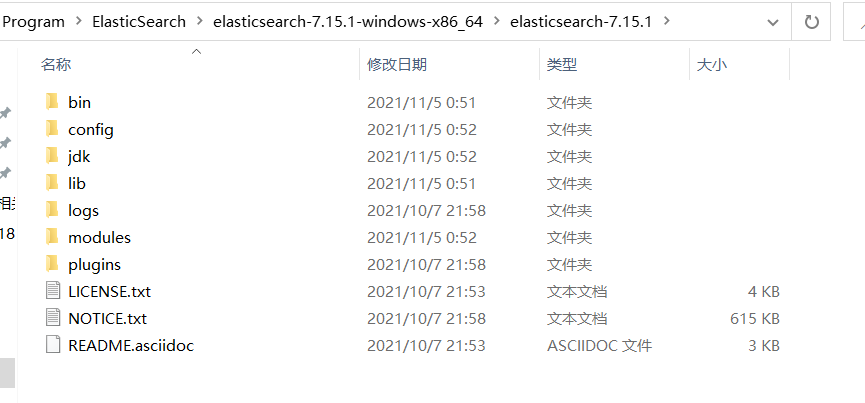
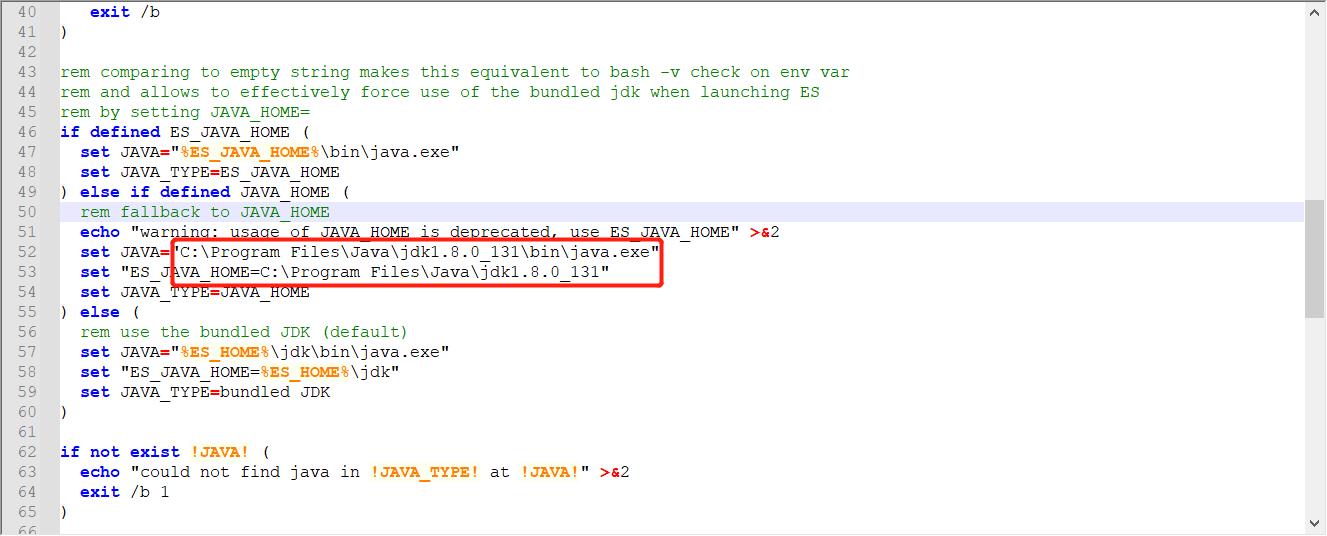
报错:启动失败
"could not find java in JAVA_HOME at "C:\Program Files\Java\jdk1.8.0_131;\bin\java.exe"
解决方案:
上方的错误原因是 jdk1.8.0_131;\bin\多出了一个分号,可以在配置文件中写死,或者配置好JAVA_HOME的路径
修改elasticsearch-env.bat文件,将 %JAVA_HOME% 直接改成 C:\Program Files\Java\jdk1.8.0_131
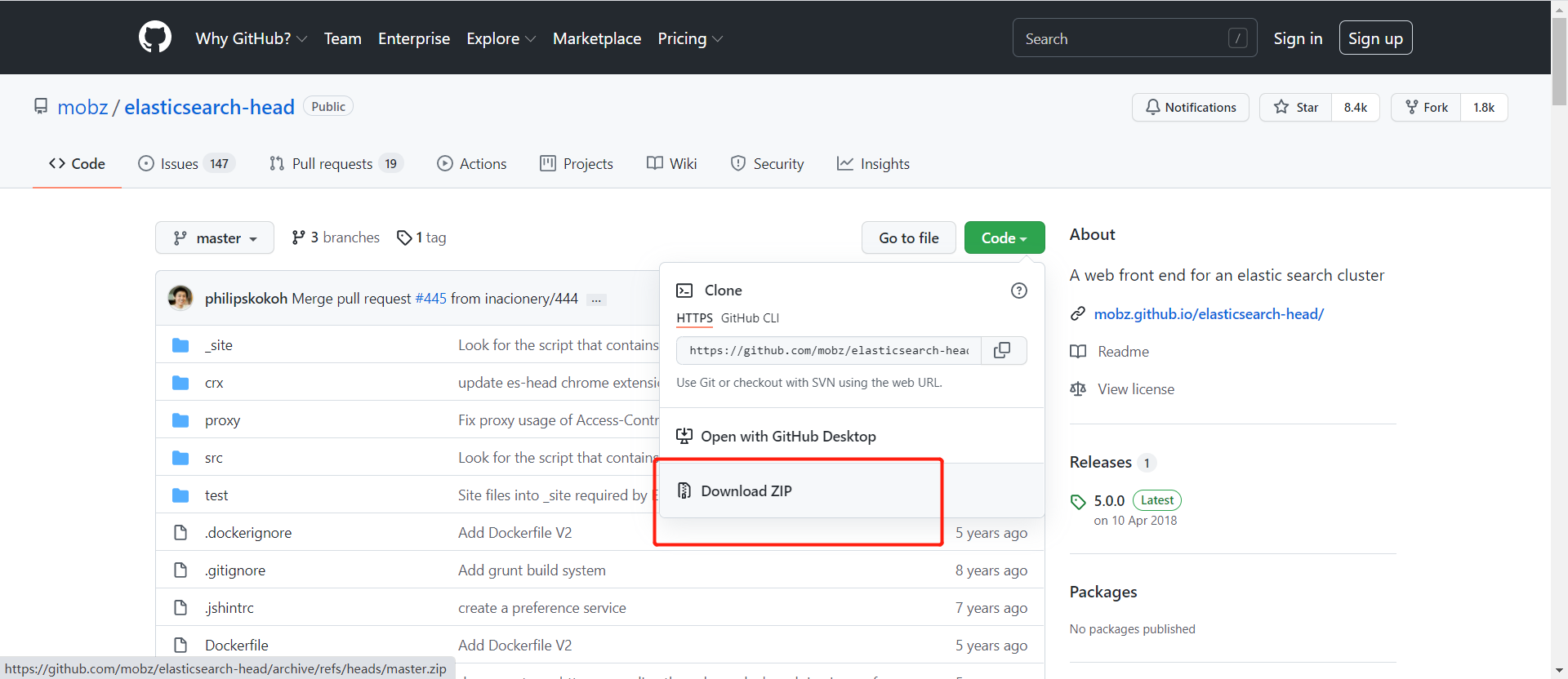
安装 ElasticSearch-head 可视化
项目网站:https://github.com/mobz/elasticsearch-head
直接下载未压缩包,然后解压
解压完成之后进入文件夹执行如下指令
# 安装依赖
npm install
# 启动
npm run start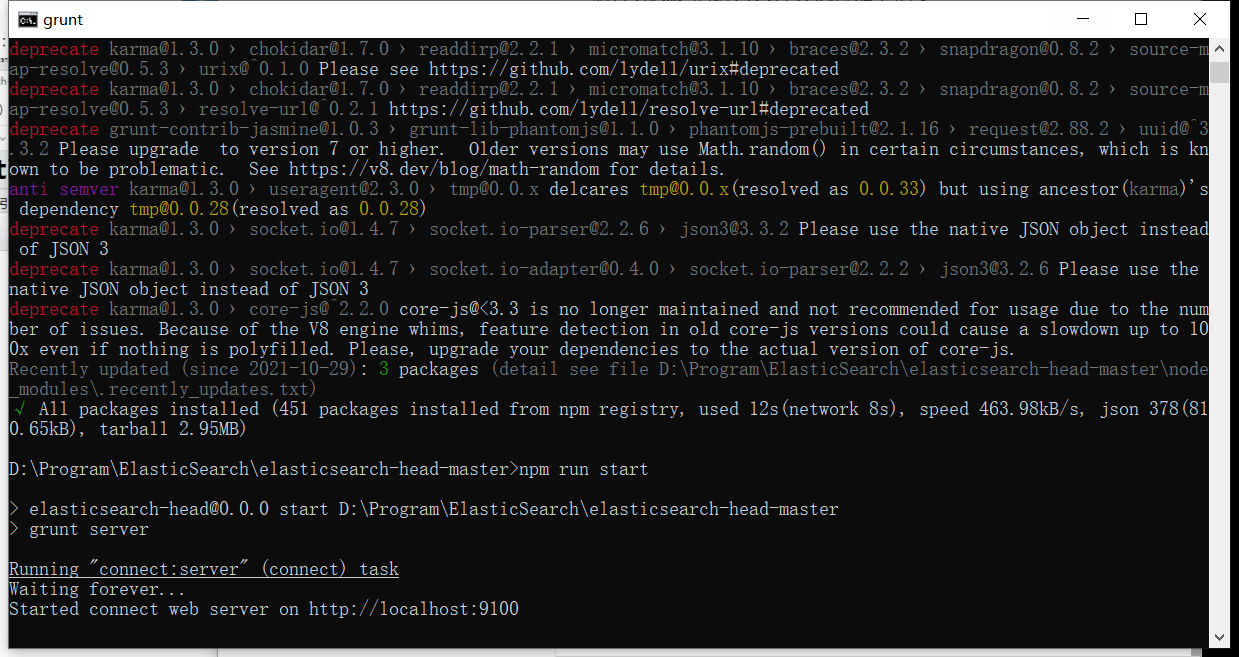
启动完成之后可以访问http://localhost:9100
但是发现点击连接会报错,这是跨域问题
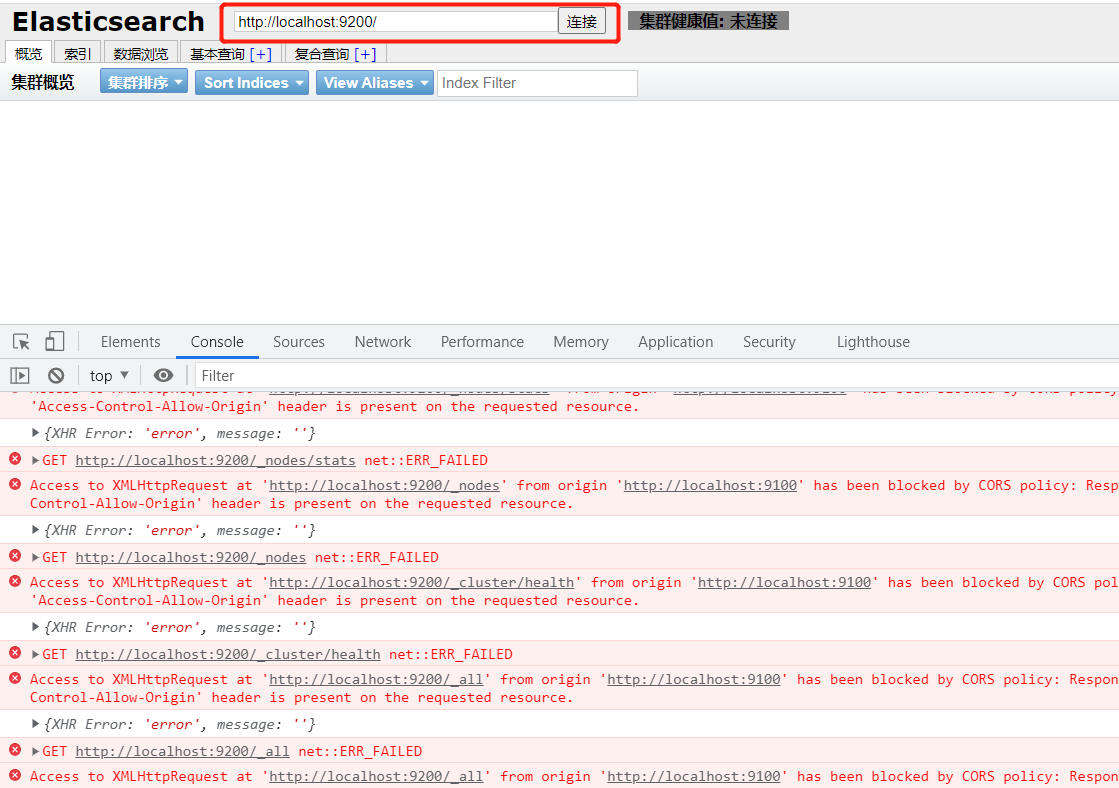
修改ElasticSearch配置文件elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"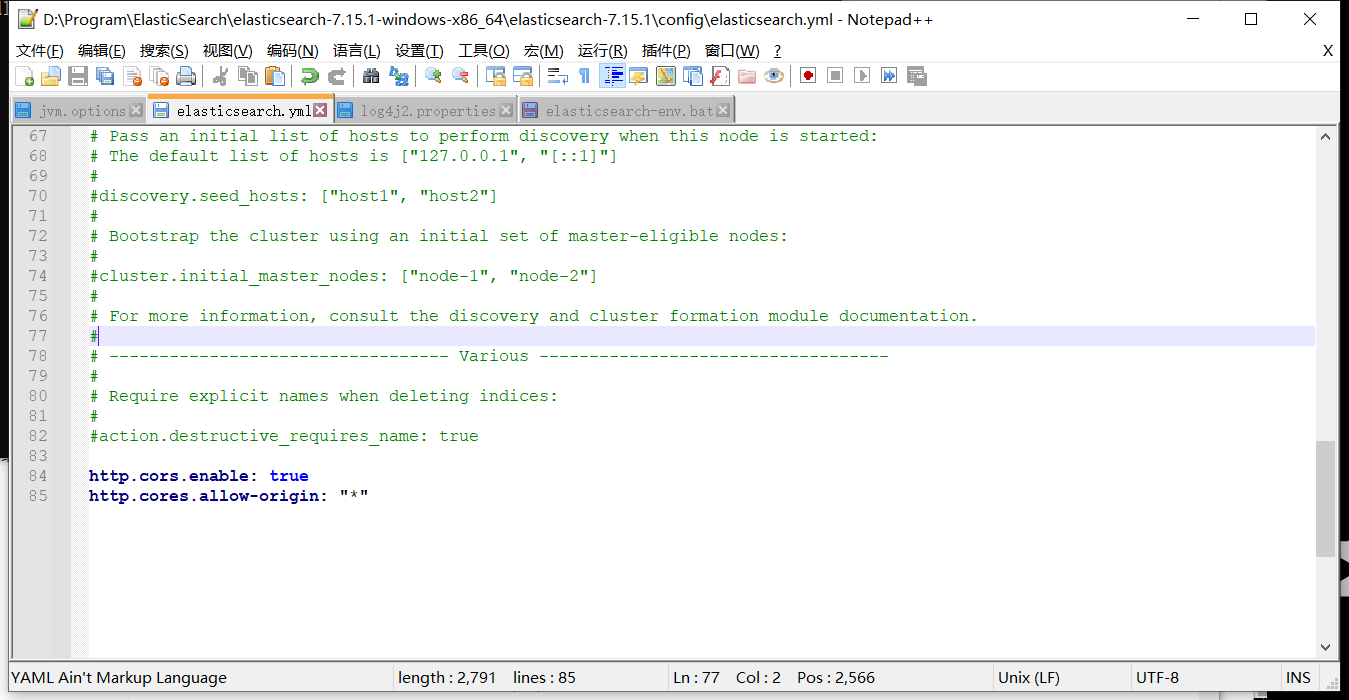
重新启动 ElasticSearch 即可
 Linux
Linux
下载安装包
1、在/etc目录下创建es文件
2、下载安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.16.3-linux-x86_64.tar.gz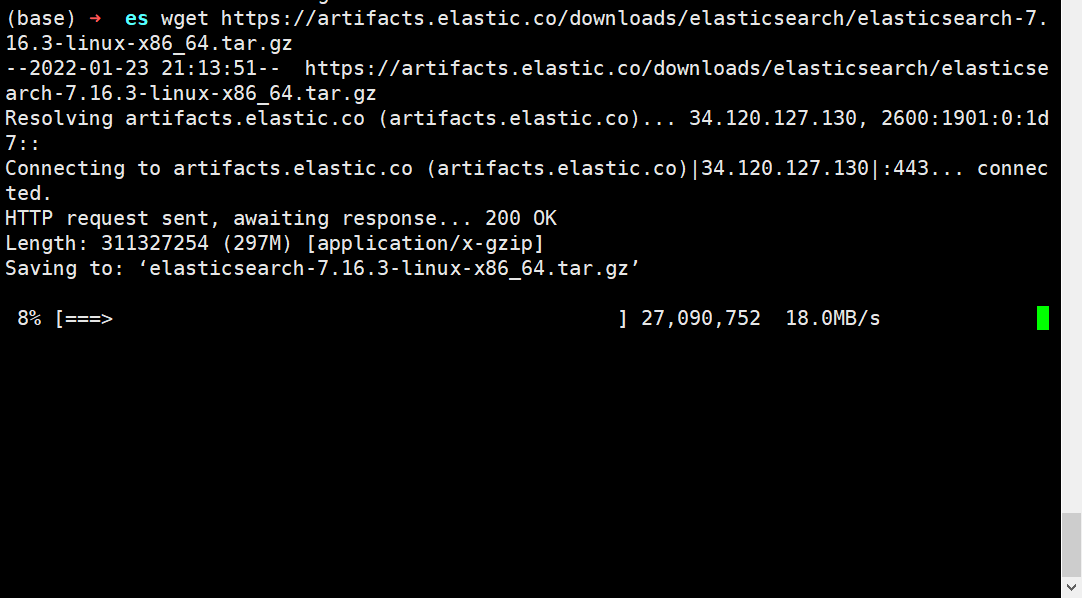
3、解压
tar -zxvf elasticsearch-7.16.3-linux-x86_64.tar.gz修改配置文件
# 1、修改jvm占用
vim jvm.options
# 增加如下配置
-Xms128m
-Xmx128m
# 2、修改elasticsearch.yml 文件
vim elasticsearch.yml
# 配置es的集群名称,默认是elasticsearch
cluster.name: my-es
# 节点名称
node.name: node-1
# 设置当前的ip地址,通过指定相同网段的其他节点会加入该集群中
network.host: 0.0.0.0
# 设置对外服务的http端口
http.port: 9200
# 设置主节点
cluster.initial_master_nodes: ["node-1"]
# 设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点
discovery.zen.ping.unicast.hosts: ["127.0.0.1","10.10.10.34:9200"]
# 解决跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"启动es
./elasticsearch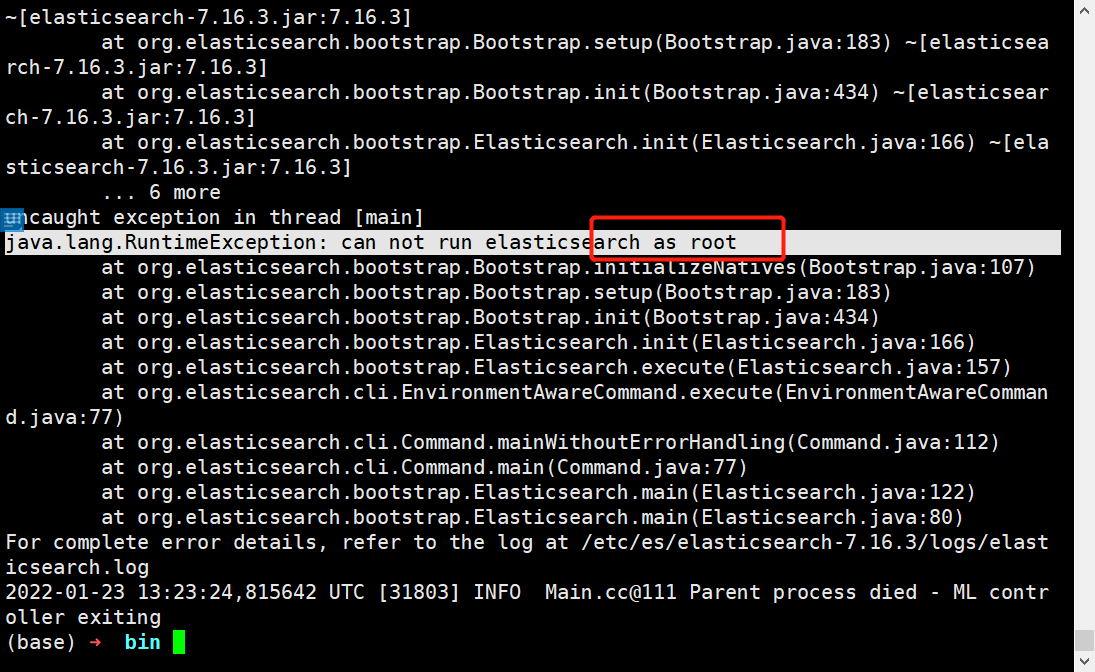
报错:因为安全问题elasticsearch 不让用root用户直接运行,所以要创建新用户
配置子用户
# 创建用户appadmin
useradd appadmin
# 为用户appadmin设置密码
passwd appadmin
# 赋予权限
chown -R appadmin /etc/es/elasticsearch-7.16.3修改本地配置
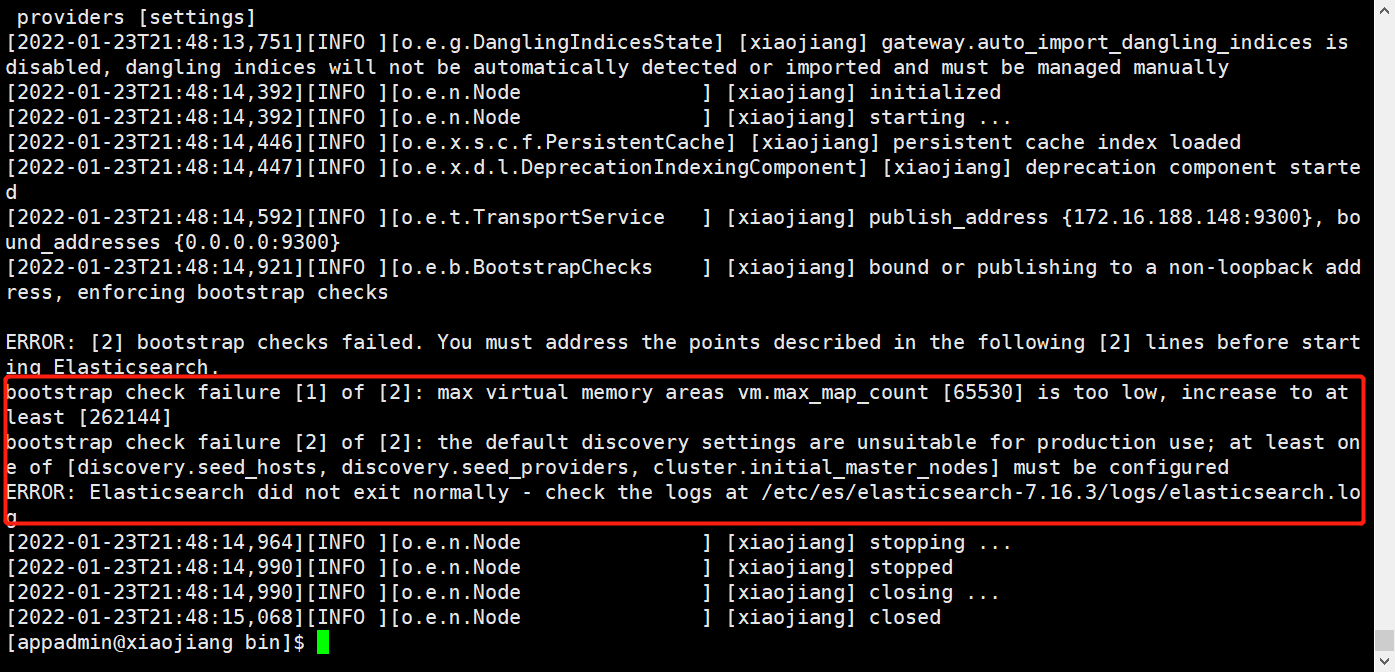
如果直接切换用户就启动会报错,因为无法创建本地文件问题,用户最大可创建文件数太小。
vim /etc/security/limits.conf
# 添加如下内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
# 注:* 代表Linux所有用户名称(比如 hadoop)
vim /etc/sysctl.conf
# 添如下配置
vm.max_map_count = 262145
# 刷新配置
sysctl -p 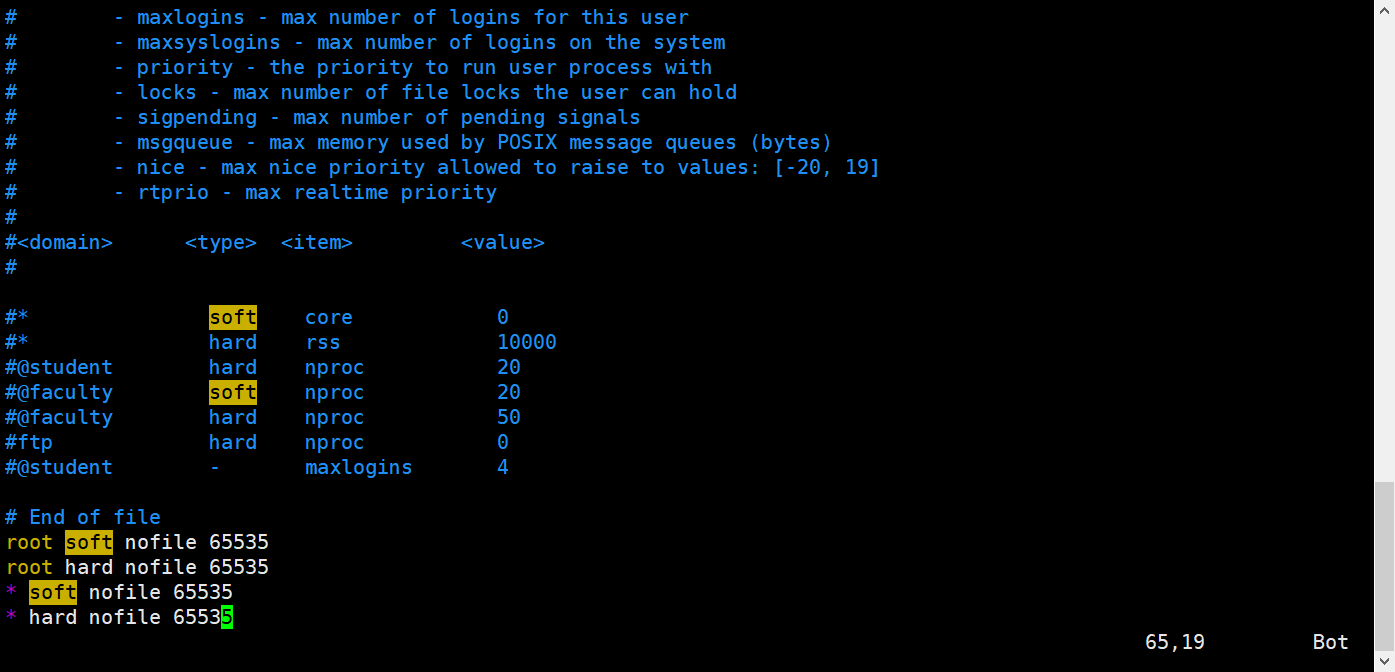
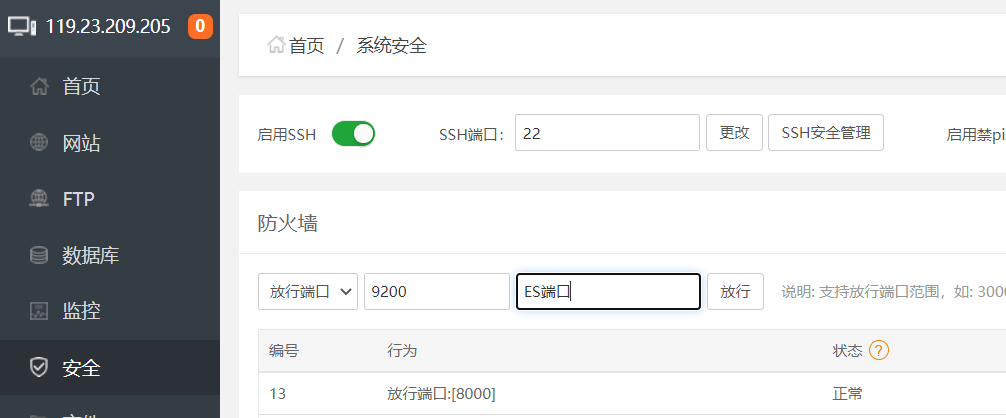
配置安全组
登录阿里云控制台,增加9200端口

在宝塔面板开放服务器端口
启动ES
# 切换用户
su appadmin
# 启动es
bin/elasticsearch
后台启动
# 后台启动
./elasticsearch -d
# 查看es进程
jpsElasticSearch-head
下载安装包
Github地址:https://github.com/mobz/elasticsearch-head
# 下载安装包
wget https://github.com/mobz/elasticsearch-head/archive/refs/heads/master.zip
# 解压
unzip master.zip
# 安装
npm insatll
# 启动
npm run start
# 后台启动
nohup npm run start &查看es数据
访问端口9100,输入es的主机和端口,并连接即可
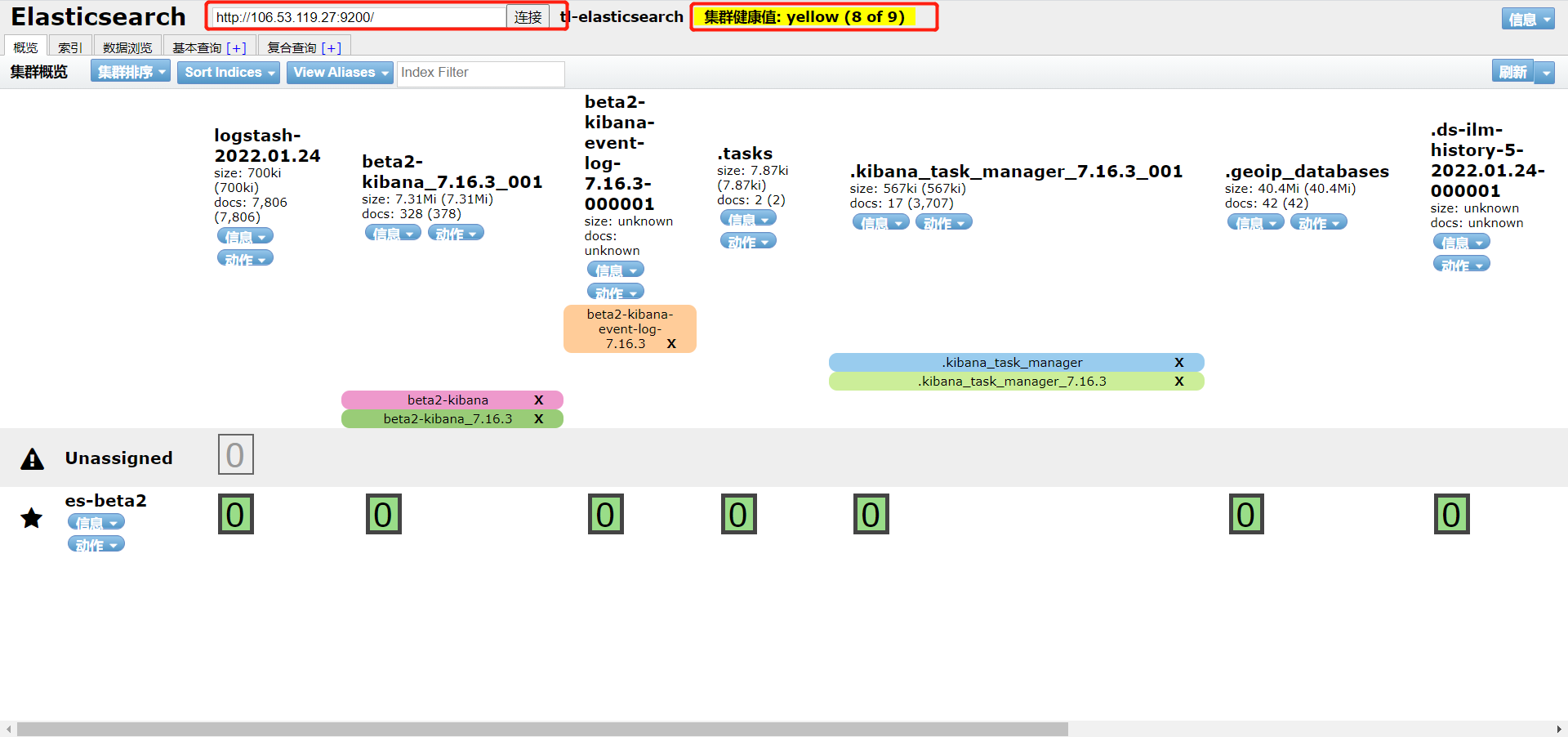
如果连接不上可以考虑两个问题:
- 没有配置es的跨域问题
- es的当前节点没有配置在主节点中
LogStash
安装logstash
# 下载
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.16.3-linux-x86_64.tar.gz
# 解压
tar -zxvf logstash-7.16.3-linux-x86_64.tar.gz修改配置文件
vim jvm.options
# 配置内存
-Xms128m
-Xmx128m创建配置文件
cd conf.d
vim logstash.conf
# 输入如下内容
input {
file {
path => ["/usr/local/jweb/jweb_tl_pms4/logs/*.log"]
type => syslog
start_position => "end" # 第一次从头开始读取文件 beginning or end
stat_interval => "3" # 定时检查文件是否更新,默认1s
}
}
output {
# 保存到es中
elasticsearch {
hosts => "106.53.119.27:9200"
index => "logstash-%{ +YYYY.MM.dd} "
}
stdout {
codec => rubydebug
}
} 启动
./logstash -f ../config/logstash.conf
# 后台启动
nohup ./logstash -f ../config/logstash.conf &Kibana
安装
# 下载安装包
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.16.3-linux-x86_64.tar.gz
# 解压
tar -zxvf kibana-7.16.3-linux-x86_64.tar.gz修改配置文件
vim kibana.yml
# 修改如下内容
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://[elasticsearch主机]:9200"
kibana.index: ".kibana"
# 设置为中文内容
i18n.locale: "zh-CN"启动
bin/kibana
# 后台启动
nohup bin/kibana &访问5601端口即可
查看数据
点击侧边栏的discover
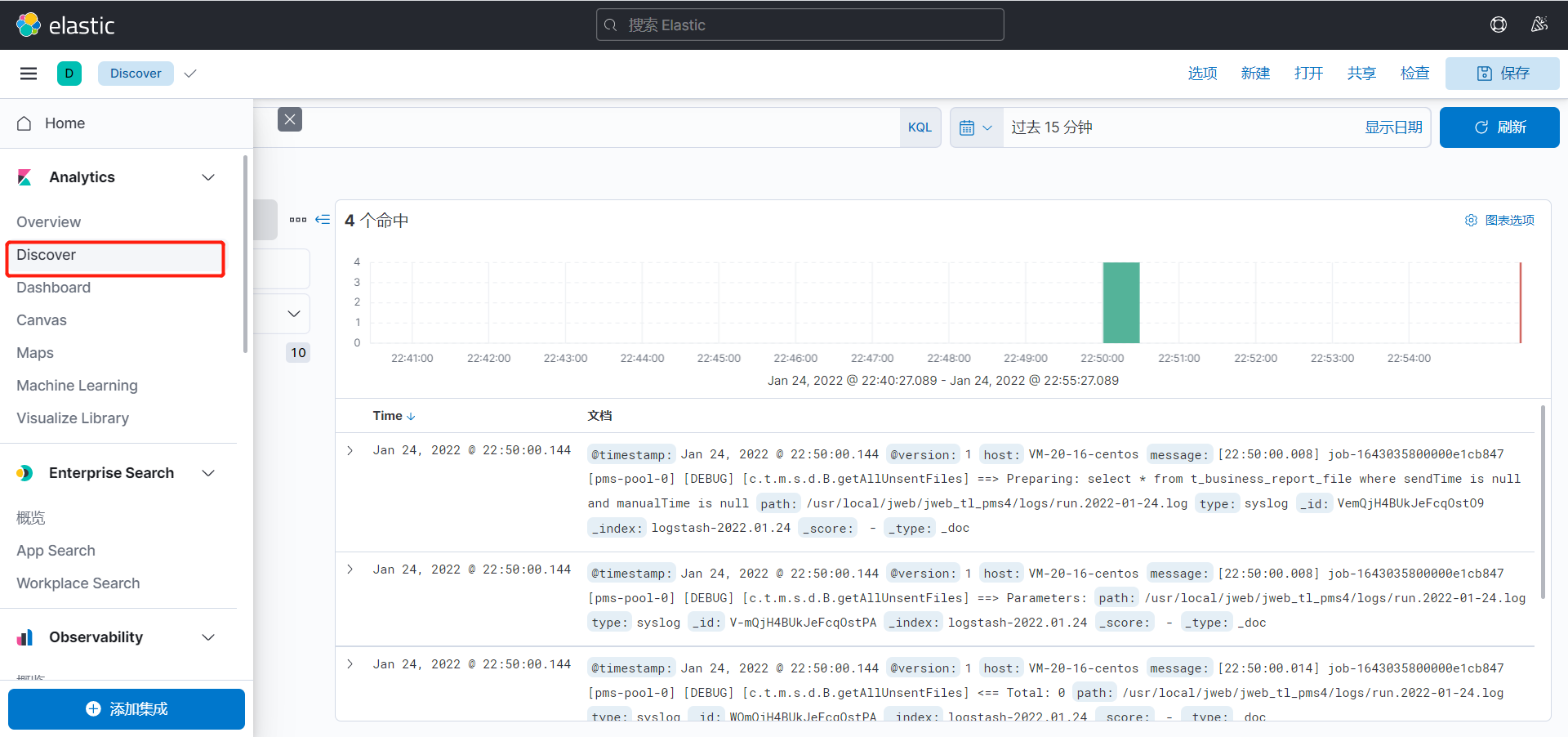
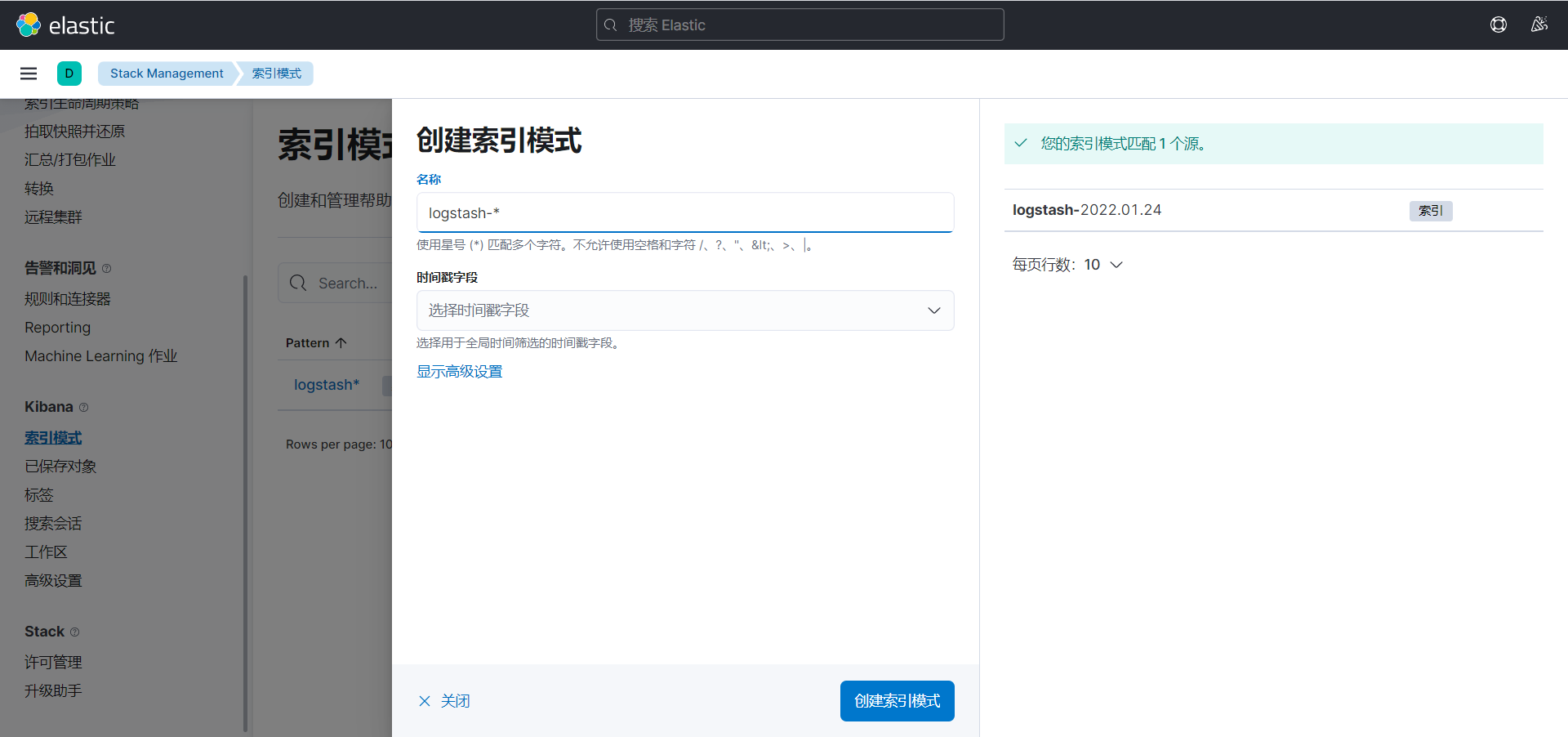
第一次进入可能会让你创建索引模式,可以匹配以有的索引,用于展示内容
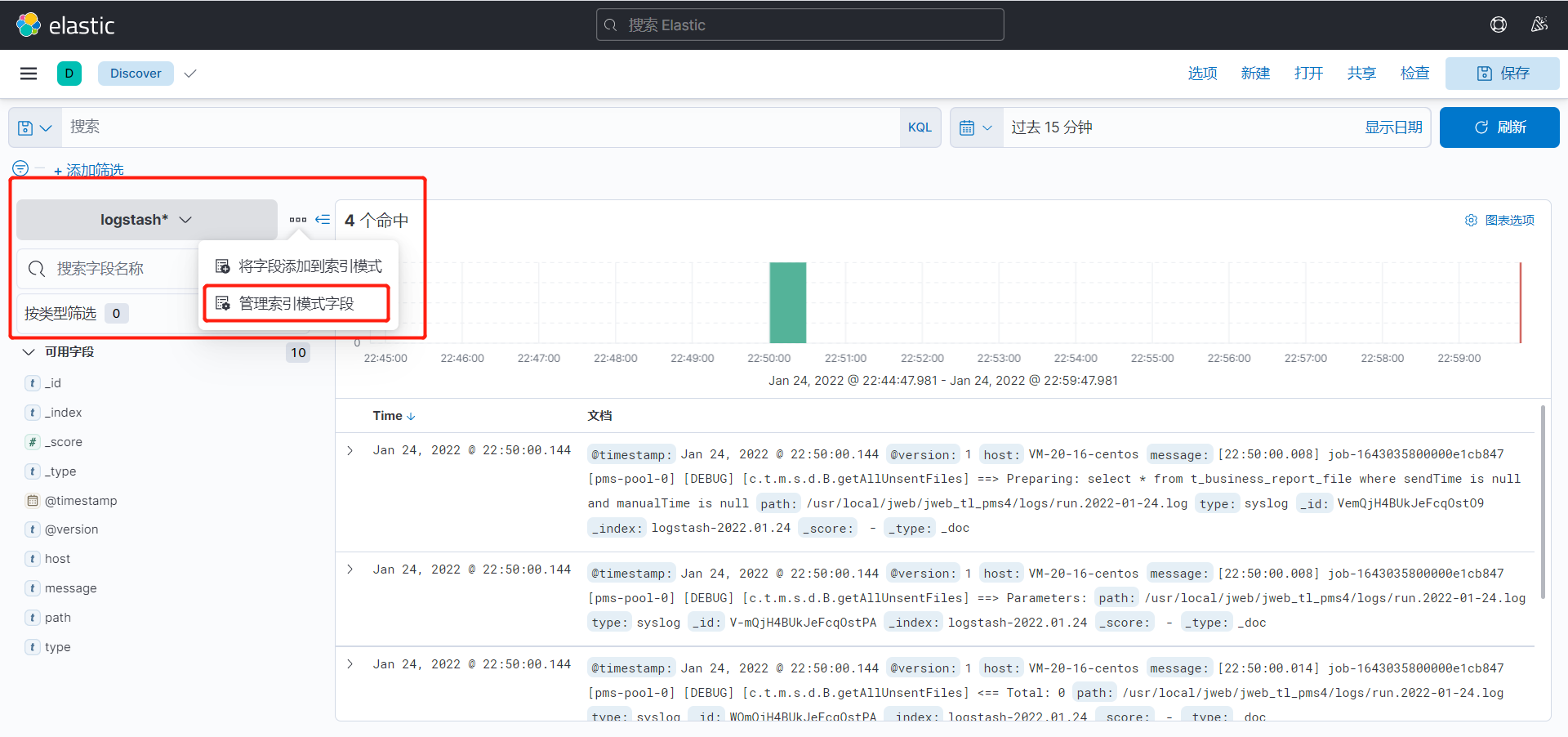
配置好之后再次点击侧边栏的discover,查看数据,目前展示的便是刚才闯将的索引模式
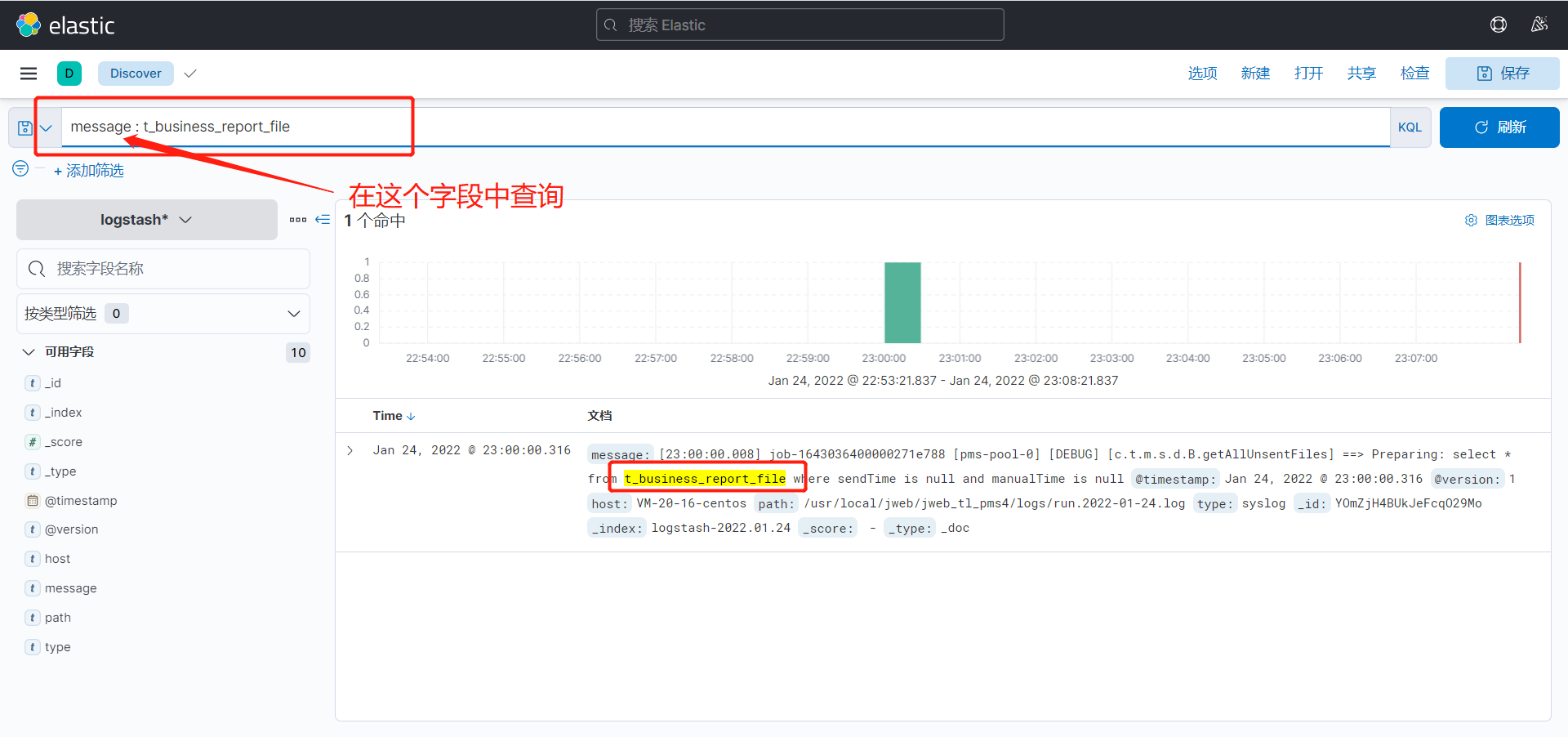
查询日志
日志内容存放在message字段中

可以使用上方的KQL(Kibana Query Language)语句进行查询
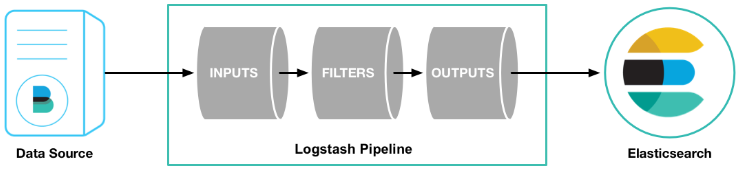
LogStash
logstash是一个数据分析软件,主要目的是分析log日志。整一套软件可以当作一个MVC模型,logstash是controller层,Elasticsearch是一个model层,kibana是view层。
input
input 及输入是指日志数据传输到Logstash中
- file:从文件系统中读取一个文件,很像UNIX命令 “tail -0a”
- syslog:监听514端口,按照RFC3164标准解析日志数据
- redis:从redis服务器读取数据,支持channel(发布订阅)和list模式。redis一般在Logstash消费集群中作为”broker”角色,保存events队列共Logstash消费。
- lumberjack:使用lumberjack协议来接收数据,目前已经改为 logstash-forwarder。
stdin { } # 从控制台中输入来源
file {
# 从文件中来
path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/*" #单一文件
# 监听文件的多个路径
path => ["E:/software/logstash-1.5.4/logstash-1.5.4/data/*.log","F:/*.log"]
# 排除不想监听的文件
exclude => "1.log"
# 添加自定义的字段
add_field => { "test"=>"test"}
# 增加标签
tags => "tag1"
# 设置新事件的标志
delimiter => "\n"
# 设置多长时间扫描目录,发现新文件
discover_interval => 15
# 设置多长时间检测文件是否修改
stat_interval => 1
# 监听文件的起始位置,默认是end
start_position => beginning
# 监听文件读取信息记录的位置
sincedb_path => "E:/software/logstash-1.5.4/logstash-1.5.4/test.txt"
# 设置多长时间会写入读取的位置信息
sincedb_write_interval => 15
}
# 系统日志方式
syslog {
# 定义类型
type => "system-syslog"
# 定义监听端口
port => 10514
}
# filebeats方式
beats {
port => 5044
} 以上文件来源file,syslog,beats 只能选择其中一种
注意:
- 文件的路径名需要使用绝对路径
- 支持globs写法
- 如果想要监听多个目标文件可以改成数组
filter
Fillters 在Logstash处理链中担任中间处理组件。经常被组合起来实现一些特定的行为来,处理匹配特定规则的事件流。
- grok:解析无规则的文字并转化为有结构的格式。Grok 是目前最好的方式来将无结构的数据转换为有结构可查询的数据。有120多种匹配规则,会有一种满足你的需要。
- mutate:mutate filter 允许改变输入的文档,你可以从命名,删除,移动或者修改字段在处理事件的过程中。
- drop:丢弃一部分events不进行处理,例如:debug events。
- clone:拷贝 event,这个过程中也可以添加或移除字段。
- geoip:添加地理信息(为前台kibana图形化展示使用)
filter {
# 定义数据的格式
grok {
match => { "message" => "%{ DATA:timestamp} \|%{ IP:serverIp} \|%{ IP:clientIp} \|%{ DATA:logSource} \|%{ DATA:userId} \|%{ DATA:reqUrl} \|%{ DATA:reqUri} \|%{ DATA:refer} \|%{ DATA:device} \|%{ DATA:textDuring} \|%{ DATA:duringTime:int} \|\|"}
}
#定义时间戳的格式
date {
match => [ "timestamp", "yyyy-MM-dd-HH:mm:ss" ]
# match => ["timeLocal": "dd/MMM/yyyy:HH:mm:ss Z"]
locale => "cn"
}
# 定义客户端的IP是哪个字段(上面定义的数据格式)
geoip {
source => "clientIp"
}
# 需要进行转换的字段,这里是将访问的时间转成int,再传给Elasticsearch
mutate {
convert => ["duringTime", "integer"]
}
} 常见的日志样例
内容: - 2015-04-29 13:04:23,733 [main] INFO (api.batch.ThreadPoolWorker) Command-line options for this run:
正则:- %{ TIMESTAMP_ISO8601:time} \[%{ WORD:main} \] %{ LOGLEVEL:loglevel} \(%{ JAVACLASS:class} \) %{ GREEDYDATA:mydata} output
outputs是logstash处理管道的最末端组件。一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。
elasticsearch:如果你计划将高效的保存数据,并且能够方便和简单的进行查询
file:将event数据保存到文件中
graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。http://graphite.wikidot.com/
statsd:statsd是一个统计服务,比如技术和时间统,通过udp通讯,聚合一个或者多个后台服务,如果你已经开始使用statsd,该选项对你应该很有用
output {
#将输出保存到elasticsearch,如果没有匹配到时间就不保存,因为日志里的网址参数有些带有换行
elasticsearch {
host => "127.0.0.1:9200"
index => "logstash-%{ +YYYY.MM.dd} "
}
#输出到stdout
# stdout { codec => rubydebug }
#定义访问数据的用户名和密码
# user => webService
# password => 1q2w3e4r
}
Codecs
codecs 是基于数据流的过滤器,它可以作为input,output的一部分配置。Codecs可以帮助你轻松的分割发送过来已经被序列化的数据。流行的codecs包括 json,msgpack,plain(text)。
- json:使用json格式对数据进行编码/解码
- multiline:将汇多个事件中数据汇总为一个单一的行。比如:java异常信息和堆栈信息
获取完整的配置信息,请参考 Logstash文档中 “plugin configuration”部分
监听多个类型的文件
input {
file {
path => ["/usr/local/jweb/jweb_tl_pms4/logs/run.*.log"]
type => "run"
start_position => "end"
stat_interval => "3"
}
file {
path => ["/usr/local/jweb/jweb_tl_pms4/logs/error.*.log"]
type => "error"
start_position => "end"
stat_interval => "3"
}
}
output {
if [type] == "run" {
elasticsearch {
hosts => "106.53.119.27:9200"
index => "run.%{ +YYYY.MM.dd} .log"
}
}
if [type] == "error" {
elasticsearch {
hosts => "106.53.119.27:9200"
index => "error.%{ +YYYY.MM.dd} .log"
}
}
stdout {
codec => rubydebug
}
} - 本文链接:https://lxjblog.gitee.io/2023/08/03/ELK/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。