ElasticSearch
1、环境搭建
ElasticSearch
window
安装ElasticSearch
官网:https://www.elastic.co/cn/elasticsearch/
点击下载,然后选择对应的系统版本
最后解压即可
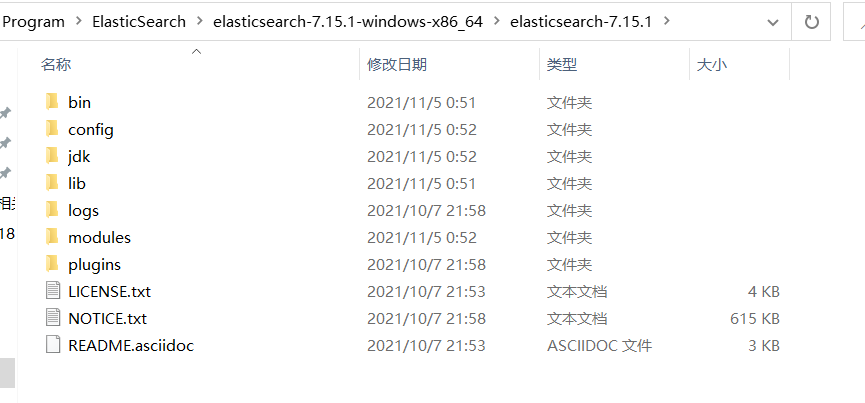
文件说明:
bin 启动文件
config 配置文件
log4js 日志配置文件
jvm.options java虚拟机相关配置
elasticsearch.yml elasticsearch的配置文件
lib 相关jar包
logs 日志
modules 功能模块
plugins 插件双击elasticsearch.bat文件就可以启动了
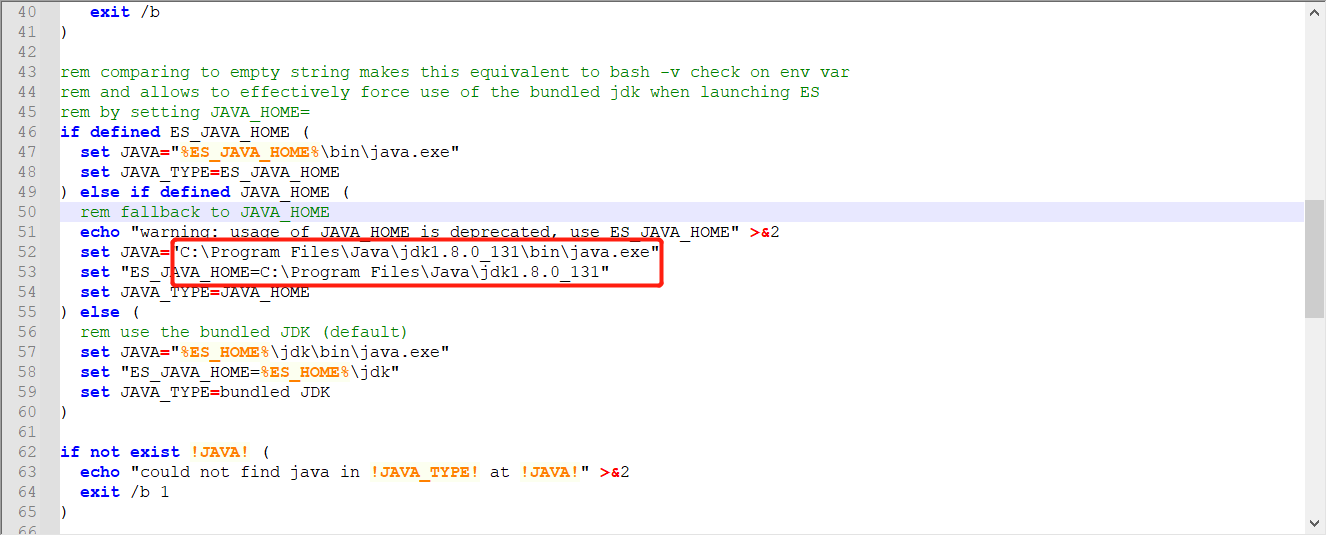
报错:启动失败
"could not find java in JAVA_HOME at "C:\Program Files\Java\jdk1.8.0_131;\bin\java.exe"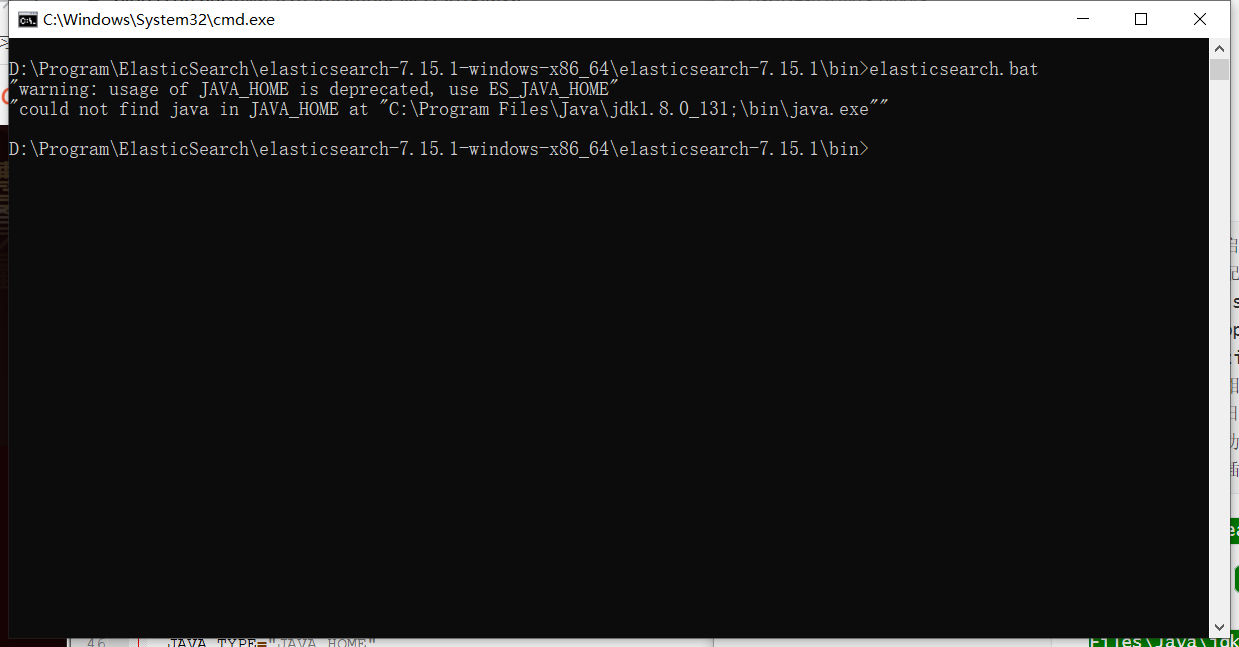
解决方案:
上方的错误原因是 jdk1.8.0_131;\bin\多出了一个分号,可以在配置文件中写死,或者配置好JAVA_HOME的路径
修改elasticsearch-env.bat文件,将 %JAVA_HOME% 直接改成 C:\Program Files\Java\jdk1.8.0_131
安装 ElasticSearch-head 可视化
项目网站:https://github.com/mobz/elasticsearch-head
直接下载未压缩包,然后解压
解压完成之后进入文件夹执行如下指令
# 安装依赖
npm install
# 启动
npm run start
启动完成之后可以访问http://localhost:9100
但是发现点击连接会报错,这是跨域问题
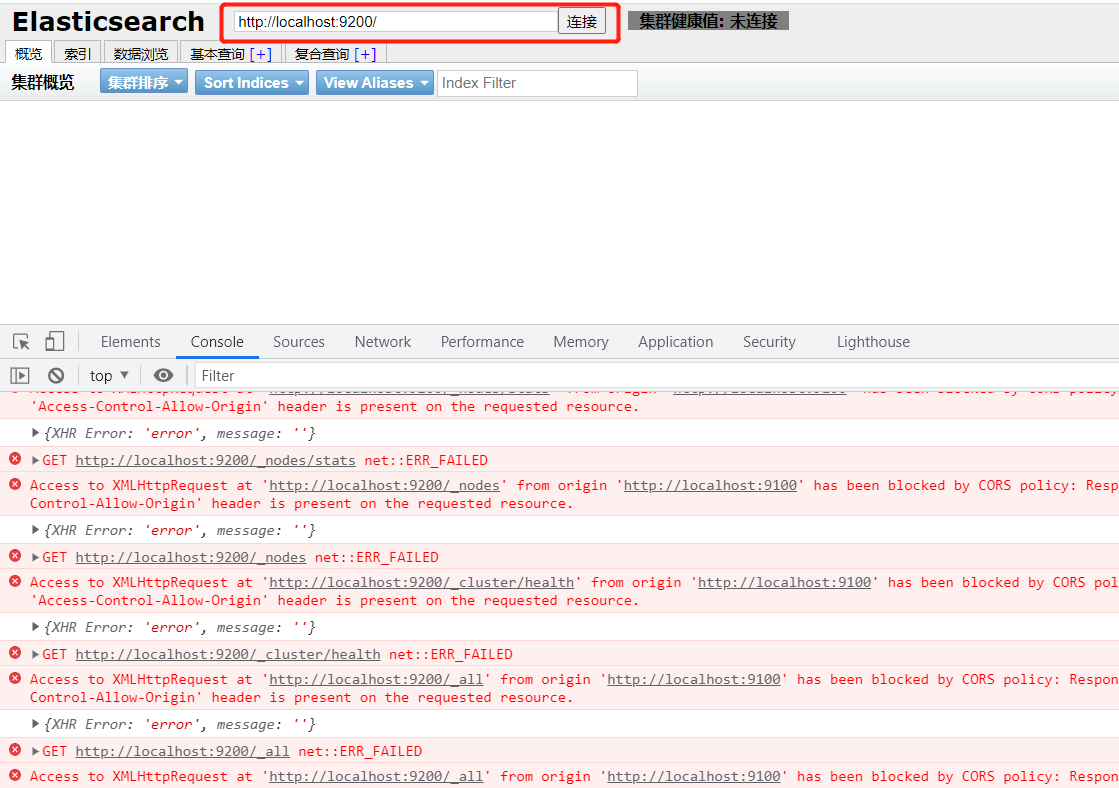
修改ElasticSearch配置文件elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"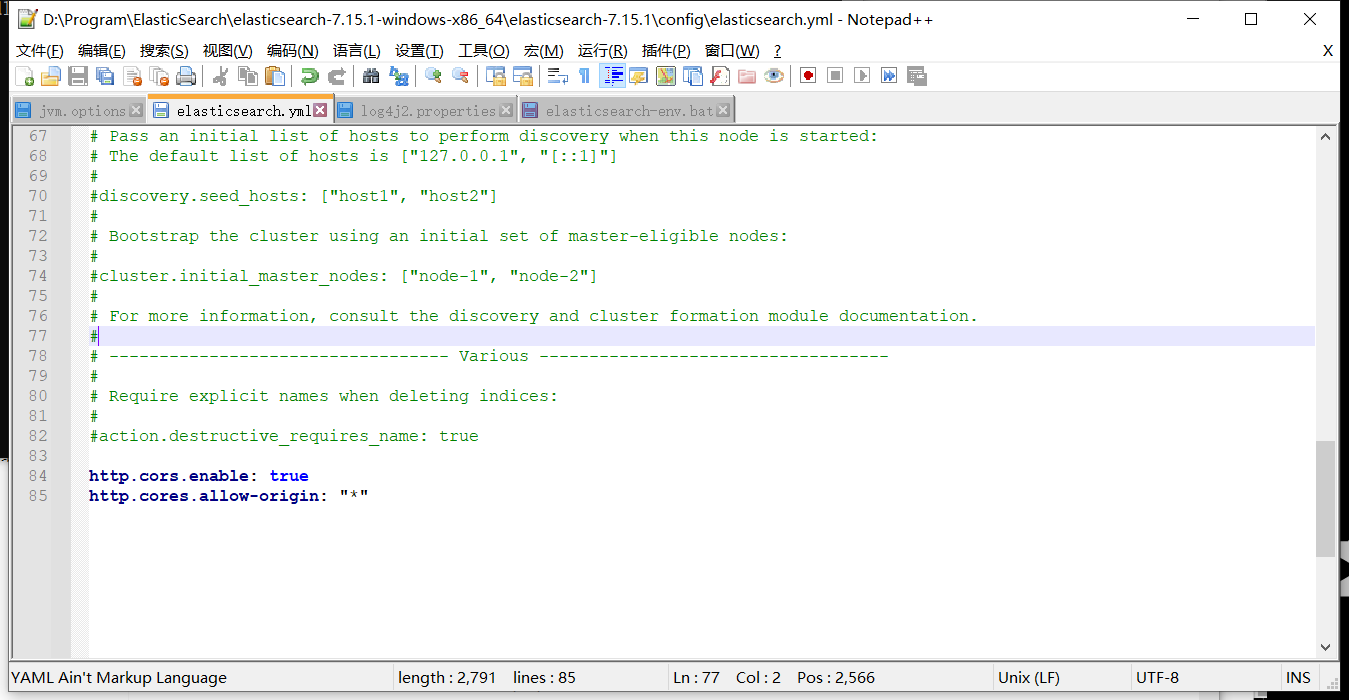
重新启动 ElasticSearch 即可
 Linux
Linux
下载安装包
1、在/etc目录下创建es文件
2、下载安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.16.3-linux-x86_64.tar.gz
3、解压
tar -zxvf elasticsearch-7.16.3-linux-x86_64.tar.gz修改配置文件
# 1、修改jvm占用
vim jvm.options
# 增加如下配置
-Xms128m
-Xmx128m
# 2、修改elasticsearch.yml 文件
vim elasticsearch.yml
# 配置es的集群名称,默认是elasticsearch
cluster.name: my-es
# 节点名称
node.name: node-1
# 设置当前的ip地址,通过指定相同网段的其他节点会加入该集群中
network.host: 0.0.0.0
# 设置对外服务的http端口
http.port: 9200
# 设置主节点
cluster.initial_master_nodes: ["node-1"]
# 设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点
discovery.zen.ping.unicast.hosts: ["127.0.0.1","10.10.10.34:9200"]
# 解决跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"启动es
./elasticsearch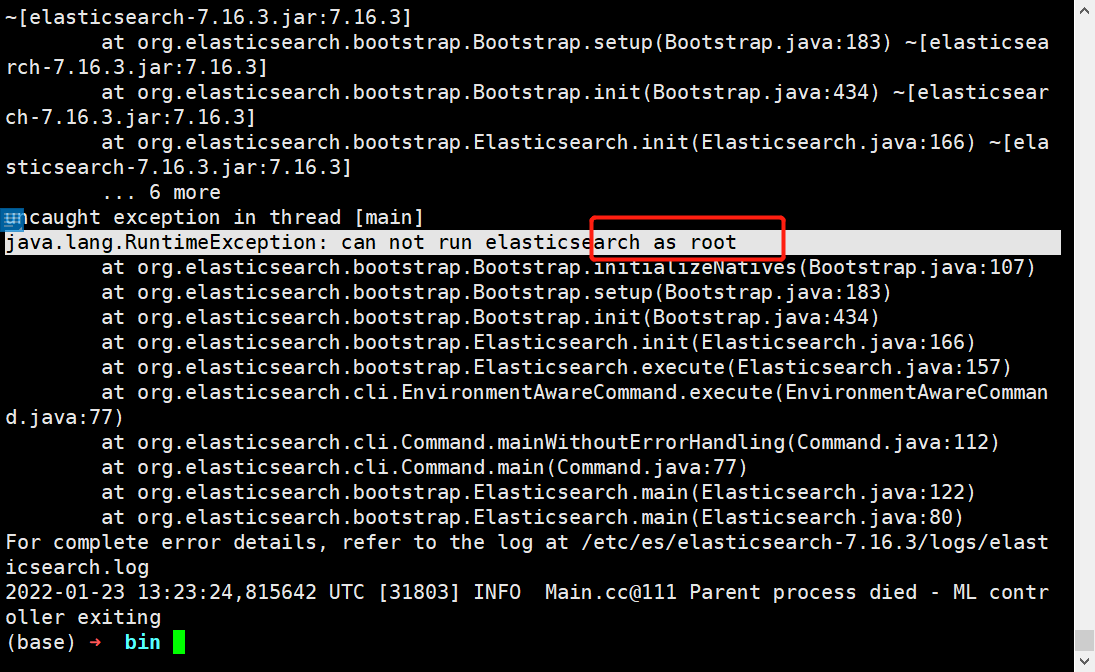
报错:因为安全问题elasticsearch 不让用root用户直接运行,所以要创建新用户
配置子用户
# 创建用户appadmin
useradd appadmin
# 为用户appadmin设置密码
passwd appadmin
# 赋予权限
chown -R appadmin /etc/es/elasticsearch-7.16.3修改本地配置
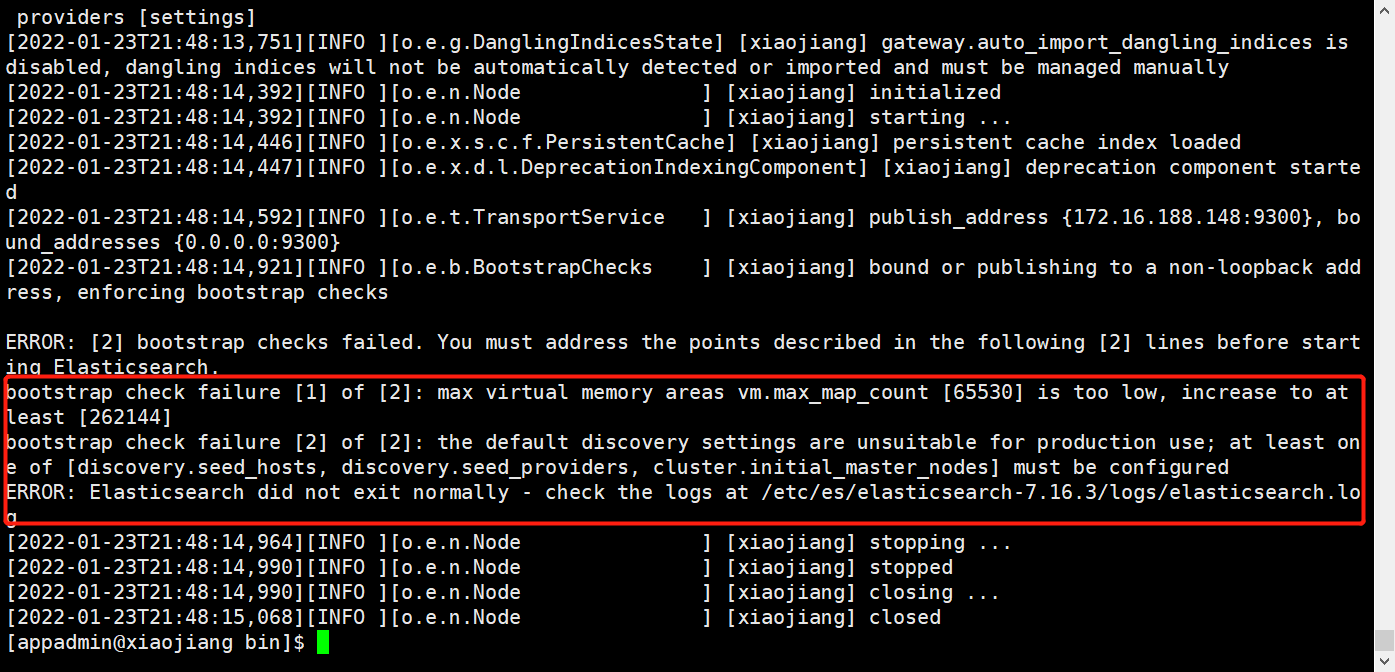
如果直接切换用户就启动会报错,因为无法创建本地文件问题,用户最大可创建文件数太小。
vim /etc/security/limits.conf
# 添加如下内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
# 注:* 代表Linux所有用户名称(比如 hadoop)
vim /etc/sysctl.conf
# 添如下配置
vm.max_map_count = 262145
# 刷新配置
sysctl -p 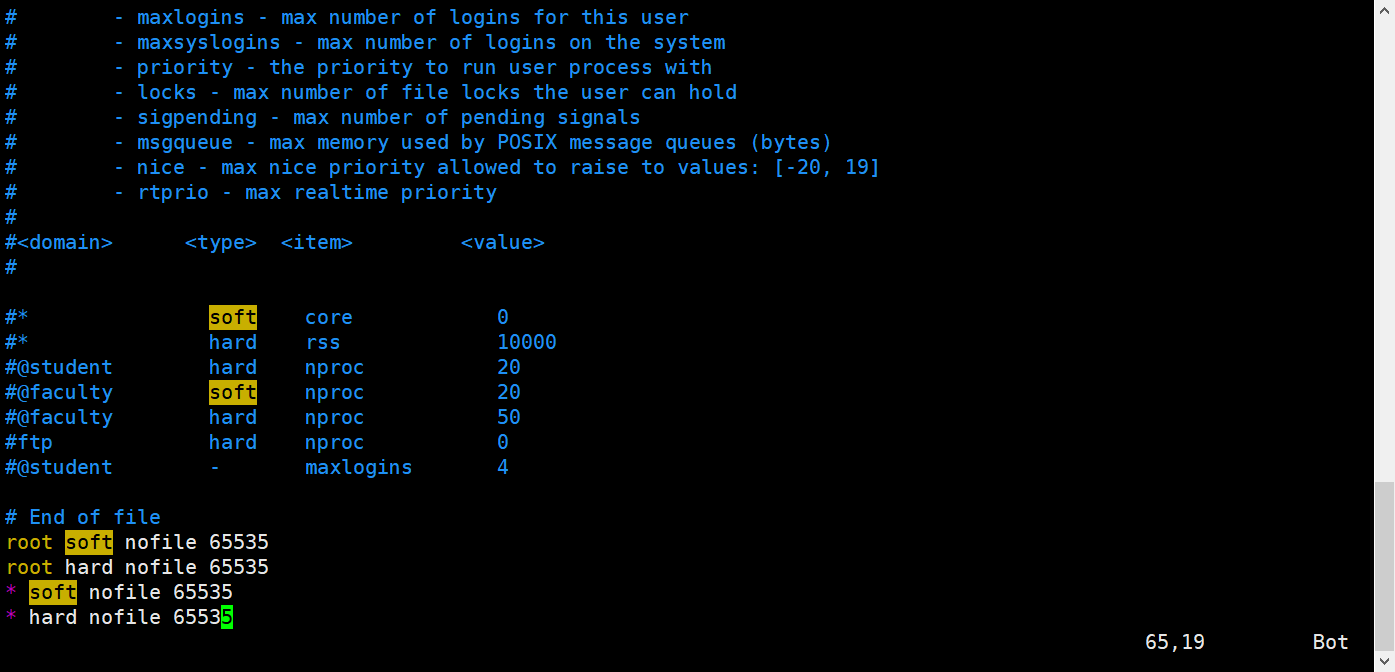
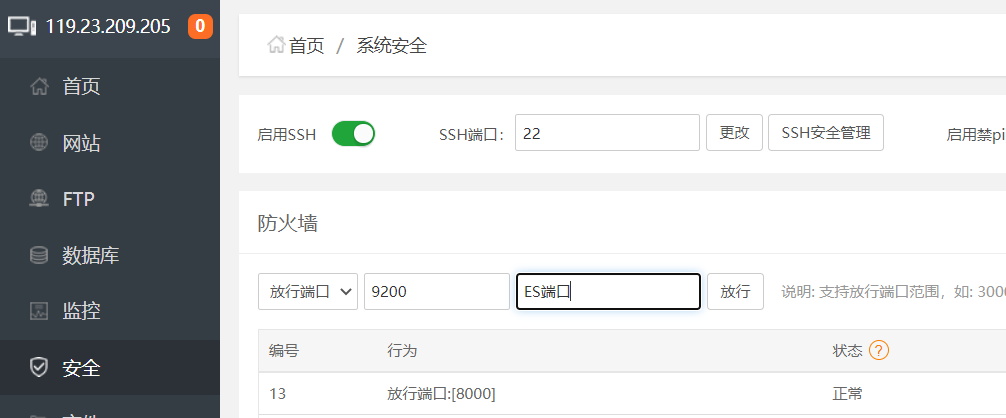
配置安全组
登录阿里云控制台,增加9200端口

在宝塔面板开放服务器端口
启动ES
# 切换用户
su appadmin
# 启动es
bin/elasticsearch
后台启动
# 后台启动
./elasticsearch -d
# 查看es进程
jpsElasticSearch-head
下载安装包
Github地址:https://github.com/mobz/elasticsearch-head
# 下载安装包
wget https://github.com/mobz/elasticsearch-head/archive/refs/heads/master.zip
# 解压
unzip master.zip
# 安装
npm insatll
# 启动
npm run start
# 后台启动
nohup npm run start &查看es数据
访问端口9100,输入es的主机和端口,并连接即可
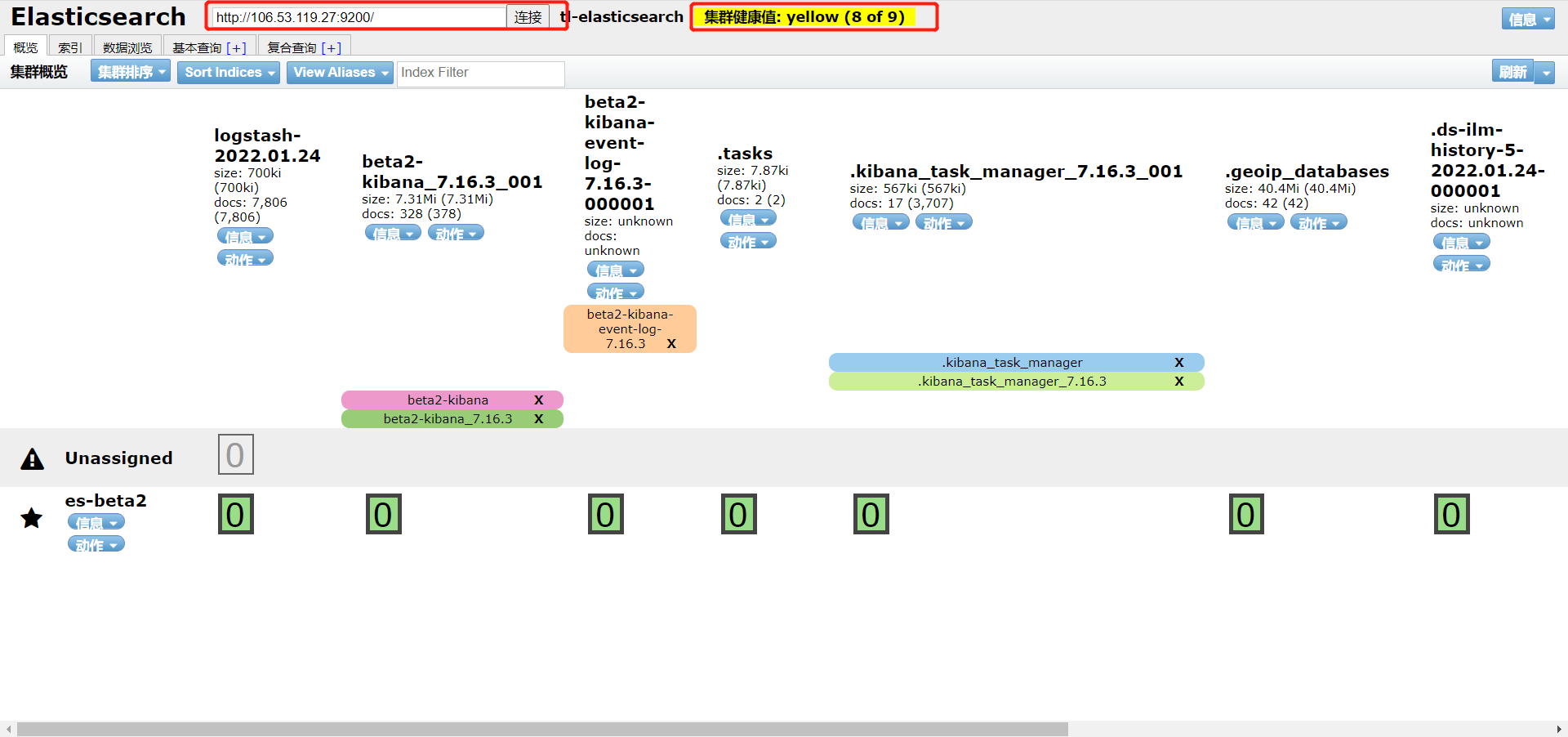
如果连接不上可以考虑两个问题:
- 没有配置es的跨域问题
- es的当前节点没有配置在主节点中
Kibana
安装
# 下载安装包
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.16.3-linux-x86_64.tar.gz
# 解压
tar -zxvf kibana-7.16.3-linux-x86_64.tar.gz修改配置文件
vim kibana.yml
# 修改如下内容
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://[elasticsearch主机]:9200"
kibana.index: ".kibana"
# 设置为中文内容
i18n.locale: "zh-CN"启动
bin/kibana
# 后台启动
nohup bin/kibana &访问5601端口即可
查看数据
点击侧边栏的discover
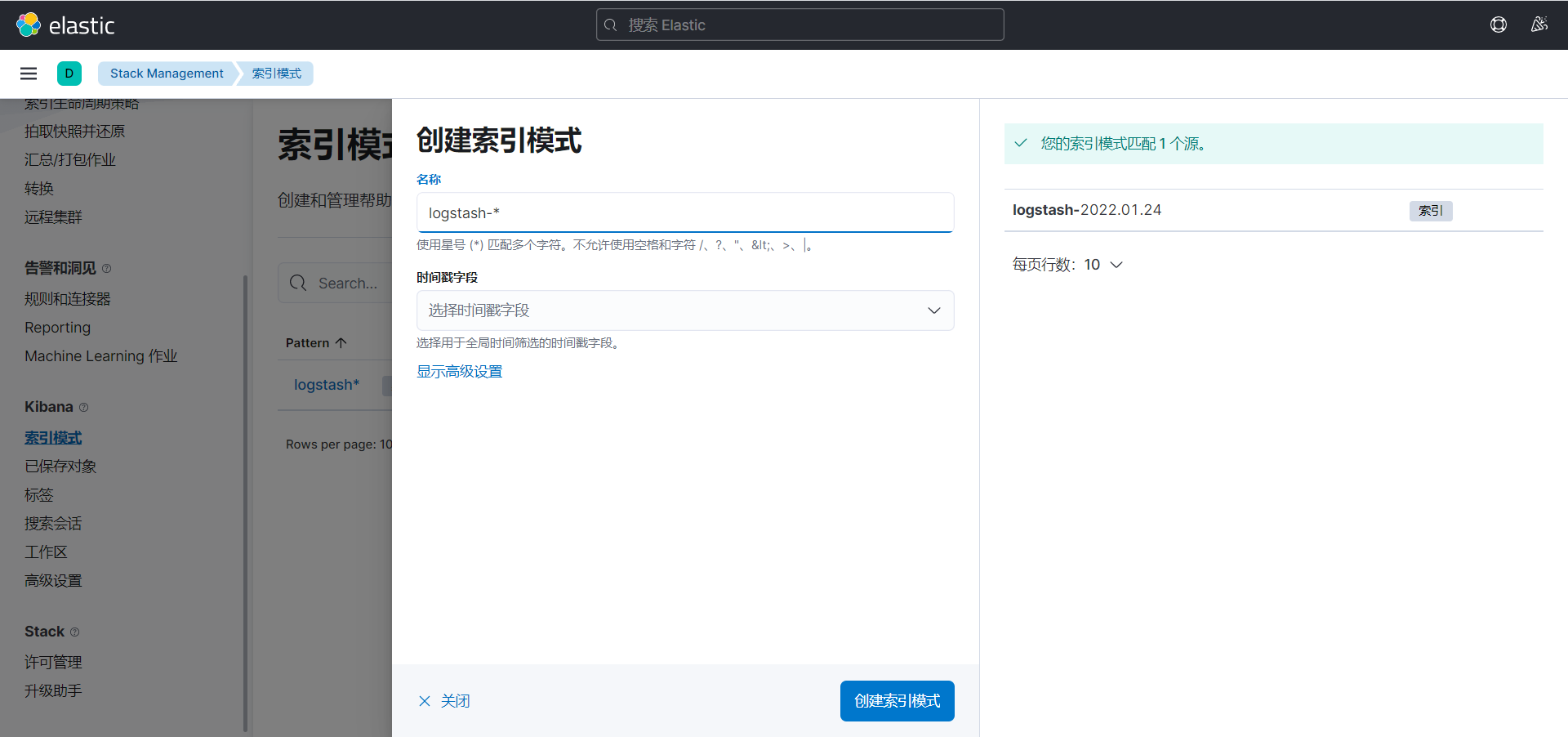
第一次进入可能会让你创建索引模式,可以匹配以有的索引,用于展示内容
配置好之后再次点击侧边栏的discover,查看数据,目前展示的便是刚才闯将的索引模式
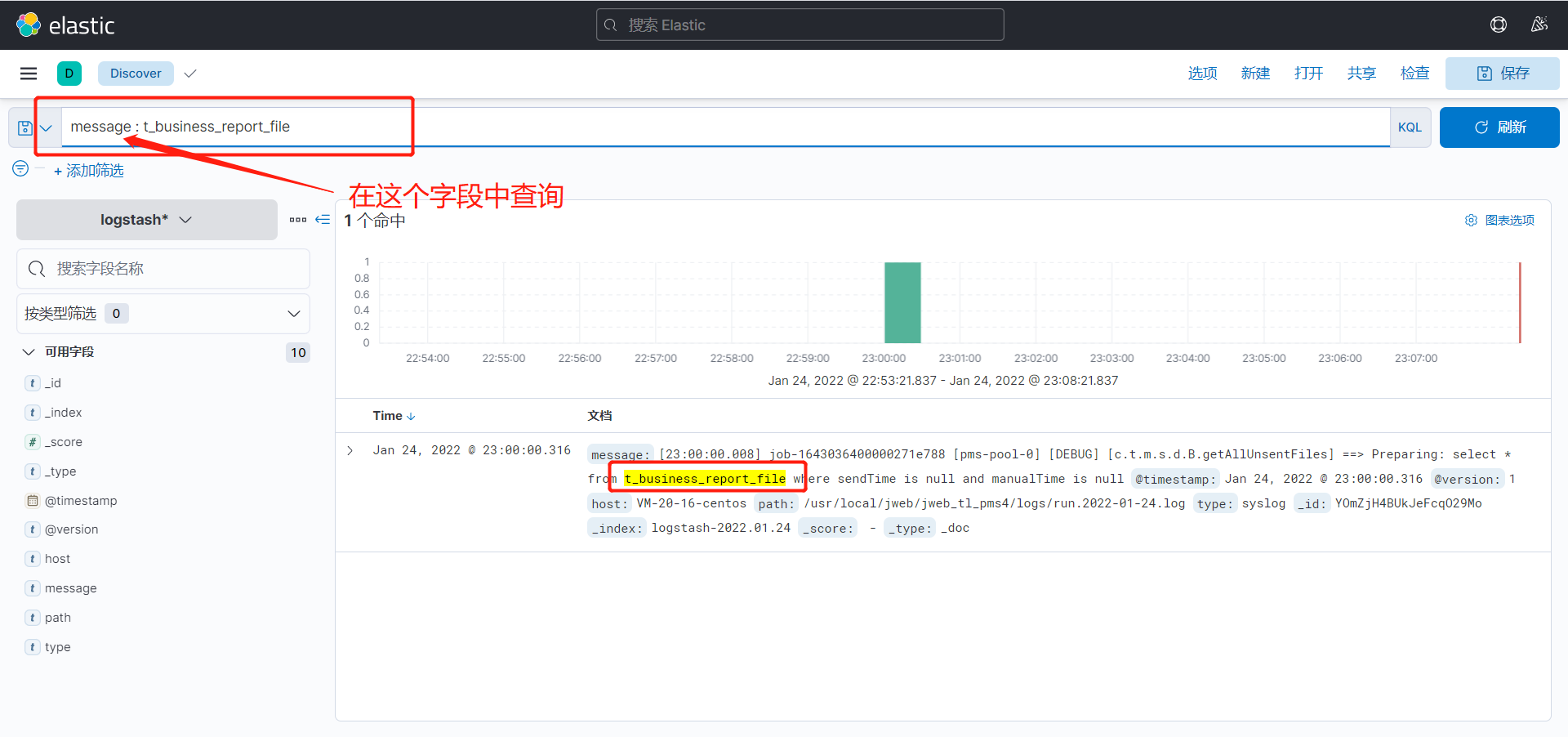
查询日志
日志内容存放在message字段中

可以使用上方的KQL(Kibana Query Language)语句进行查询
2、ES 核心概念
概述
Elasticsearch也是基于Lucene的全文检索库,本质也是存储数据,很多概念与MySQL类似的。
对比关系:
- 索引(indices)———————-Databases 数据库
- 类型(type)————————–Table 数据表 [7.x废弃]
- 文档(Document)———————-Row 行
- 字段(Field)————————-Columns 列
elasticsearch(集群)中可以包含多个索引(数据库),每个索引可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)
物理设计:
es 在后台把每个索引分成多个分片,每个分片可以在集群中的不同服务器间迁移,一个节点就是一个 elasticsearch 进程,节点可以有多个索引默认的,如果你创建索引,那么索引将会有5个分片构成,每个主分片会有一个副本
一个服务就是一个集群,默认的集群名称就是 elasticsearch
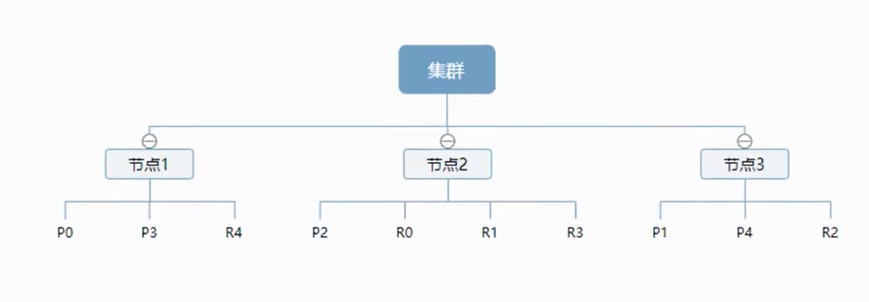
上图是一个有三个节点的集群,主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不会丢失。实际上,一个分片是一个 Lucenne 索引,一个包含倒排索引的文件目录,倒排索引的结构使得 elasticsearch 在不扫描全部文档的情况下,就能高数你哪些文档包含特定的关键字
倒排索引
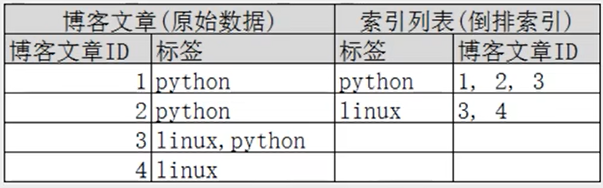
elasticsearch 使用的是一种称为倒排索引的结构,采用 Lucene 倒排索引作为底层,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表,例如
Study every day, good good up to forever # 文档1内容
To forever, study every day, good good up # 文档2内容为了创建倒排索引,我们首先要将每个文档拆分成独立的词,然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:
| term | doc_1 | doc_2 |
|---|---|---|
| Study | √ | x |
| To | x | √ |
| every | √ | √ |
| forever | √ | √ |
| day | √ | √ |
| study | x | √ |
| good | √ | √ |
| to | √ | x |
| up | √ | √ |
现在,我们试图搜索 to forever,只需要查看包含词条的文档
| term | doc_1 | doc_2 |
|---|---|---|
| to | √ | x |
| forever | √ | √ |
| total | 2 | 1 |
两个文档都匹配,但是第一个文档比第二个匹配度更高,如果没有别的条件,现在这两个包含关键字的文档都将返回
在如下,当查询 linux 时,只会查询 3,4 文档,完全过滤掉无关的所有数据,提高效率
3、IK 分词器插件
分词:即把一段中文或者别的词划分成一个个关键字,我们在搜索的时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词
IK 提供了两个分词算法:ik_smart 和 ik_max_word
- ik_smart 为最小切分
- ik_max_word 为最细粒度划分
安装
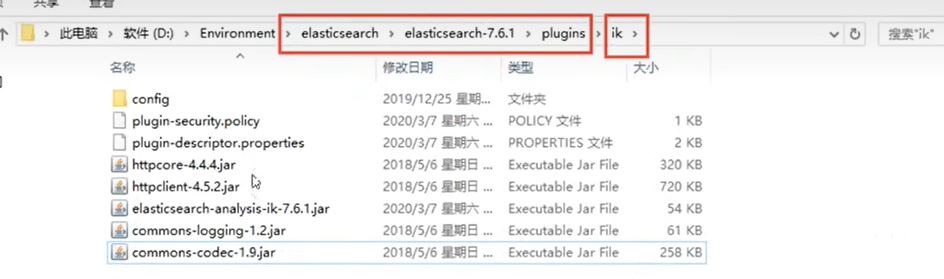
1、地址:https://github.com/medcl/elasticsearch-analysis-ik
2、下载完毕之后,放入到 elasticsearch 插件目录即可
3、重启观察 es

也可以通过命令行查看已安装的插件
elasticsearch-plugin list
4、测试分词器,使用 kinbana 面板输入命令
GET _analyze
{
"analyzer": "ik_smart",
"text": "我是卢晓江"
} 5、修改分词器配置
修改 ik 分词器 config 目录下的 IKAnalyzer.cfg.xml 文件,指定自己的分词文件
新增文件 myWord.dic
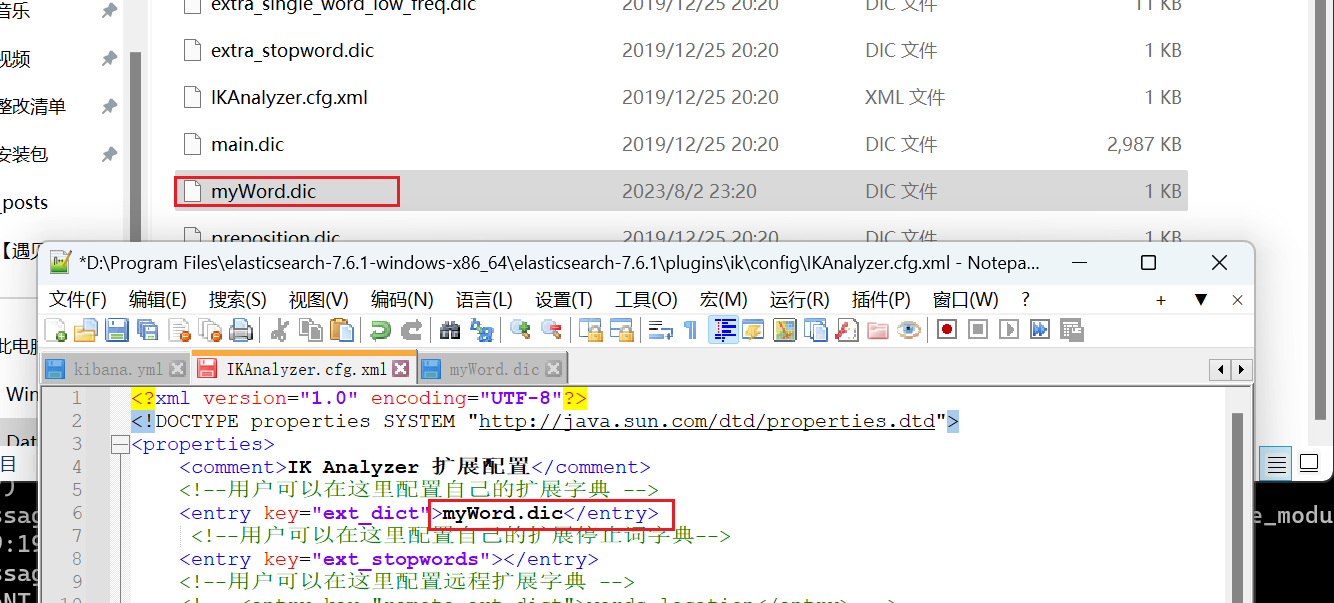
6、重启 es 然后再次测试分词
4、Rest 风格说明
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件,它主要用于客户端和服务器之类的软件,基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引/类型/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引/类型 | 创建文档(随机文档id) |
| POST | localhost:9200/索引/类型/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引/类型/文档id | 删除文档 |
| GET | localhost:9200/索引/类型/文档id | 查询文档通过文档id |
| POST | localhost:9200/索引/类型/_search | 查询所有数据 |
5、索引基础操作
创建索引
直接插入数据也会自动创建索引
PUT /test1/type1/1
{
"name": "晓江",
"age": 3
} 指定索引字段类型
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
} ,
"age": {
"type": "long"
}
}
}
} 通过 GET 请求可以获取索引信息
GET test2拓展:通过命令 elasticsearch 查看索引情况,通过 get _cat/ 可以获取 es 更多信息
GET _cat/indices?v删除索引
所有的文档数据也会被删除
DELETE test16、文档基本操作
创建文档
PUT /test/user/1
{
"name": "张三",
"age": 23,
"tags": ["男", "广州", "程序员"]
}
PUT /test/user/2
{
"name": "李四",
"age": 33,
"tags": ["男", "深圳", "项目经理"]
}
PUT /test/user/3
{
"name": "王五",
"age": 13,
"tags": ["女", "深圳", "学生"]
}
PUT /test/user/4
{
"name": "张三3",
"age": 23,
"tags": ["男", "广州", "程序员"]
} 修改文档数据
通过 put 直接覆盖旧数据,但是每次请求需要携带所有数据,不然会置空
PUT /test/user/1 { "name": "张三", "age": 43, "tags": ["男", "广州", "程序员"] }通过 POST 请求,后缀加上 _update
POST /test/user/1/_update { "name": "张三2" }
获取数据
简单搜索
GET test/user/1指定参数
GET test/user/_search?q=name:张三复杂查询
包含 分页、高亮、排序、模糊查询、精确查询
构建查询
GET test/user/_search
{
"query": {
"match": {
"name": "张三"
}
}
} 查询的结果包含 hits 对象包含:
- 索引和文档的信息
- 查询的结果总数
- 然后就是查询出来的具体文档
- 查询分数
限定查询字段
GET test/user/_search
{
"query": {
"match": {
"name": "张三"
}
} ,
"_source": ["name", "age"]
} 排序
根据年龄排序,指定排序之后不显示分数
GET test/user/_search
{
"query": {
"match": {
"name": "张三"
}
} ,
"sort": [
{
"age": {
"order": "desc"
}
}
]
} 分页查询
- from:从第几条开始
- size:返回多少条数据
GET test/user/_search
{
"query": {
"match": {
"name": "张三"
}
} ,
"from": 0,
"size": 1
} 数据下标是从0开始的
布尔类型
多条件查询:
- must:等价于 and,所有条件都要符合
- should:等价于 or,符合其中一个条件即可
- must_not:等价于 not,查询所有不符合条件的
GET test/user/_search
{
"query": {
"bool": {
"must": [
"match": {
"name": "张三"
} ,
"match": {
"age": 3
}
]
}
}
} 过滤器
filter:进行数据的过滤
- range 表述查询范围,可以使用多个条件
- gt 大于
- gte 大于等于
- lt 小于
- lte 小于等于
GET test/user/_search
{
"query": {
"bool": {
"must": [
"match": {
"name": "张三"
}
],
"filter": {
"range": {
"age": {
"gt": 3,
"lte": 40
}
}
}
}
}
} 匹配多个条件
匹配数组多个数值,只需要用空格隔开就行,只需要满足其中一个结果即可查出
GET test/user/_search
{
"query": {
"match": {
"tags": "男 程序员"
}
}
} 精确查询
term 查询是直接通过倒排索引指定的精确查询
- term 直接查询精确的
- match 会使用分词器解析,先分析文档,然后通过分析的文档查询
注意字段类型:
- keyword:只能精确查询,不拆分
- standard:会分词
GET test/user/_search
{
"query": {
"term": {
"tags": "男 程序员"
}
}
} 高亮查询
highlight:
- pre_tags 指定前缀
- post_tags 指定后缀
- fields 指定高亮字段
GET test/user/_search
{
"query": {
"match": {
"name": "张三"
}
} ,
"highlight": {
"pre_tags": "<p style='color: red'>",
"post_tags": "</p>",
"fields": {
"name": { }
}
}
} 7、springboot集成
官方文档:https://www.elastic.co/guide/index.html

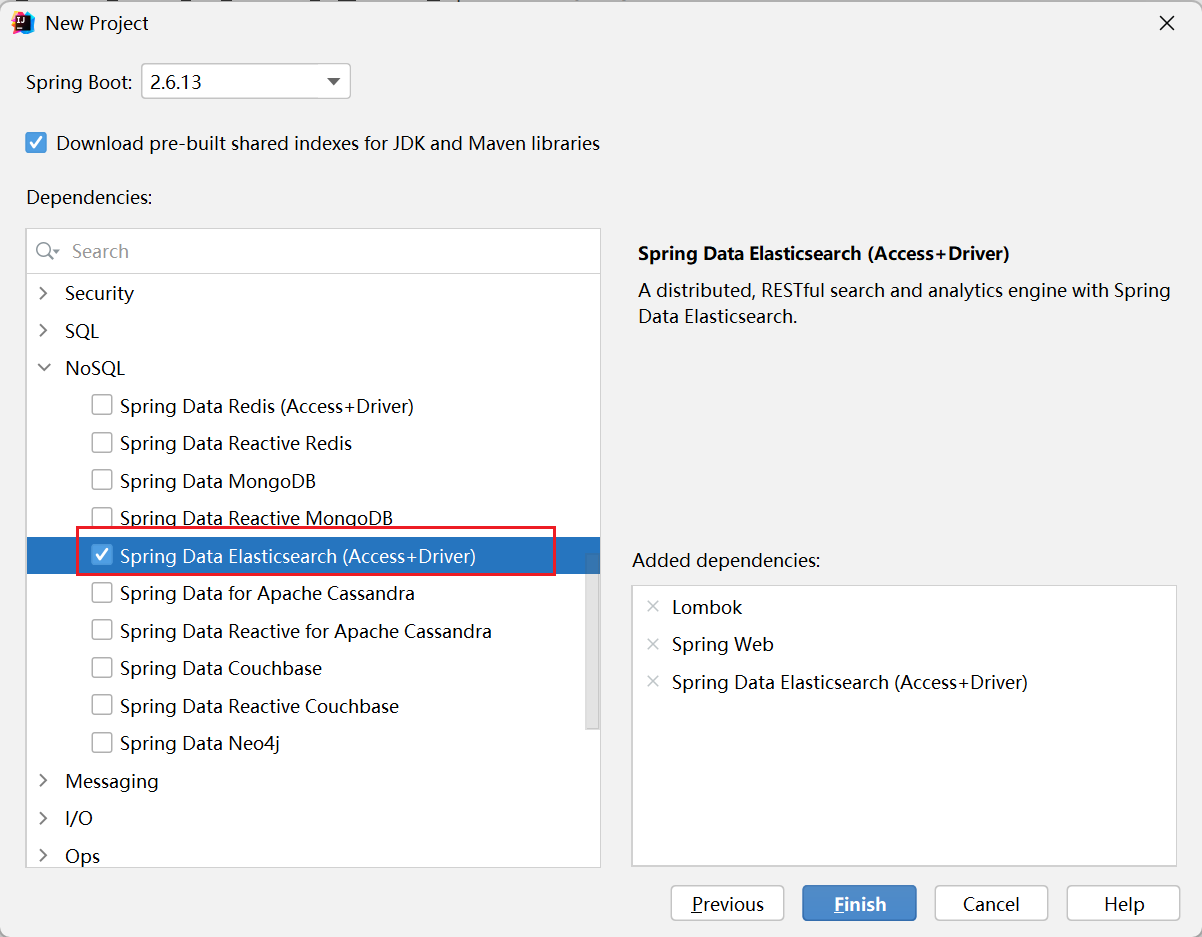
创建项目
记得勾选上 es 依赖
修改 springboot 项目中的 es 版本,与本地安装的版本一致
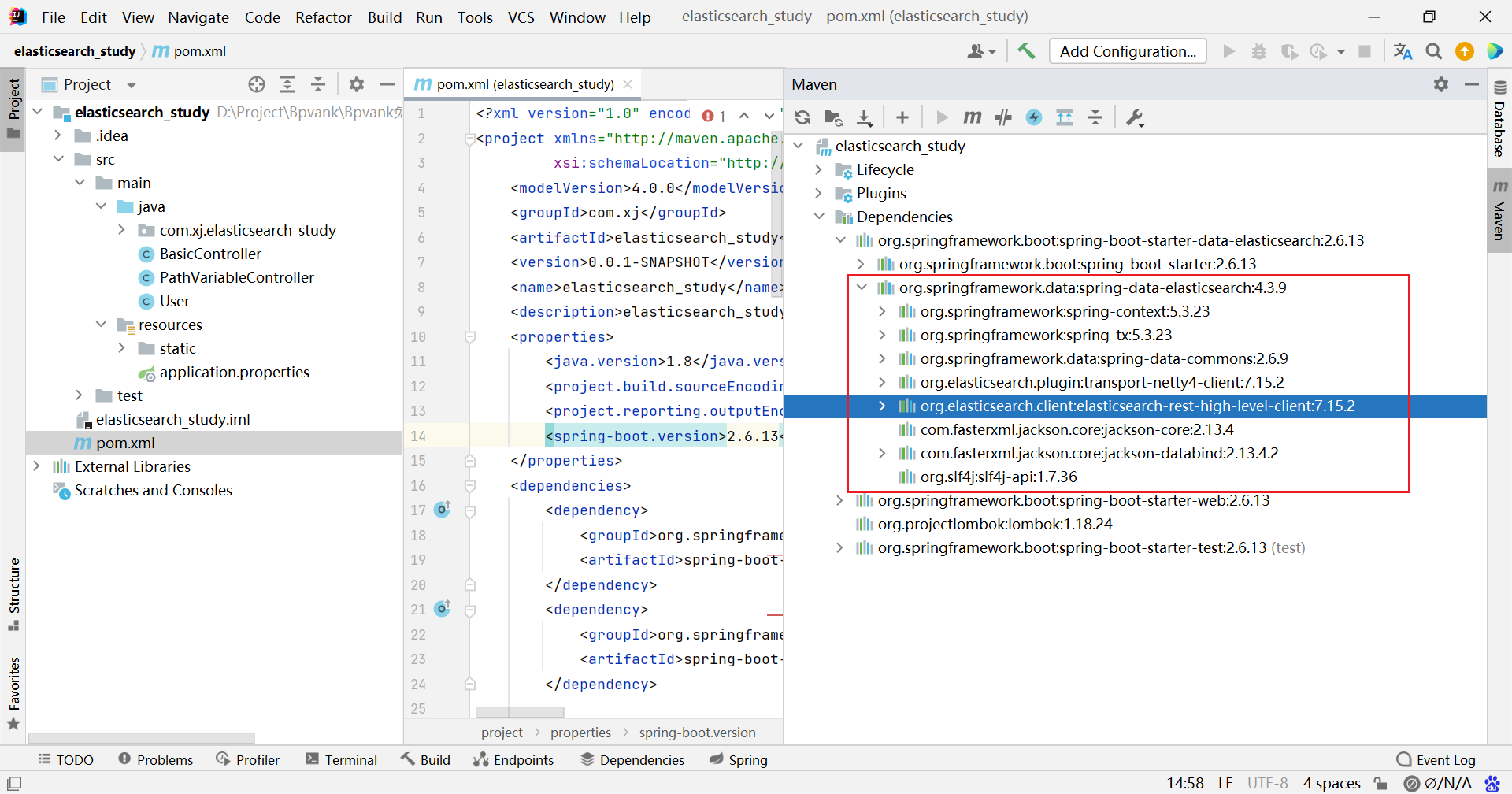
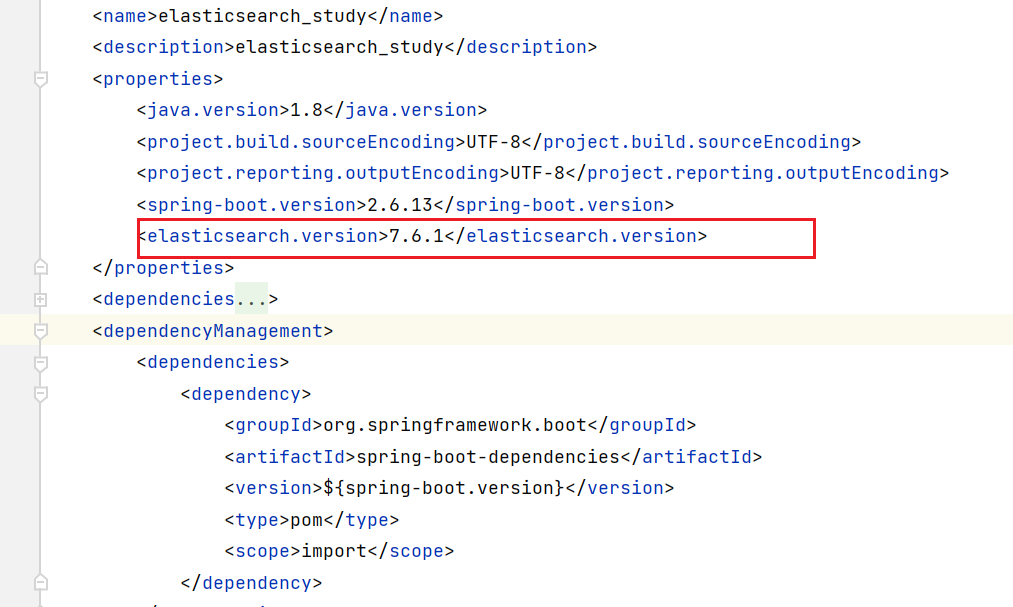
创建配置类
1、创建 ElasticSearchClientConfig 类,使用文档中的创建方式,但是我觉得这种只需要配置在 yml 文件中即可
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
return new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http")));
}
} 
嗯,确实可以在配置文件中指定 ip 和 端口
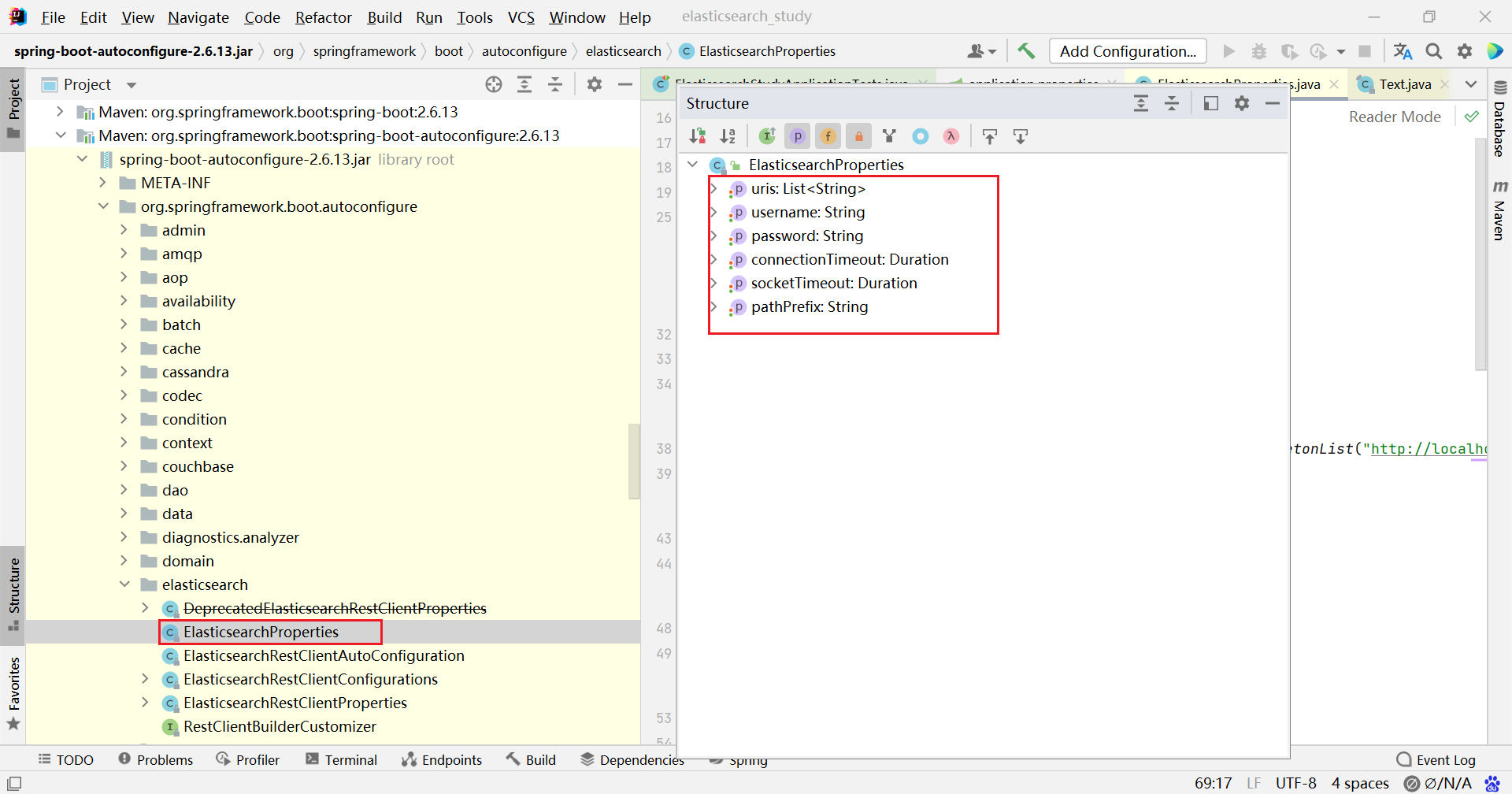
2、查看自动配置的源码,默认 ip 和 端口 为 localhost:9200
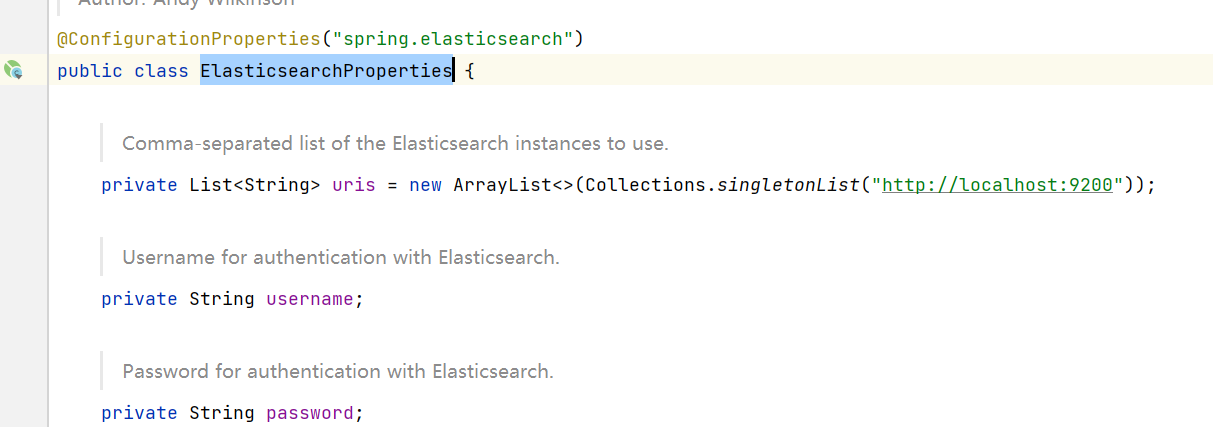
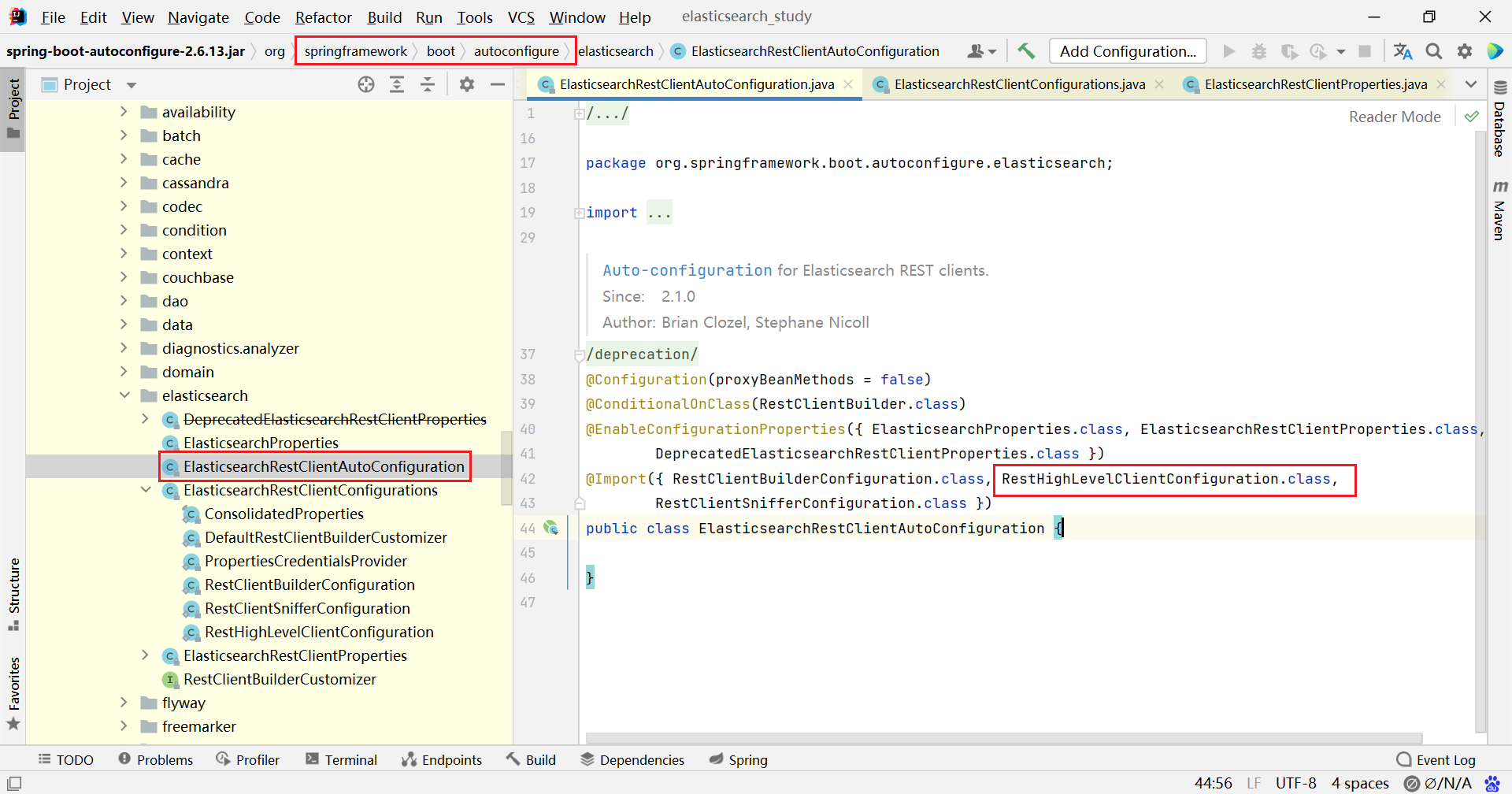
默认生成的 RestHighLevelClient 使用了 RestClientBuilder 进行构建
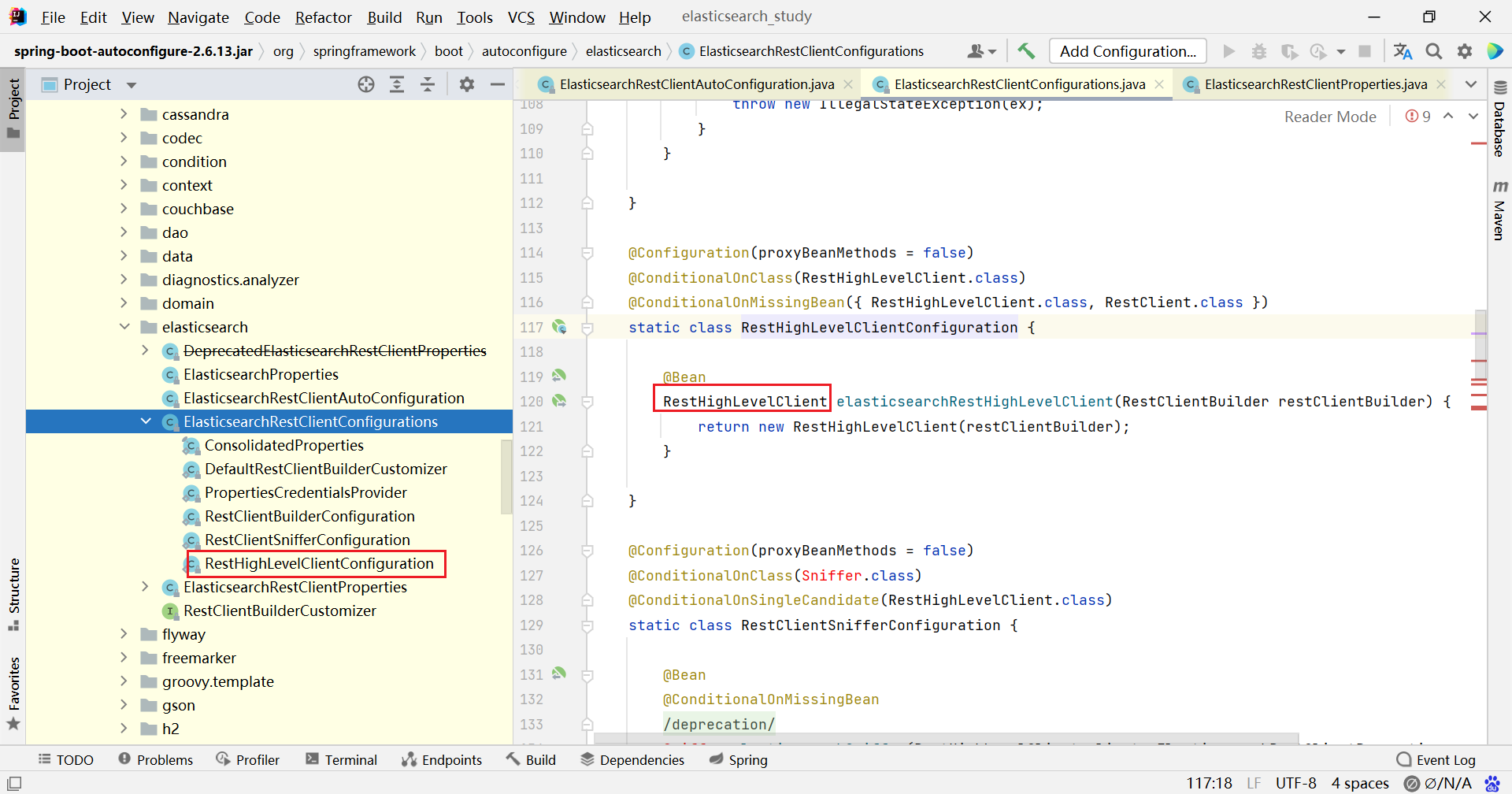
而默认的 RestClientBuilder 中又读取了配置文件的内容,所以直接在 springboot 配置文件指定 uris 也是可以的

索引基本操作
创建索引
@SpringBootTest
class ElasticsearchStudyApplicationTests {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* 创建索引
*/
@Test
void createIndices() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("test");
CreateIndexResponse createIndexResponse = restHighLevelClient.indices()
.create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
} 获取索引
/**
* 获取索引
*/
@Test
void getIndices() throws IOException {
GetIndexRequest request = new GetIndexRequest("test");
GetIndexResponse getIndexResponse = restHighLevelClient.indices()
.get(request, RequestOptions.DEFAULT);
System.out.println(getIndexResponse);
} 删除索引
/**
* 删除索引
*/
@Test
void deleteIndices() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("test");
AcknowledgedResponse delete = restHighLevelClient.indices()
.delete(request, RequestOptions.DEFAULT);
System.out.println(delete);
} 文档基本操作
创建实体类 User,并导入 fastJson,因为请求体都是 json 格式
@Data
@AllArgsConstructor
public class User {
private String name;
private Integer age;
} 创建文档
@Test
void addDocument() throws IOException {
User user = new User("张三", 23);
IndexRequest request = new IndexRequest("user");
// 相当于 put /user/_doc/1
request.id("1");
request.timeout(TimeValue.timeValueMinutes(1));
// 设置请求体
request.source(JSON.toJSONString(user), XContentType.JSON);
// 提交请求
IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT);
System.out.println(response); // 响应结果
System.out.println(response.status()); // 响应状态
} 可以看到 type 类型的设置方法已不建议使用了,默认为 _doc

RequestOptions.DEFAULT 为不需要指定表头

查看文档是否存在
@Test
void checkDocument() throws IOException {
GetRequest request = new GetRequest("user", "1");
// 设置不获取返回的 _source 上下文
request.fetchSourceContext(new FetchSourceContext(false));
request.storedFields("_none_");
// 判断是否存在
boolean exists = restHighLevelClient.exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
} 获取文档内容
@Test
void getDocument() throws IOException {
GetRequest request = new GetRequest("user", "1");
// 查询
GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
} source 包含我们存储的内容
更新文档
@Test
void updateDocument() throws IOException {
UpdateRequest request = new UpdateRequest("user", "1");
// 设置更新内容
User user = new User("李四", 24);
request.doc(JSON.toJSONString(user), XContentType.JSON);
// 更新数据
UpdateResponse response = restHighLevelClient.update(request, RequestOptions.DEFAULT);
System.out.println(response);
} 删除记录
@Test
void deleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("user", "1");
DeleteResponse delete = restHighLevelClient.delete(request, RequestOptions.DEFAULT);
System.out.println(delete);
} 复杂操作
批量插入
@Test
void bulkRequest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
ArrayList<User> list = new ArrayList<User>() { {
add(new User("张三", 1));
add(new User("李四", 2));
add(new User("王五", 3));
} } ;
// 批量创建 indexRequest
for (int i = 0; i < list.size(); i++) {
bulkRequest.add(new IndexRequest("user")
// 不指定则会生成随机 id
.id(String.valueOf(i))
.source(JSON.toJSONString(list.get(i)), XContentType.JSON));
}
// 提交请求
BulkResponse responses = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(responses);
} 复杂查询
使用 match 进行条件查询,除此之外还有命令中存在的查询都可以在 builder 中配置
@Test
void searchDocument() throws IOException {
SearchRequest request = new SearchRequest("user");
// 构造查询器
SearchSourceBuilder builder = new SearchSourceBuilder();
// 构造查询条件
MatchQueryBuilder query = QueryBuilders.matchQuery("name", "张三");
builder.query(query);
// 配置到查询请求中
request.source(builder);
// 提交请求
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
// 获取查询内容
List<Map<String, Object>> list = new ArrayList<>();
for (SearchHit hit : response.getHits().getHits()) {
list.add(hit.getSourceAsMap());
}
System.out.println(list);
} 分页查询
@Test
void searchDocumentPage() throws IOException {
SearchRequest request = new SearchRequest("user");
// 构造查询器
SearchSourceBuilder builder = new SearchSourceBuilder();
// 设置分页
builder.from(0);
builder.size(2);
// 配置到查询请求中
request.source(builder);
// 提交请求
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
// 获取查询内容
List<Map<String, Object>> list = new ArrayList<>();
for (SearchHit hit : response.getHits().getHits()) {
list.add(hit.getSourceAsMap());
}
System.out.println(list);
} 高亮查询
获取到的高亮字段需要手动拼接起来,同时如果要在前端成功显示出高亮的话,需要使用 v-html 标签存放返回的数据
@Test
void searchDocumentHighLight() throws IOException {
SearchRequest request = new SearchRequest("user");
// 构造查询器
SearchSourceBuilder builder = new SearchSourceBuilder();
MatchQueryBuilder query = QueryBuilders.matchQuery("name", "张三");
builder.query(query);
// 设置高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("name");
highlightBuilder.preTags("<span style='color: red'>");
highlightBuilder.postTags("</span>");
highlightBuilder.requireFieldMatch(false); // 取消多个高亮
builder.highlighter(highlightBuilder);
// 配置到查询请求中
request.source(builder);
// 提交请求
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
// 获取查询内容
List<Map<String, Object>> list = new ArrayList<>();
for (SearchHit hit : response.getHits().getHits()) {
// 获取高亮字段
HighlightField name = hit.getHighlightFields().get("name");
if (name != null) {
StringBuilder sb = new StringBuilder();
for (Text fragment : name.getFragments()) {
sb.append(fragment);
}
hit.getSourceAsMap().put("name", sb);
}
list.add(hit.getSourceAsMap());
}
System.out.println(list);
} 除以上以外,SearchSourceBuilder 和 QueryBuilders 还有很多属性可以配置,实现命令行中的所有操作,剩下的就等用到了再来测试吧~
- 本文链接:https://lxjblog.gitee.io/2023/08/03/elasticsearch%E5%9F%BA%E6%9C%AC%E4%BD%BF%E7%94%A8/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。